一、配置kibana
1.1 kibana概述
1.1.1 什么是kibana
kibana是一款数据可视化的工具
1.1.2 kibana特点
1.灵活的分析和可视化平台
2.实时总结和流数据的图表
3. 为不同的用户显示直观的界面
4. 即时分享和嵌入的仪表板
1.2 部署Kibana
1.安装kibana
~] # rpm –ivh kibana-4.5.2-1.x86_64.rpm
2. 修改配置文件
~] # vim /opt/kibana/config/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.url: "http://es1:9200" //只需要改这一行就可以了,指定elasticsearch集群中任意一台机器地址就可以了
kibana.index: ".kibana"
kibana.defaultAppId: "discover"
elasticsearch.pingTimeout: 1500
elasticsearch.requestTimeout: 30000
elasticsearch.startupTimeout: 5000
3.启动服务
~] # systemctl start kibana
4.测试kibana服务
~]# ss -antulp | grep 5601
http://192.168.5.16:5601/ //浏览器访问kibana主页
1.3 批量导入数据
1.3.1 使用 _bulk 批量导入数据
批量导入数据使用 POST 方式,数据格式为 json,url编码使用 data-binary
1.导入含有 index 配置的 json 文件
curl -XPOST http://192.168.1.13:9200/_bulk --data-binary @shakespeare.json
2.导入无 index, type 配置的json文件 【没有索引和类型的需要自己指定索引和类型】
curl -XPOST http://192.168.1.13:9200/accounts/act/_bulk --data-binary @accounts.json
3.有 多个index,type 无 id 的导入
curl -XPOST http://192.168.1.13:9200/_bulk --data-binary @logs.jsonl
1.4 数据批量查询
1.4.1 数据批量查询使用 GET
curl -XGET http://192.168.5.12:9200/_mget?pretty -d '
{
docs:[
{"_index": "oo",
"_type": "xx",
"_id": 99
},
{
"_index": "accounts",
"_type:": "act",
"_id": 2
},
{
"_index": "shakespeare",
"_type:": "scene",
"_id": 1
}
]
}'
1.5 验证ES是否和kibana连接成功
修改 kibana 的配置文件后启动 kibana,然后查看
ES 集群,如果出现 .kibana Index 表示 kibana 与
ES 集群连接成功

二、logstash概述
2.1 什么是logstash
logstash是一个数据采集、加工处理以及传输的工具
2.2 ELK工作结构模型
| 数据源 | --->| INPUT | -->| FILTER | --> | OUTPUT | ---> | ES 集群 | -->| KIBANA |
2.3 logstash 安装
1. Logstash 依赖 java 环境,需要安装 java-1.8.0-openjdk,再安装logstash软件包
]# yum -y install java-1.8.0-openjdk
]# rpm -ivh logstash-2.3.4-1.noarch.rpm
2.Logstash默认没有配置文件,需要手动写一个logstash.conf
] # vim /etc/logstash/logstash.conf
input{
stdin{ codec => "json" } //logstash-input-stdin标准输入插件
}
filter{ }
output{
stdout{ codec => "rubydebug" } //logstash-output-stdout标准输出插件
}3.启动服务并验证
]# logstash -f logstash.conf
直接在启动终端输入就JSON数据{"name":"zhang","sex":"boy"}
就会输出rubydebug编码的数据

2.4 logstash常用插件
插件文档地址
https://www.elastic.co/guide/en/logstash/current/index.html
2.4.1 input file 插件
1.sincedb_path 记录读取文件的位置
2. start_position 配置第一次读取文件从什么地方开始
file {
path => ["/tmp/a.log"]
sincedb_path => "/var/log/logstash/sincedb.log"
#sincedb_path => "/dev/null"
start_position => "beginning"
type => "logstash1_file_log"
}
如果不是第一次接触sincedb.log文件,应该先删除sincedb.log。 start_position => "beginning"选项才会生效
2.4.2 TCP/UDP插件
~] # vim /etc/logstash/logstash.conf
tcp{
host => "0.0.0.0"
port => 8888
type => "tcplog"
}
udp{
host => "192.168.4.16"
port => 9999
type => "udplog"
}
]# echo "test udp log" >/dev/udp/192.168.5.17/6666
]# echo "test udp log" >/dev/udp/192.168.1.20/8888
2.4.3 syslog 插件
~] # vim /etc/logstash/logstash.conf
input {
... ...
syslog {
port => 514
type => "syslog"
}
}
1.客户机配置 @@(tcp) @(udp)
local0.info @@192.168.1.20:514 //写要发送日志到服务器的地址
2.测试配置
logger -p local0.info -t "testlog" "hello world"
2.4.4 filter grok插件
1. filter grok插件的作用
1.1 解析各种非结构化的日志数据插件
1.2 grok 使用正则表达式把非结构化的数据结构化
1.3 在分组匹配,正则表达式需要根据具体数据结构编写
1.4 虽然编写困难,但适用性极广, 几乎可以应用于各类数据
2. 正则表达式分组匹配 (?<name>reg)
2.1 正则宏路径
/opt/logstash/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-2.0.5/patterns
2.2 使用logstash的COMBINEDAPACHELOG模板匹配http日志信息,并给对应字段赋值
~] # /etc/logstash/logstash.conf
filter{
grok{
match => ["message", "%{COMBINEDAPACHELOG}"]
}
}
3.匹配后结果如下:
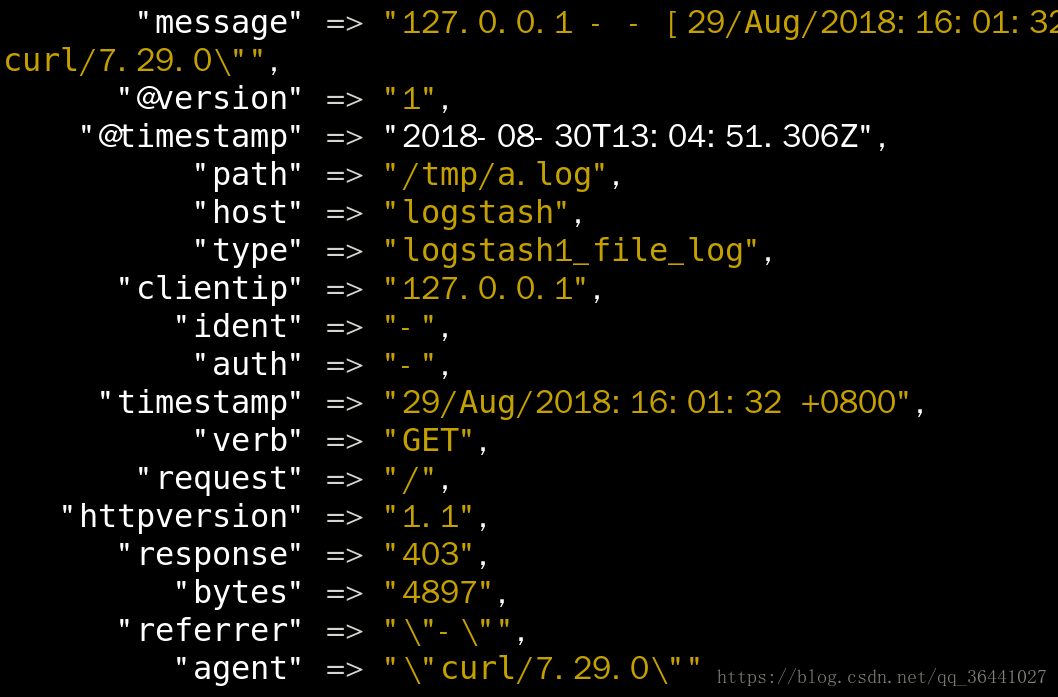
2.4.5 filebeats 插件
1.修改logstash beats 配置
~] # /etc/logstash/logstash.conf
input{
... ...
beats{
port => 5044 //这个端口是用来接收客户端filebeat软件发送日志的
}
}
2.filebeat软件可以帮我们把客户端的日志信息传给指定的logstash服务器,所以需要在客户端安装filebeat
~ ] #yum -y install filebeat
3.修改filebeat.yml配置文件
~]# egrep -v '(^$|^#|^\s*#)' /etc/filebeat/filebeat.yml
filebeat:
prospectors:
-
paths:
- /var/log/httpd/access_log //指定需要发送给logstash的日志文件
input_type: log
document_type: apachelog //指定日志类型
registry_file: /var/lib/filebeat/registry
output:
#elasticsearch://不让客户端的日志直接输入到elasticsearch分布式存储数据,因为需要经过logstash处理才能传给elasticsearch
# hosts: ["localhost:9200"]
logstash:
hosts: ["192.168.5.17:5044"] //指定远程logstash的IP地址和端口
shipper:
logging:
files:
rotateeverybytes: 10485760 # = 10MB4.启动filebeat服务验证
~ ] #systemctl start filebeat
~ ] # curl 0.0.0.0 //访问本机的http服务,就会有日志写入/var/log/httpd/access_log文件,日志文件里面的数据就会
传送给远程的logstash进行filter的grok插件进行处理,这个步骤就可以实现客户端的日志文件动态传给logstash
2.4.6 output elasticsearch 插件
1.修改logstash.conf配置文件
~] # /etc/logstash/logstash.conf
output{
stdout{ codec => "rubydebug" }
if [type] == "apachelog"{
elasticsearch { //logstash将处理之后的信息传给kibana
hosts => ["192.168.1.11:9200", "192.168.1.12:9200"]
index => "weblog"
flush_size => 2000
idle_flush_time => 10
}}
}
2.访问http://192.168.5.16:5601 kibana主页进行数据查看

附:logstash日志处理的主配置文件:logstash.conf