import requests
import json
from lxml import etree
import time
for i in range(5):
page_start=str(i*20)
url='https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start='+page_start
headers = {''
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
response =requests.get(url,headers=headers,verify=False)
content = response .content.decode()
content_list =json.loads(content)['subjects']
time.sleep(2)
for div in content_list:
rate=div["rate"]
title=div["title"]
url=div["url"]
cover=div["cover"]
print("{},\t{},\t{},\t{}\n".format(title,rate,cover,url))
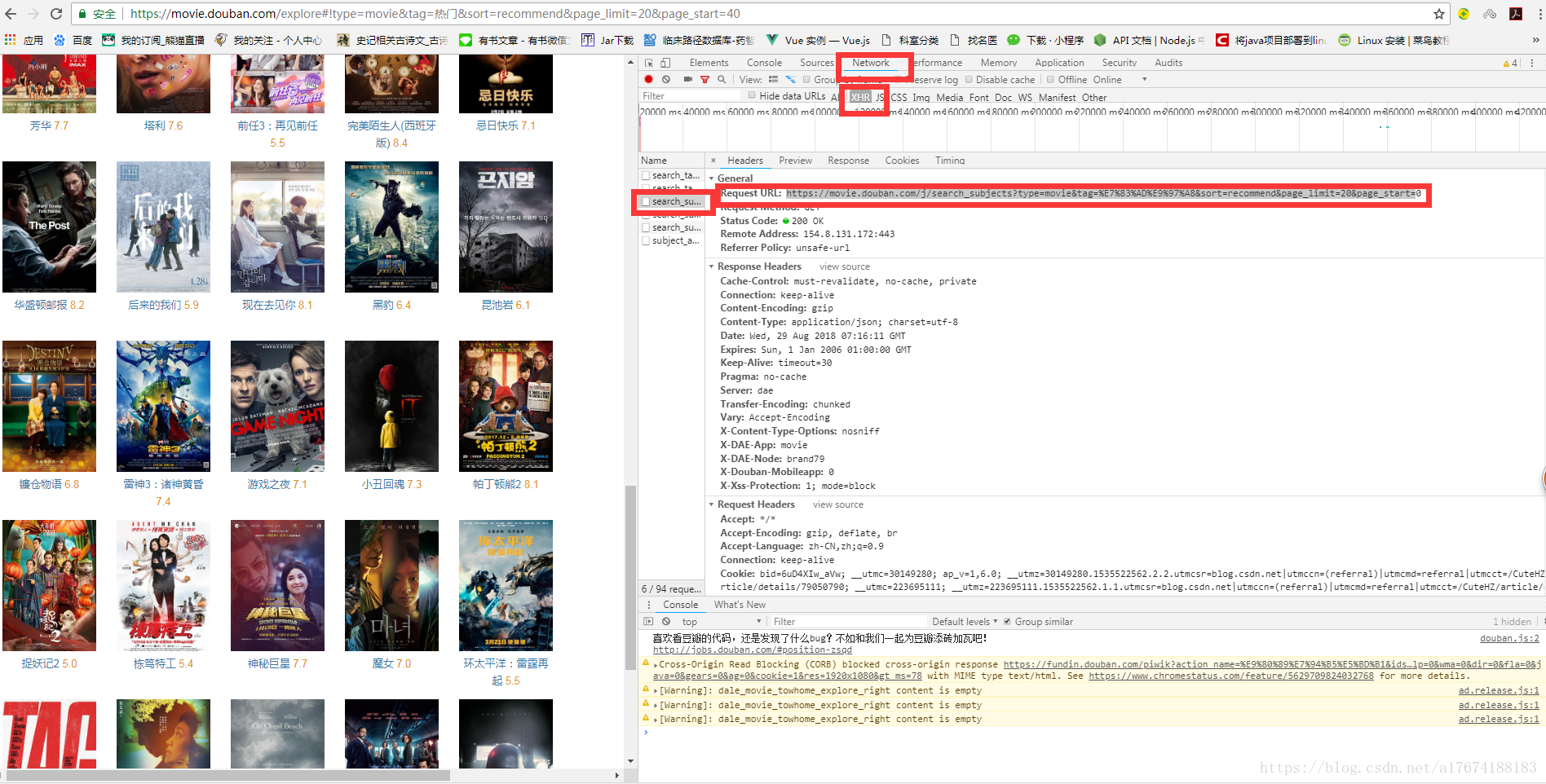
上图为参数URL获取方式

上图为headers获取方式,动态网页如果没有headers 好像是读取不到数据的。
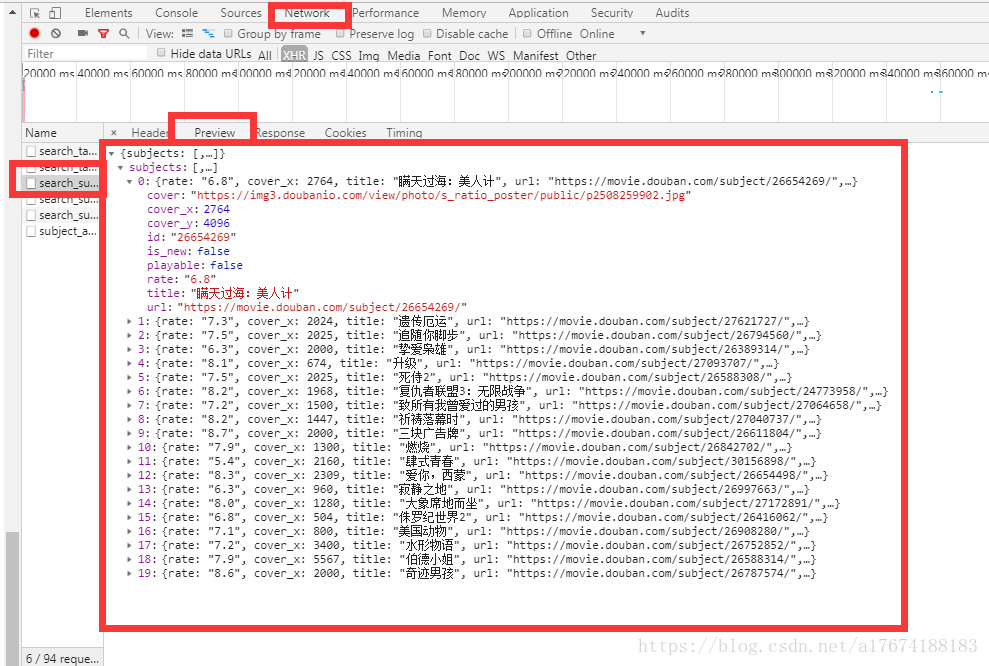
可以看到数据存放在subjects,所以我们解析它就可以得到我们想要的数据。