编写简单高效的yara规则(3)
翻译自:https://www.bsk-consulting.de/2016/04/15/how-to-write-simple-but-sound-yara-rules-part-3/
距离我写How to Write Simple but Sound Yara Rules – Part2 已经有一段时间了。从那之后,我改进了我的规则创建方法,新方法生成的规则更具通用性,并且新版yarGen还添加了内存检测功能。
Binarly
新版yarGen集成了Binarly API
Binarly是一个“二进制搜索引擎”,可以在数千万个样本中搜索出用户指定的字节码。 它可以解答你如下问题:
- 还有哪些包含这个字节码/字符串?
2.这个字节码/字符串还存在哪些恶意软件和合法软件中
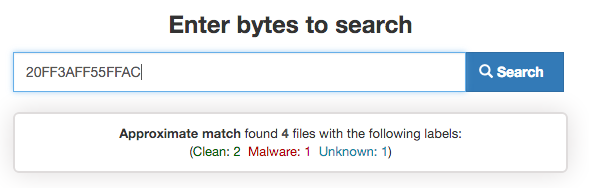
这意味着您可以使用Binarly快速验证YARA字符串的质量。
此外,Binarly还有文件系统搜索功能,只要给定一个目录,它就会递归地去搜索,它可以在一分钟之内匹配7,500,000+个PE文件
Binarly API地址:https://github.com/binarlyhq/binarly-sdk
在使用它之前,您需要一个API密钥,您可以通过[email protected]与他们联系,他们也正在寻找对测试服务感兴趣的研究人员。每个用户限制每天只能发出10,000个请求,但这已经足够了,生成规则时,一个样本大概只发出50到500个请求。
以下屏幕截图显示了,yarGen调试模式下,Binarly的返回结果。你可以看到一些字符串产得到了很高的分数。这个分数被添加到总分中(这决定了这个字符串是否可以被添加到总的YARA规则中去)。Binarly计算分数的方法很复杂。例如,我需要对3000多个恶意软件匹配和1000个合法软件匹配进行评分。合法软件匹配权重更大。一个字符串匹配到了15,000+个恶意软件,但如果它也同时也匹配上了1000个合法软件,那么它的得分将不会很高。我自己也收集了一个Binarly评分很高的规则组

强化规则生成的方法
正如我以前的文章中所描述的,我一般会将由yarGen生成的字符串分成两个组:
- 特殊性字符串:C&C服务器、互斥锁名、PDB文件名、文件名、错别字名…..
- 可疑字符串:这些字符串看起来很可疑,但它们同时也可能出现在合法软件中
在yarGen0.15及更早版本,默认总是将这些字符串与magic头标识和文件大小结合起来形成规则。 这些规则的问题是,它们检测不到处在内存中的恶意软件。
于是我改变了我的规则生成方法,正如我之前所说的,yarGen并不是为了生成完美的规则而设计的。其主要目的是生成初步的规则,让后续的人工修改尽可能的少。
下图显示了如何组成新规则。 它们包含两个主要条件,一个用于文件检测,另一个用于内存检测。

磁盘检测的语句由magic头标识、文件大小和字符串逻辑语句组合在一起。
内存检测则去掉了magic头标识和文件大小检测。
新版本yarGen生成的规则更加严谨。