编写简单高效的yara规则(2)
翻译自:https://www.bsk-consulting.de/2015/10/17/how-to-write-simple-but-sound-yara-rules-part-2/
几个月前,我写了一篇”How to write simple but sound Yara rules“的博客。那篇博客所提到的技术和工具现在以及得到了改进,现在我就来详细地介绍下更新的地方。
万能的Location
Yara最被低估的特征之一是可以定义一个字符串的范围来匹配。 我使用这种技术来创建一个规则,发现它能可靠地检测meterpreter的payload,即使它被编码/隐藏。
当你发现一段恶意代码处在一个可执行文件的末尾时,你应该会有如下疑问:
- 这些字符串位于文件中的这个位置是正常的吗?
- 这些字符串在该文件中多次出现是否正常?
- 两个字符串之间的距离是不是固定的?
这时我提供一种写规则的思路,对于那些非specific字符串,尝试定义一个制定filesize(例如文件大小> 800KB)的规则以及非spcific字符串位置的规则(如$s1 in (filesize-500..filesize))
下面是一个webshell的例子,如果我们使用$code = "7T2JX...." 来作为特征,那么此webshell的作者只需在后续的版本中替换掉$code 或7T2JX...... 便可绕过我们的规则。

所以我们决定将eval(gzinflate(base64_decode(" 作为特征:
rule Webshell_b374k_related_1 {
meta:
description = "Detects b374k related webshell"
author = "Florian Roth"
reference = "https://goo.gl/ZuzV2S"
score = 65
hash = "d5696b32d32177cf70eaaa5a28d1c5823526d87e20d3c62b747517c6d41656f7"
date = "2015-10-17"
strings:
$m1 = "<?php"
$s1 = "@eval(gzinflate(base64_decode(" ascii
condition:
$m1 at 0 and $s1 in (filesize-50..filesize) and filesize < 20KB
}这样的规则看起来适应性就更强
yarGen
更新之后,yarGen具有opcode功能。 它在默认情况下处于启动状态,但仅在没有足够的字符串可以提取的情况下才有有效果。
python yarGen.py --noop -z 0 -a "Florian Roth" -r "http://link-to-sample" /mal/malwareopcode功能的弊端是在创建规则时需要占用多于2.5 GB的内存。 我将在下一个版本中将其更改为可选参数。
yarAnalyzer
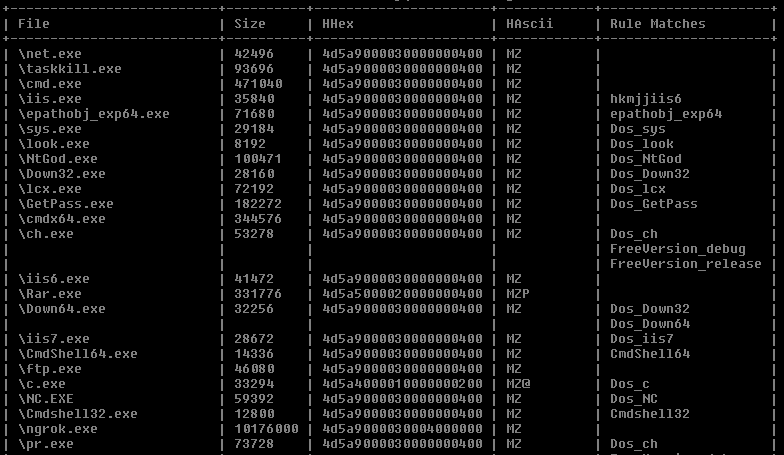
yarAnalyzer是我推出的又一个强大的工具,专注于分析规则的通用性。 在创建了一个大的规则集或一个通用型的规则后,你想检查这些规则的通用性如何,便可以使用这款工具,yarAnalyzer则会输出以下结果:

- 检测到一个以上样本的规则
- 被多条规则检测到的样本
- 没有检测到样本的规则
- 没有被检测到的样本
字符串提取和可视化
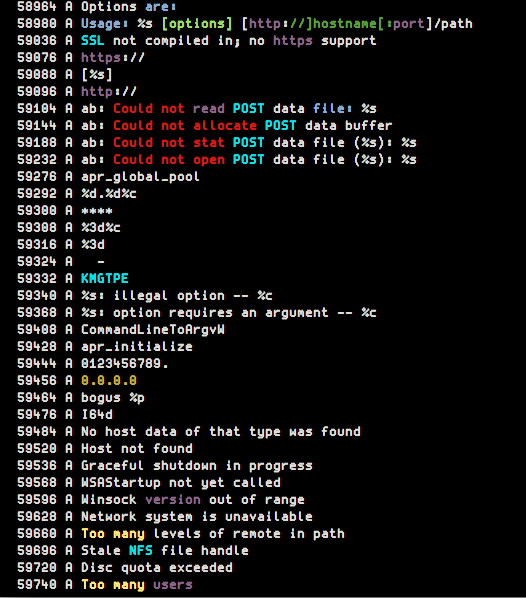
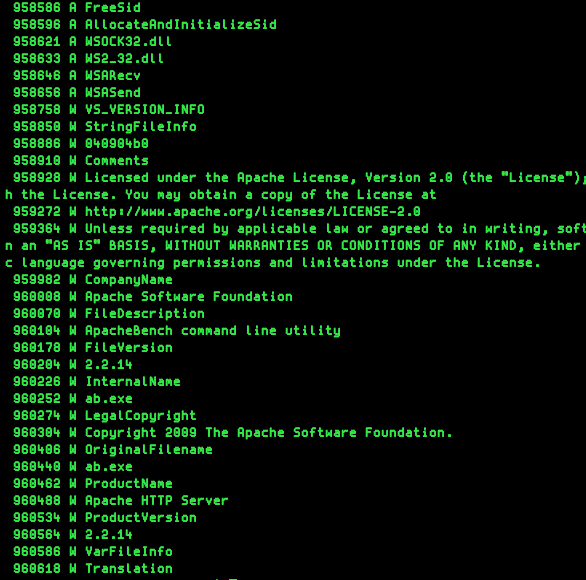
使用如下shell可以更清晰地查看特征字符串:
#!/bin/bash
(strings -a -td "$@" | sed 's/^\(\s*[0-9][0-9]*\) \(.*\)$/\1 A \2/' ; strings -a -td -el "$@" | sed 's/^\(\s*[0-9][0-9]*\) \(.*\)$/\1 W \2/') | sort -n将返回字符串的偏移以及描述(ASCII/UNICODE)
顺便也安利下我新推出的字符串检索工具:prisma