版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u013555719/article/details/82153745
5.2自然语言处理
觉得有用的话,欢迎一起讨论相互学习~Follow Me
2.3词嵌入的特性 properties of word embedding
Mikolov T, Yih W T, Zweig G. Linguistic regularities in continuous space word representations[J]. In HLT-NAACL, 2013.
- 词嵌入可以用来解决类比推理问题(reasonable analogies)
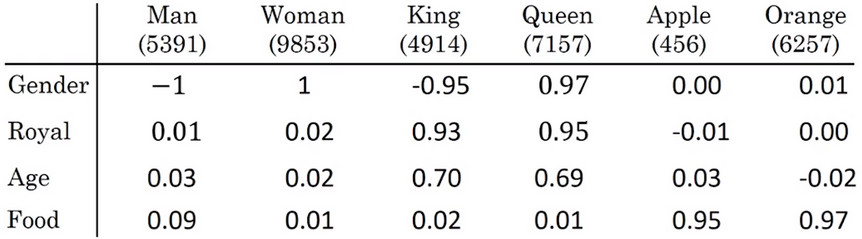
- man 如果对应woman,此时左方输入单词king,能否有一种算法能自动推导出右边的单词(queen)呢?
- 使用词嵌入表示方法,即Man表示为 ,Woman表示为 ,将两个单词相减得 , ,根据向量表示man和woman的主要差异在性别Gender上,而king和queen的主要差异也是在Gender上。
在做类比推理的任务时:
- 首先计算 的值
- 然后计算 集合
- 再取 集合中和 值最接近的那个值,认为是King类比推理后的结果。
-
-
在300D的数据中,寻找的平行的向量如图所示:
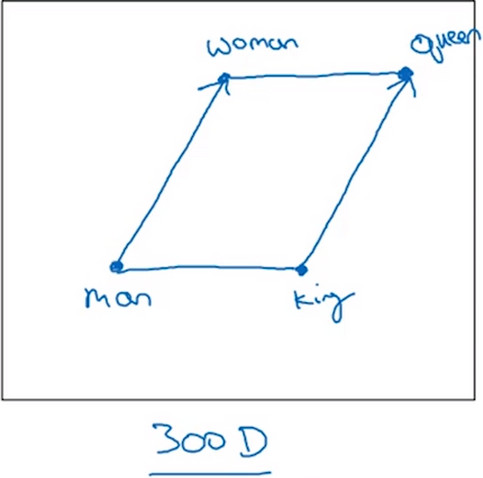
- 但是经过t-SNE后,高维数据被映射到2维空间,则此时寻找平行向量的方法不再适用于这种情况。
余弦相似度 (Cosine similarity)
* 其中二范数即 是把向量中的所有元素求平方和再开平方根。
* 而分子是两个向量求内积,如果两个向量十分接近,则内积会越大。
* 得到的结果其实是两个向量的夹角的cos值
2.4嵌入矩阵 Embedding matrix
- 模型在学习词嵌入时,实际上是在学习一个词嵌入矩阵(Embedding matrix),假设词典中含有1W个单词。300个不同的特征,则特征矩阵是一个300*1W大小的矩阵。
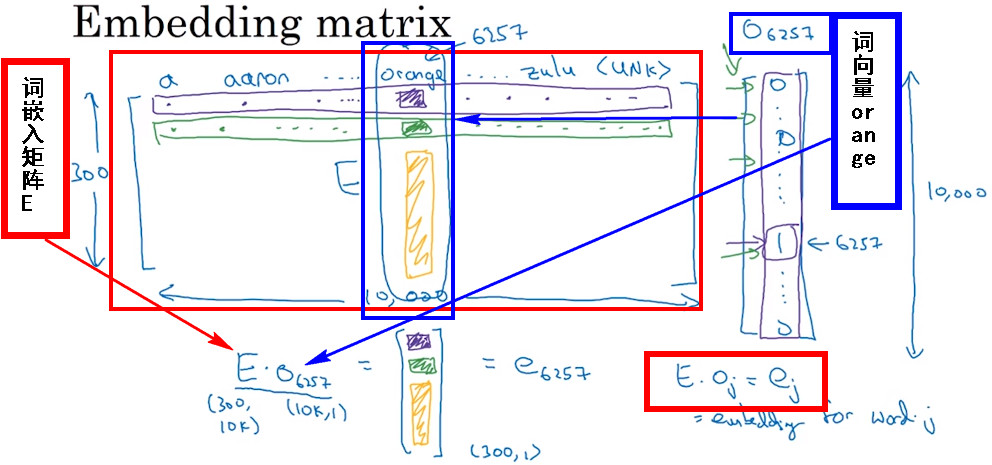
Note
- 在实际应用中,使用词嵌入矩阵和词向量相乘的方法所需计算量很大,因为词向量是一个维度很高的向量,并且10000的维度中仅仅有一行的值是0,直接使用矩阵相乘的方法计算效率是十分低下。
- 所以在实际应用中,会用一个查找函数单独查找矩阵E的某列。 例如在Keras中,就会设置一个Embedding layer提取矩阵中特定的需要的列,而不是很慢很复杂的使用乘法运算
2.5学习词嵌入 learning word embedding
- 本节介绍使用深度学习来学习词嵌入的算法。
Bengio Y, Vincent P, Janvin C. A neural probabilistic language model[J]. Journal of Machine Learning Research, 2003, 3(6):1137-1155.

- 对于语句 I want a glass of orange juice to go along with my cereal.
- 对于之前的方法中,使用juice 前的四个单词 “a glass of orange ”来进行预测。
- 也可以使用 目标单词前后的四个词 进行预测
- 当然也可以只把 目标单词前的一个词输入模型
- 使用相近的一个词
总结
- 研究者们发现 如果你想建立一个语言模型,用目标词的前几个单词作为上下文是常见做法
- 但如果你的目标是学习词嵌入,使用以上提出的四种方法也能很好的学习词嵌入。