Zookeeper简介
什么是zookeeper?
zookeeper是一个是分布式的注册中心。是一个分布式的,开放源码的分布式应用程序协调服务, 它是由Google的Chubby一个开源的实现,现已开源,http://zookeeper.apache.org/中可以查看到基本信息。它是集群的管理者,监视着集群中各个节点的状态根据节点提交的反馈进行下一步合理操作。最终,将简单易用的接口和性能高效、功能稳定的系统提供给用户。它实现诸如数据发布/订阅、负载均衡、命名服务、分布式协 调/通知、集群管理、Master 选举、配置维护,名字服务、分布式同步、分布式锁和分布式队列 等功能。
注意:
本文章使用的是Centos7的系统,使用的Zookeeper版本为 zookeeper-3.4.13.tar.gz。搭建项目之前必须需关闭防火墙,或者指定暴露端口。
systemctl stop firewalld
systemctl disable firewalld
单机实战
1.1下载
首先,我们需要下载使用的包,
进入要下载的版本的目录,选择.tar.gz文件下载
下载链接:http://archive.apache.org/dist/zookeeper/
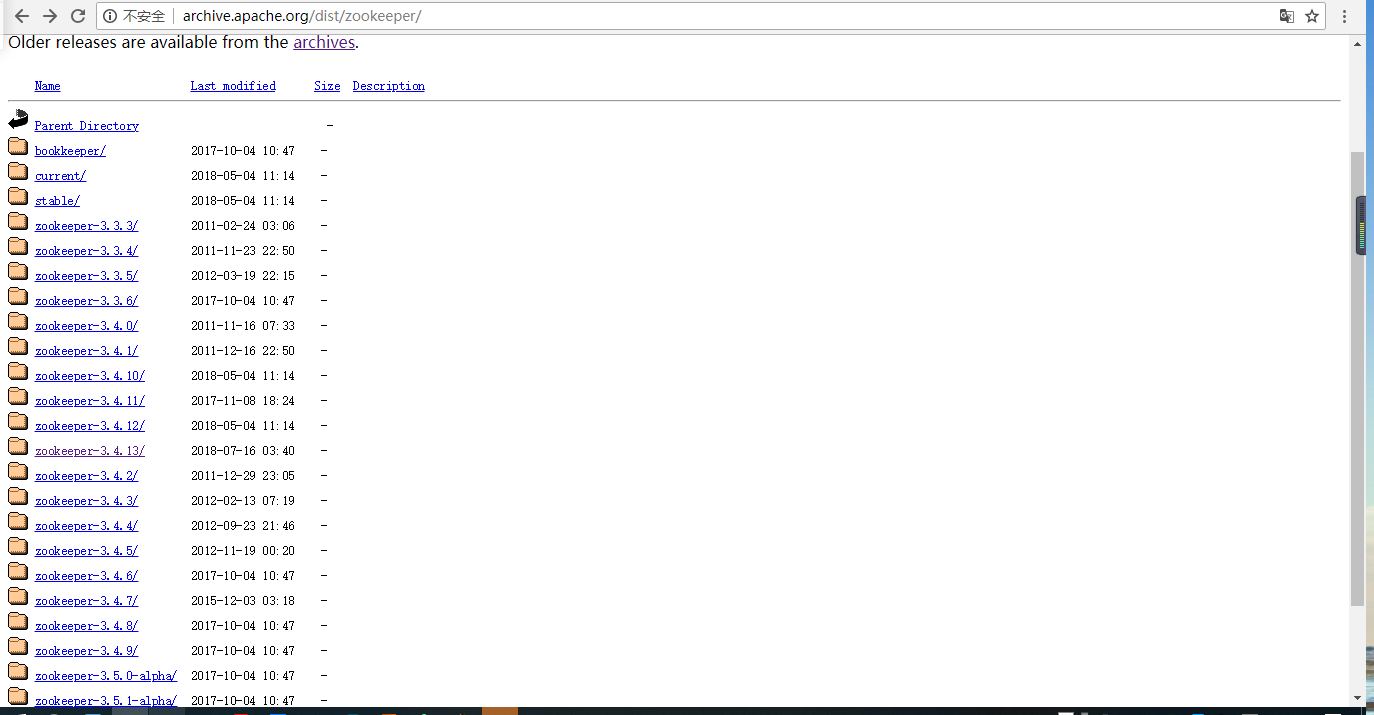
下载最新版本,如果
wget http://archive.apache.org/dist/zookeeper/zookeeper-3.4.13/zookeeper-3.4.13.tar.gz
如果出现下列情况,则需要安装 wget , 如果直接将文件下载,则不需要安装 wget.或者使用FTP文件直接将已下载的包上传至当前服务器。

$ yum -y install wget
$ wget http://archive.apache.org/dist/zookeeper/zookeeper-3.4.13/zookeeper-3.4.13.tar.gz

当前文件已下载至当前目录当中。
1.2安装
先解压文件,然后再将文件移至目录当中。/usr/lib/
$ tar -zxvf zookeeper-3.4.13.tar.gz -C /usr/lib/ $ cd /usr/lib/zookeeper-3.4.13/
显示下列内容则已安装成功

1.3配置
进入配置文件目录,复制配置文件zoo_sample.cfg 并将其改名为zoo.cfg 给创建权限
$ cd /usr/lib/zookeeper-3.4.13/conf $ cp zoo_sample.cfg zoo.cfg
$ chmod u+x zoo.cfg
$ cat zoo.cfg

| 参数名 |
说明 |
| clientPort |
客户端连接server的端口,即对外服务端口,一般设置为2181吧。 |
| dataDir |
存储快照文件snapshot的目录。默认情况下,事务日志也会存储在这里。建议同时配置参数dataLogDir, 事务日志的写性能直接影响zk性能。 |
| tickTime |
ZK中的一个时间单元。ZK中所有时间都是以这个时间单元为基础,进行整数倍配置的。例如,session的最小超时时间是2*tickTime。 |
| dataLogDir |
事务日志输出目录。尽量给事务日志的输出配置单独的磁盘或是挂载点,这将极大的提升ZK性能。 |
| globalOutstandingLimit |
最大请求堆积数。默认是1000。ZK运行的时候, 尽管server已经没有空闲来处理更多的客户端请求了,但是还是允许客户端将请求提交到服务器上来,以提高吞吐性能。当然,为了防止Server内存溢出,这个请求堆积数还是需要限制下的。 |
| preAllocSize |
预先开辟磁盘空间,用于后续写入事务日志。默认是64M,每个事务日志大小就是64M。如果ZK的快照频率较大的话,建议适当减小这个参数。(Java system property:zookeeper.preAllocSize ) |
| snapCount |
每进行snapCount次事务日志输出后,触发一次快照(snapshot), 此时,ZK会生成一个snapshot.*文件,同时创建一个新的事务日志文件log.*。默认是100000.(真正的代码实现中,会进行一定的随机数处理,以避免所有服务器在同一时间进行快照而影响性能)(Java system property:zookeeper.snapCount ) |
| traceFile |
用于记录所有请求的log,一般调试过程中可以使用,但是生产环境不建议使用,会严重影响性能。(Java system property:? requestTraceFile ) |
| maxClientCnxns |
单个客户端与单台服务器之间的连接数的限制,是ip级别的,默认是60,如果设置为0,那么表明不作任何限制。请注意这个限制的使用范围,仅仅是单台客户端机器与单台ZK服务器之间的连接数限制,不是针对指定客户端IP,也不是ZK集群的连接数限制,也不是单台ZK对所有客户端的连接数限制。指定客户端IP的限制策略,这里有一个patch,可以尝试一下:http://rdc.taobao.com/team/jm/archives/1334(No Java system property) |
| clientPortAddress |
对于多网卡的机器,可以为每个IP指定不同的监听端口。默认情况是所有IP都监听 clientPort 指定的端口。 New in 3.3.0 |
| minSessionTimeoutmaxSessionTimeout |
Session超时时间限制,如果客户端设置的超时时间不在这个范围,那么会被强制设置为最大或最小时间。默认的Session超时时间是在2 * tickTime ~ 20 * tickTime 这个范围 New in 3.3.0 |
| fsync.warningthresholdms |
事务日志输出时,如果调用fsync方法超过指定的超时时间,那么会在日志中输出警告信息。默认是1000ms。(Java system property: fsync.warningthresholdms )New in 3.3.4 |
| autopurge.purgeInterval |
在上文中已经提到,3.4.0及之后版本,ZK提供了自动清理事务日志和快照文件的功能,这个参数指定了清理频率,单位是小时,需要配置一个1或更大的整数,默认是0,表示不开启自动清理功能。(No Java system property) New in 3.4.0 |
| autopurge.snapRetainCount |
这个参数和上面的参数搭配使用,这个参数指定了需要保留的文件数目。默认是保留3个。(No Java system property) New in 3.4.0 |
| electionAlg |
在之前的版本中, 这个参数配置是允许我们选择leader选举算法,但是由于在以后的版本中,只会留下一种“TCP-based version of fast leader election”算法,所以这个参数目前看来没有用了,这里也不详细展开说了。(No Java system property) |
| initLimit |
Follower在启动过程中,会从Leader同步所有最新数据,然后确定自己能够对外服务的起始状态。Leader允许F在 initLimit 时间内完成这个工作。通常情况下,我们不用太在意这个参数的设置。如果ZK集群的数据量确实很大了,F在启动的时候,从Leader上同步数据的时间也会相应变长,因此在这种情况下,有必要适当调大这个参数了。(No Java system property) |
| syncLimit |
在运行过程中,Leader负责与ZK集群中所有机器进行通信,例如通过一些心跳检测机制,来检测机器的存活状态。如果L发出心跳包在syncLimit之后,还没有从F那里收到响应,那么就认为这个F已经不在线了。注意:不要把这个参数设置得过大,否则可能会掩盖一些问题。(No Java system property) |
| leaderServes |
默认情况下,Leader是会接受客户端连接,并提供正常的读写服务。但是,如果你想让Leader专注于集群中机器的协调,那么可以将这个参数设置为no,这样一来,会大大提高写操作的性能。(Java system property: zookeeper. leaderServes )。 |
| server.x=[hostname]:nnnnn[:nnnnn] |
这里的x是一个数字,与myid文件中的id是一致的。右边可以配置两个端口,第一个端口用于F和L之间的数据同步和其它通信,第二个端口用于Leader选举过程中投票通信。 |
| group.x=nnnnn[:nnnnn]weight.x=nnnnn |
对机器分组和权重设置,可以 参见这里(No Java system property) |
| cnxTimeout |
Leader选举过程中,打开一次连接的超时时间,默认是5s。(Java system property: zookeeper. cnxTimeout ) |
| zookeeper.DigestAuthenticationProvider |
ZK权限设置相关,具体参见 《 使用super 身份对有权限的节点进行操作 》 和 《 ZooKeeper 权限控制 》 |
| skipACL |
对所有客户端请求都不作ACL检查。如果之前节点上设置有权限限制,一旦服务器上打开这个开头,那么也将失效。(Java system property: zookeeper.skipACL ) |
| forceSync |
这个参数确定了是否需要在事务日志提交的时候调用 FileChannel .force来保证数据完全同步到磁盘。(Java system property: zookeeper.forceSync ) |
| jute.maxbuffer |
每个节点最大数据量,是默认是1M。这个限制必须在server和client端都进行设置才会生效。(Java system property: jute.maxbuffer ) |
配置文件之后,我们可以进行启动。
1.4 启动和停止
进入bin目录,启动、停止、重启分和查看当前节点状态(包括集群中是何角色)别执行:
$ cd /usr/lib/zookeeper-3.4.13/bin
$ ./zkServer.sh start $ ./zkServer.sh stop $ ./zkServer.sh restart
$ ./zkServer.sh status
启动之后,当我们通过进程和状态查看内容,发现zookeeper学是未启动。
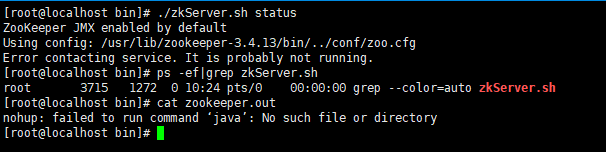
此错误告诉我们,当前java命令不存在,就此zookeeper的安装依赖Java,我们需要安装JDK。
我们可以通过 命令进行jdk的安装
yum -y install java
java -version
安装完之后再通过版本查看命令
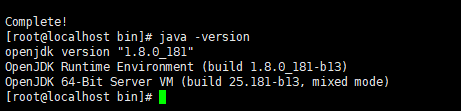
显示1.8JDK已安装成功。我们再来进行zk的启动。
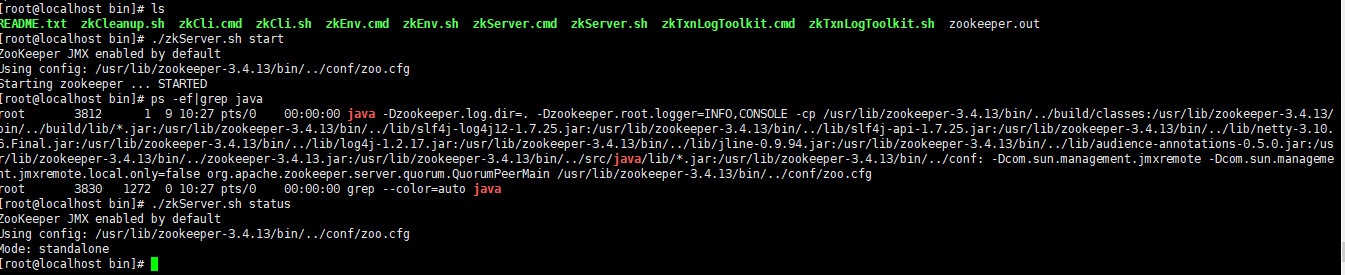
显示当前内容,则zookeeper真正启动成功。
集群的安装
安装前准备
当前文章使用的三台机器进行集群安装 192.168.87.147,192.168.87.148,192.168.87.149,记得每台服务都必须关闭防火墙。
systemctl stop firewalld systemctl disable firewalld
首先对192.168.87.147机器进行安装。下载,解压文件。
$ tar -zxvf zookeeper-3.4.13.tar.gz -C /usr/lib/ $ cd /usr/lib/zookeeper-3.4.13/ $ cd /usr/lib/zookeeper-3.4.13/conf $ cp zoo_sample.cfg zoo.cfg $ chmod u+x zoo.cfg $ cat zoo.cfg
与单机版本不同的是,此处配置文件需要指定当前集群的机器配置,配置如下

server.A=B:C:D:其中 A 是一个数字,表示这个是第几号服务器;B 是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader服务器交换信息的端口(上面的端口Y);D
表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口(上面的端口Z)。
如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。 * 在上面配置的dataDir目录下创建myid文件,填写这个节点上的id号,就是server.A=B:C:D配置的A那个号码
创建和修改完配置文件后,需要指定每一个服务器的id,我们配置中指定了datadir的目录是/usr/lib/zookeeper3.4.13/data所以我们需要在此目录下创建myid文件,指定id
echo "0">/usr/lib/zookeeper3.4.13/data/myid
创建完成之后,我们需要在另外两台机器上面同样安装zookeeper. 如果192.168.87.148的myid则1 ,如果192.168.87.149myid为2
scp -r root@192.168.87.147:/usr/lib/zookeeper3.4.13 /usr/lib/ echo "1">/usr/lib/zookeeper3.4.13/data/myid
注意三台服务对应的myid需要对应,不然无法进行集群。
最后每台服务器启动服务
$ cd /usr/lib/zookeeper-3.4.13/bin $ ./zkServer.sh start
如果每台服务器,显示下列结果,则启动成功。(记得zookeeper是依赖于JDK)

此时集群已搭建。
下列是关于zookeeper的集群,下列代码可以进行当测试。
可以查找通过 https://github.com/wsb878/zookeeperJava 去查看当前查代码的测试方法。