从诠释学到数据到网络:历史来源的数据提取和网络可视化
本教程介绍如何通过使用定性数据分析(QDA)和社会网络分析(SNA)中开发的非技术方法从历史来源提取网络数据(人员、机构、地点等),以及如何使用平台无关的、特别易于使用的Palladio将这些数据可视化。
Table of Contents
简介和案例
网络可视化可以帮助人文学者揭示文本来源中隐藏的、复杂的模式和结构。本教程解释了如何使用Qualitative Data Analysis (QDA) and Social Network Analysis (SNA)中开发的非技术方法从历史来源提取网络数据(人员、机构、地点等), 及怎样使用一个独立与平台的、易用的可视化工具Palladiolink来可视化网络。
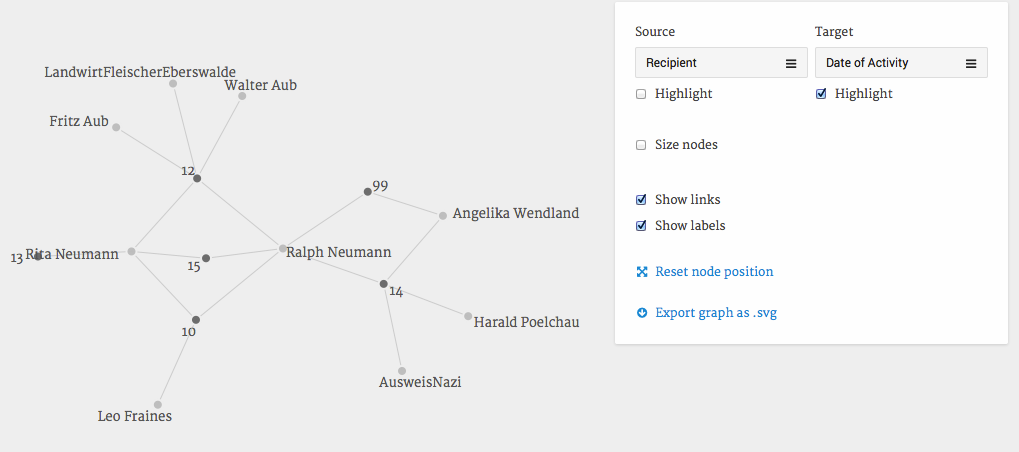
图1:Palladio中的网络可视化以及在本教程结束时您将能够创建的内容。
上图显示的是拉尔夫·诺伊曼(Ralph Neumann)网络中的一段摘录,特别是他与那些在1943年至1945年期间帮助过他和他妹妹的人之间的联系。您可以很容易地修改图表,并询问:谁以哪种方式提供了帮助? 什么时候帮助的? 谁与谁有联系?
This tutorial:
- data extraction from unstructured text
- shows one way to visualize it using Palladio
案例背景
这是一个人类学phD的研究案例的一部分,比如,作者研究这样的问题:
- 社会关系在多大程度上可以解释为什么普通人愿意冒险帮助别人?
- 这种关系如何使人们能够在资源有限的情况下提供这些帮助?
- 社会关系如何帮助犹太难民在地下生存?
在这个项目中,网络可视化帮助我发现了迄今为止被遗忘但非常重要的联系人经纪人,突出了犹太难民作为联系人经纪人的整体意义,并且在1942年到1945年间,帮助了大约1400人,总共有5000次。
下面我将介绍的编码方案是我在博士项目(二战期间关于秘密支持网络)中的一个简化版本。
编码方案coding scheme
在可视化网络关系时,首先也是最困难的挑战之一是决定谁应该是网络的一部分,以及选择的参与者之间的关系将被编码。这可能需要一些时间来弄清楚,并且可能是一个迭代的过程,因为您需要平衡您的研究兴趣和假设与您的文本中的信息的可用性,并以严格的和必要的简化编码方案来表示。
在这个过程中主要的问题是:
- 两个参与者之间关系的哪些方面是相关的?
- 谁是网络的一部分?谁不是呢?
- 哪些属性重要?
- 你的分析目标是什么? 想要找到啥?
我找到了以下这些问题的答案:
什么定义了两个参与者之间的关系?
任何直接有助于被迫害者生存的行动。这包括非犹太共产主义者,但不包括那些选择不谴责难民或仅仅是演员之间的熟人的旁观者(因为消息来源没有足够的报道)。行动者被编码为提供或接受援助行为的人,独立于他们的难民身份。目前还没有一种简单而可靠的方法来处理含糊不清和怀疑。因此,我选择只收集可验证的数据。
谁是网络的一部分?谁不是呢?
任何被称为帮助者的人,参与帮助活动,参与旨在抑制帮助行为的活动。事实上,一些帮助活动与我的案例研究无关,但在其他情况下,这种方法揭示了迄今为止网络之间意想不到的交叉连接。
你观察到哪些类型的关系?
粗略的分类:帮助的形式,关系的强度,帮助的持续时间,帮助的时间,第一次见面的时间(都用6个月的步骤编码 Both coded in six-months steps)。
哪些属性是相关的?
主要是根据国家社会主义立法的种族地位。
你的目标是什么?
更深入地了解谁帮助谁,以及发现与网络理论相对应的数据模式。我的信息源和可视化数据之间的高效交互使我坚持这一点。
请注意,编码方案一般不能在所有微妙和矛盾的情况下表示源的全部复杂性。编码方案的目的是开发一个您感兴趣的关系模型。因此,关系的类型和属性被抽象出来,并对文本中所表达的复杂性进行分类。这也意味着,在许多情况下,网络数据和可视化只有在与它们的原始上下文(在我的例子中是我提取它的主要来源)重新结合时才有意义。
将文本解释转化为数据收集,其根源在于社会学定性数据分析。重要的是,你和其他人可以回溯你的步骤,了解你如何定义你的关系。抽象地定义它们是很有帮助的,并从您的来源提供示例来进一步说明您的选择。您生成的任何数据只能与您的编码实践一样清晰一致。在创建编码方案的迭代过程中,通过在各种不同的源上测试它,直到它适合为止,清晰度和连贯性都在增加。
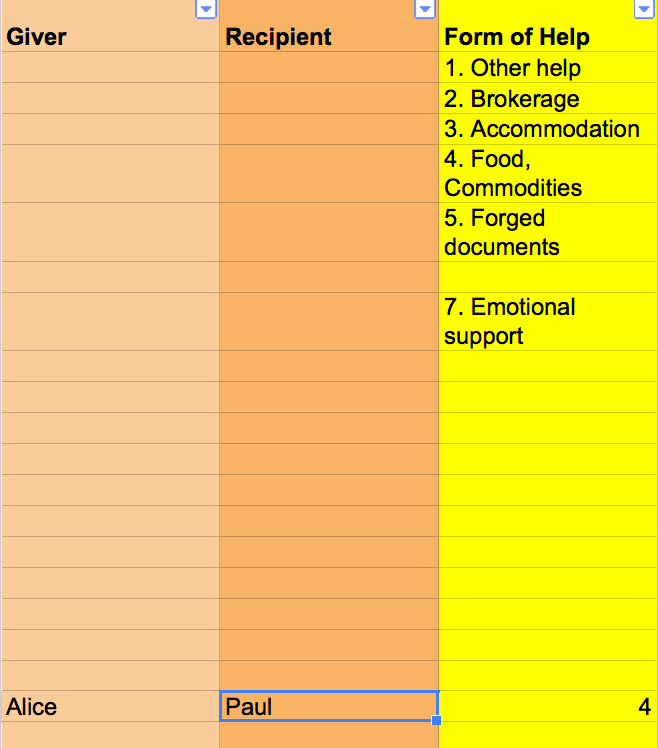
Figure 2: A first stab at the coding scheme
图2显示了一个快照,其中包含了我在项目中使用的编码方案的示例数据。在这种情况下,爱丽丝帮助保罗。我们可以用演员“爱丽丝”和“保罗”之间的关系来表达这一点,它们都有“帮助的形式”的关系。在这个范畴内,我们发现子范畴4。这进一步描述了它们之间的关系。
所有主要的网络可视化工具都允许您指定网络是像这样定向的还是无定向的。在定向网络中,关系描述了从一个参与者到另一个参与者的交换,在我们的例子中,这是“帮助”。按照惯例,数据集中首先提到活动节点(在本例中是Alice)。在有向网络的可视化中,您将看到箭头从一个参与者指向另一个参与者。关系也可以是互反的,例如当Alice帮助Bob Bob时Bob帮助Alice。
然而,通常情况下,是无向的,例如,两个参与者只是同一个组织的一部分。在这种情况下,网络应该是无定向的,并且由两个参与者之间的一条简单的线表示。
我想知道参与者们提供帮助的频率和接受帮助的频率。我对犹太人自助的程度特别感兴趣,这就是为什么有针对性的网络方法和“给予者”和“接受者”的角色是有意义的。编码方案的第三列是可选的,进一步描述了Alice和Paul之间的关系。作为一个类别,我选择了“帮助的形式”,这反映了最常见的支持方式。
在对不同类型的文本和不同类型的支持网络进行编码的过程中,出现了不同的类别和子类别。例如,在这个过程中,我了解到哪些相关的帮助形式很少被描述,因此无法追踪,例如提供与支持相关的信息。在开始的时候,您需要经常调整您的编码方案,并准备好多次重新编码您的数据,直到它与您的来源和兴趣一致为止。
就目前而言,编码方案传达了Alice为Paul提供食物或其他商品的信息,对应子类别“4”的值为4。食品、商品“类”中的“帮助形式”。然而,人际关系比这要复杂得多,其特征是各种各样不断变化的关系层。在某种程度上,我们可以通过收集多重关系来表示这种复杂性。想想这个例句:“1944年9月,保罗住在他朋友爱丽丝家;他们是在去年复活节前后认识的。
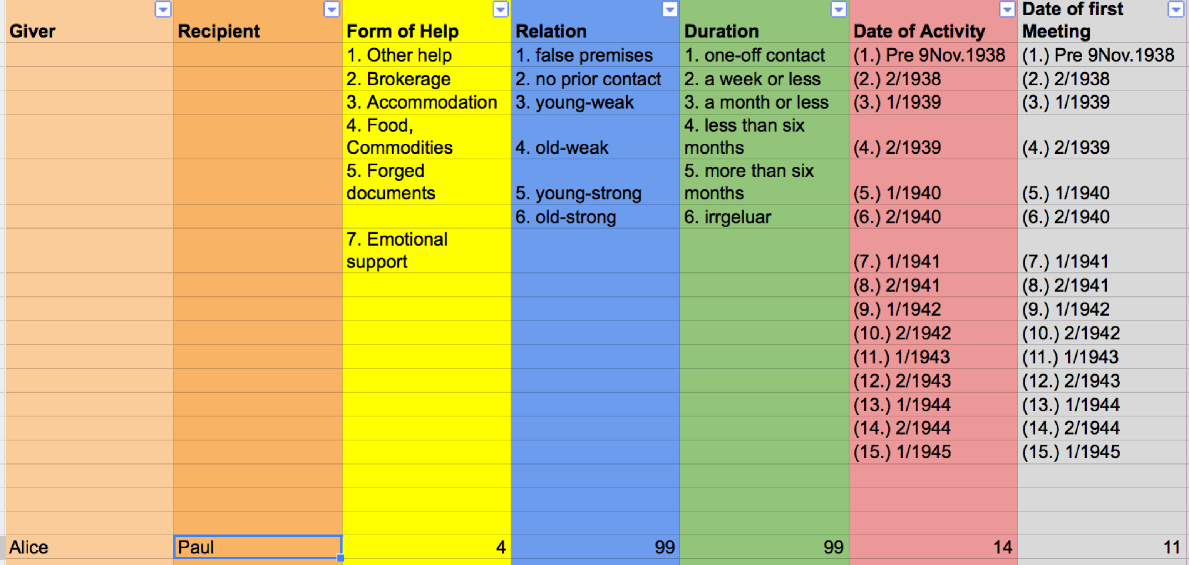
图3,示例句子的一个表达
图3中的编码方案更详细地描述了帮助者和接收者之间的关系。例如,“关系”给出了两个参与者相互了解程度的粗略分类,“持续时间”表示帮助行为持续了多长时间,“活动日期”表示帮助行为发生的时间,“第一次见面的日期”应该是不言自明的。这里的值“99”指定了“unknown”,因为示例语句没有更详细地描述Alice和Paul之间的关系强度。注意,这个方案只关注于收集帮助行为,而不是捕捉人与人之间关系的发展(我的资料中没有涉及到这一点)。这样的显式选择定义了分析期间数据的值。
还可以收集网络中参与者的信息;所谓的属性数据使用的格式基本相同。图4显示了Alice和Paul的示例数据。
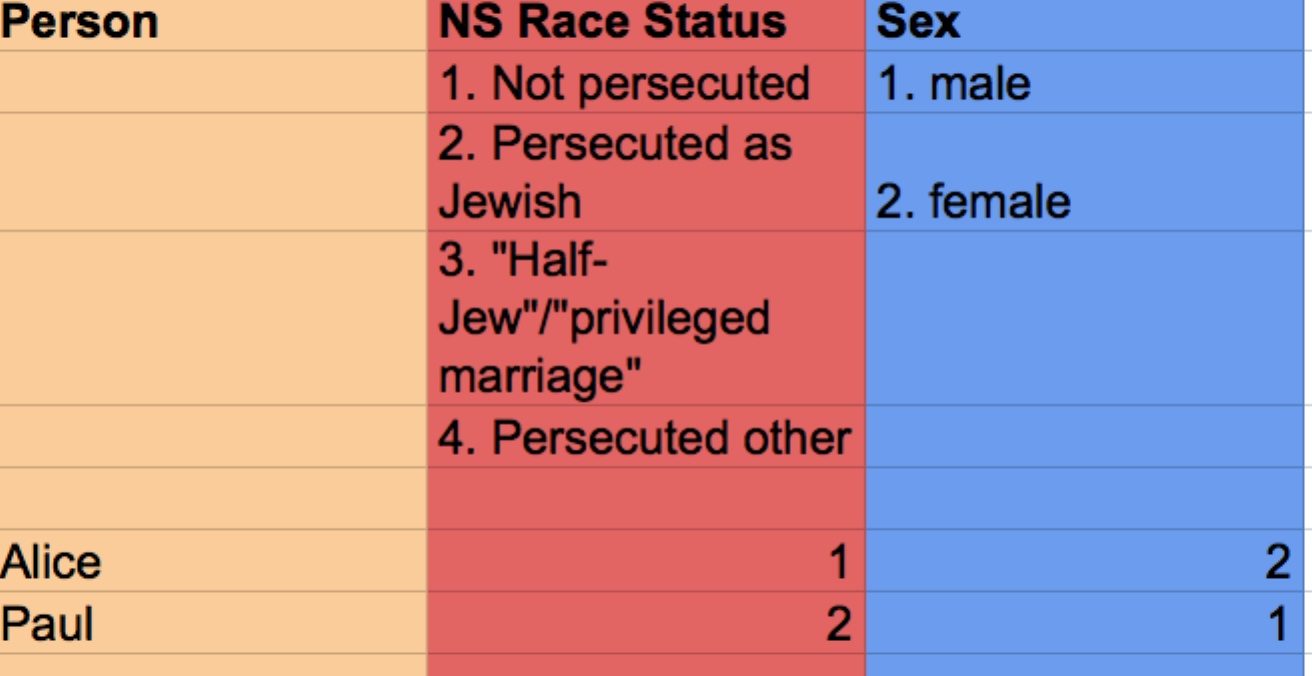
图4:示例属性数据
如果我们阅读现在存储在编码方案中的信息,我们会发现Alice为Paul提供了住宿(“帮助的形式”:4),我们不知道他们有多亲密(“关系”:99),或者他呆了多久(“持续时间”:99)。然而,我们确实知道这件事发生在1944年下半年(“活动日期”:14),他们在1943年上半年第一次见面(“第一次见面日期”:11)。第一次见面的日期可以从“前一年的复活节前后”中推断出来。如果有疑问,我总是选择输入“99”表示“未知”。
但是如果Alice在Paul和她在一起的时候也帮助了他的情感支持(另一种“帮助形式”)呢?为了认识到这一点,我编写了一行代码,其中描述了提供住宿,下面的第二行代码描述了提供情感支持。注意,并不是所有的网络可视化工具都允许您表示并行的边,并且会忽略发生的第二个帮助行为,或者尝试合并这两个关系。NodeXL和Palladio都能解决这个问题,有传言说Gephi的未来发行也能解决这个问题。如果您遇到这个问题,并且这两种工具都不适合您,我建议您设置一个关系数据库,并为每个可视化处理特定的查询。
设计这样的编码方案的过程迫使您明确自己的假设、兴趣和可供使用的材料,这是数据分析之外的有价值的东西。从文本中提取网络数据的另一个作用是,您将非常了解自己的来源:遵循“A与B、C和D在Y时刻通过关系类型X连接”的模型的句子可能很少。相反,它需要仔细阅读,深入语境知识和解释,以找出谁与谁以何种方式联系在一起。这意味着以这种方式编码数据将会引发许多问题,并将迫使您比使用“传统”方法更深入、更严格地研究数据源。
用Palladio可视化
Once you have come up with a coding scheme and encoded your sources you are ready to visualize the network relationships. First make sure that all empty cells are filled with either a number representing a type of tie or with “99” for “unknown”. Create a new copy of your file (Save as..) and delete the codes for the different categories so that your sheet looks something like Figure 5.
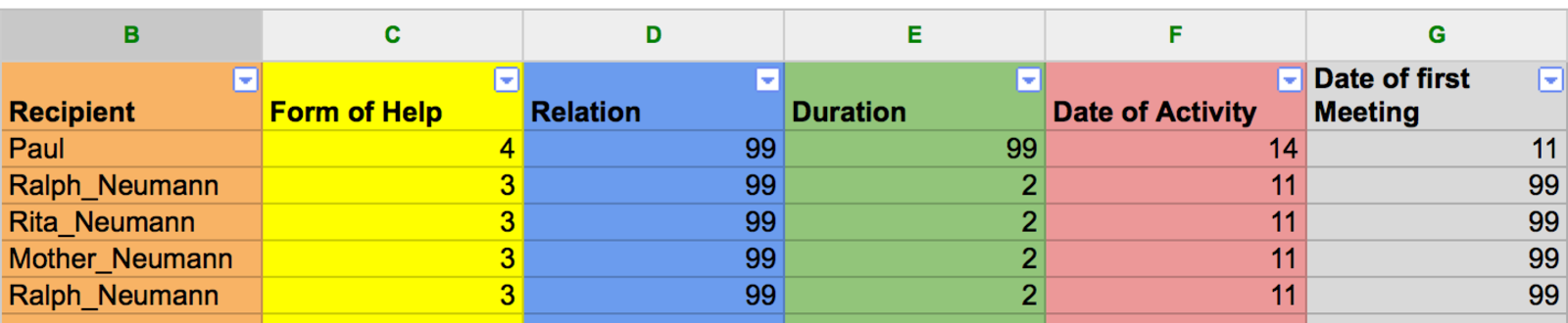
Figure 5: Sample attribute data ready to be exported for visualization or computation.
所有电子表格编辑器都可以将表导出为.csv(逗号分隔值)或.txt文件。这些文件可以导入到所有常用的网络可视化工具中(请参阅本教程末尾的列表)。但是,对于您的第一步,我建议您尝试使用Palladio,这是斯坦福大学在主动开发中非常容易使用的数据可视化工具。它在浏览器中运行,因此是独立于平台的。请注意,Palladio虽然功能广泛,但它的设计主要用于快速可视化,而不是复杂的网络分析。
下面的步骤将解释如何在Palladio中可视化网络数据,但我也建议您查看一下它们自己的培训材料,并探索它们的示例数据。但是在这里,我使用了一个基于前面介绍的编码方案的稍微修改过的示例数据集. 您也可以下载它并使用它来探索其他工具。
一步一步来:
- Palladio. Go to http://palladio.designhumanities.org/. click 'start'
- 下载示例数据
载入属性数据。From your data sheet, copy the
Attributesdata and paste it in the white section of the page, now click “Load”.
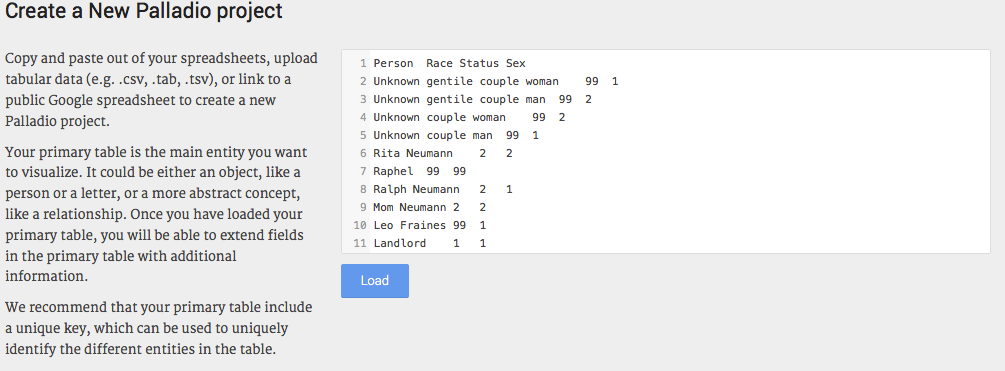
将表的标题更改为更有意义的内容,例如“People”。现在您看到的列“Person”、“Race Status”和“Sex”与示例数据中的列相对应。接下来,您需要确保Palladio理解与您刚刚在数据库中输入的人相关的操作。
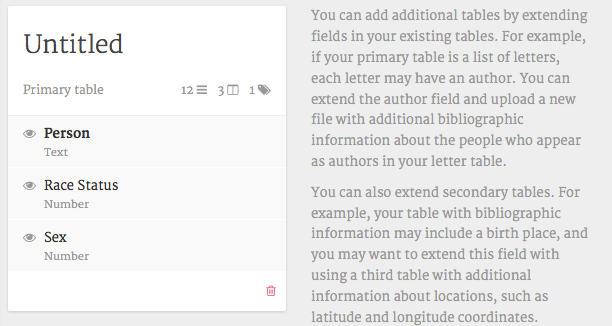
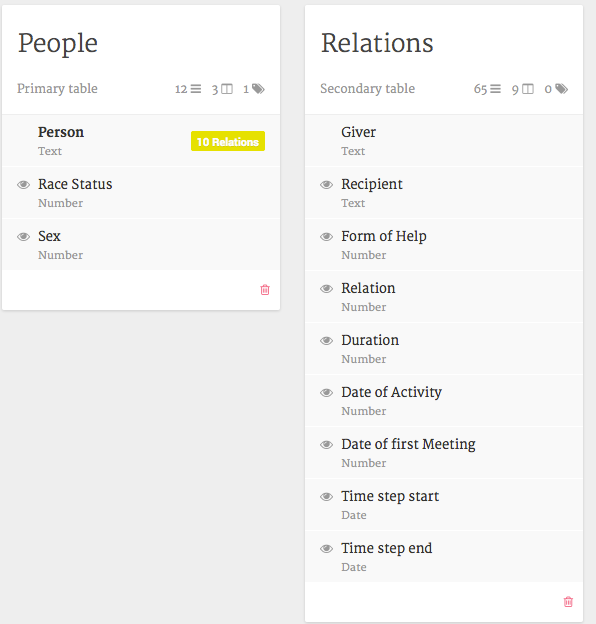
载入关系数据。为此,单击“Person”和“Add a new table”。现在将所有关系数据(示例数据 ,表1)粘贴到适当的字段中。Palladio希望使用惟一的标识符将关系信息链接到actor属性信息。确保这些行很好,并避免任何令人讨厌的字符,如“/”。如果你这样做了,Palladio会给你提示错误信息。单击“加载数据”,关闭覆盖窗口,返回主数据概述。你应该看到这样的东西:
(自己看原文)