版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/lll1528238733/article/details/76033668
协同过滤(Collaborative Filtering,简称CF)
协同过滤常常被用于分辨某位特定顾客可能感兴趣的东西,这些结论来自于其他相似顾客对哪些产品感兴趣的分析。
数据结构
协同过滤,主要收集每个用户对使用过的物品的评价。
评价可以理解为经常在电商网站上出现的,五星级的评分。
注意:不同用户的评分标准不同,所以需要对评分进行标准化处理。
标准化为0-1之间的值。
①用户评分向量
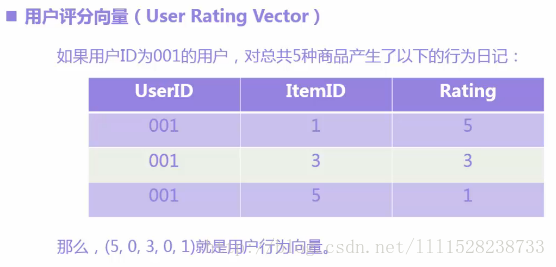
②商品评分向量
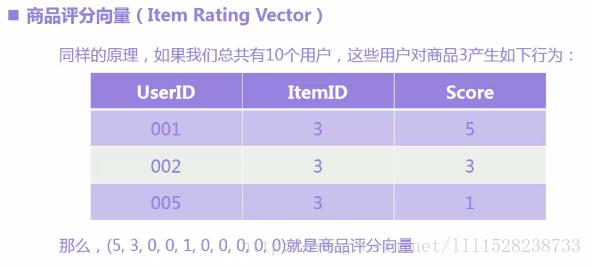
③向量距离计算(采用欧氏距离)
④相似度计算(Similarity)
sim(x,y)=1/1+d(x,y)
⑤越接近1越相似,越接近0越不相似
⑥相似邻居计算
- 固定数量的邻居(k-neighborhods)
不论邻居的“远近”,只取最近的k个,作为其邻居。
- 基于相似度门槛的邻居(Threshold-based neighborhoods)
基于相似度门槛的邻居计算是对邻居的远近进行最大值的限制,落在以当前点为中心,距离k的区域的所有点都作为当前点的邻居。

实现协同过滤的API
(API就是操作系统留给应用程序的一个调用接口,应用程序通过调用操作系统的 API 而使操作系统去执行应用程序的命令)
install.packages(“recommenderlab”)
Recommender(x,method=”UBCF”,parameter)
1、x 训练样本
2、method 推荐方法,UBCF为基于用户的协同过滤方法
3、parameter推荐方法的参数(是一个list对象)
method 距离的计算方法
- euclidean 欧式距离
- pearson 皮尔森距离
- cosine 余弦距离
nn 固定邻居的数量
normalize是否标准化,默认为FALSE
代码实现:
library(recommenderlab)
data <- read.csv('data.csv')
rm <- as(data, "realRatingMatrix")
rec <- Recommender(
rm,
method="UBCF",
parameter=list(
method="euclidean",
nn=3
)
)
pre <- predict(rec, rm, n=1)
as(pre, 'list')
$`1`
[1] "104"
$`2`
[1] "107"我们可以看到,给用户1推荐的是104,给用户2推荐的是107
协同过滤算法目前应用于各大电商网站,我们经常可以电商网站中看到猜你喜欢之类的栏目,就是根据协同过滤算法得到的结果!