1 f = open(str,'r',-1,'utf-8') #str为待输入文件名,'r'代表只读模式,'-1'为默认缓冲区大小
1 tet = f.read().lower() #读取文本内容并将字母全部转换为小写形式 2 3 text = tet.replace('\n',' ').replace('.',' ').replace(',',' ').\ #对标点符号的替换操作 4 replace('!',' ').replace('\\',' ').replace('#',' ').\ 5 replace('[',' ').replace(']',' ').replace(':',' ').\ 6 replace('?',' ').replace('-',' ').replace('\'',' ').\ 7 replace('\"',' ').replace('(',' ').replace(')',' ').\ 8 replace('—',' ').replace(';',' ').split() #用空格作为分隔符对将字符串转换为列表
(3).命令行输入并执行命令
1 try: 2 opts, args = getopt.getopt(argv,"sh",["ifile","ofile"]) #设置命令行参数 3 except getopt.GetoptError: 4 print("test.py -i <inputfile> -o <outputfile>") 5 sys.exit(2) 6 for opt,arg in opts: 7 if opt == "-s": #命令行参数为-s时执行的操作 8 num = len(list) 9 print('total',num) 10 print('\n') 11 for word in list: 12 print('{:20s}{:>5d}{}'.format(word[0],word[1],'\n')) 13 elif opt == "-h": 14 print("please input the parameter")
1 if __name__ == "__main__": #将参数传给主函数main(argv) 2 main(sys.argv[1:])
(5).重复单词的计数
作业要求重复单词只记一次,并把重复次数记录下来,我采取的办法是使用字典这一数据结构完成这一功能,实现过程为,字典的key为单词,value为出现的次数,依次遍历字符串列表,如果列表元素不在字典中,将字符串加入字典并将该字典元素的value值置1,列表元素在字典中则value值加1,最后将字典的key值根据value值进行排序,就可以得到满足需求的字典,字典元素个数即为total值,字典键值对为单词及其个数,这一功能是整个项目中极为重要的一环,也是个人觉得处理地非常好的地方,是个得意之处,实现代码如下:
1 count_dict = {} #创建空字典 2 for str in text: #遍历列表元素 3 if str in count_dict.keys(): #根据上述逻辑对字典进行键值对的赋值 4 count_dict[str] = count_dict[str] + 1 5 else: 6 count_dict[str] = 1 7 count_list=sorted(count_dict.items(),key=lambda x:x[1],reverse=True)
2.功能一的执行效果截图

3.功能二中的重点和难点
(1).数据量
根据题目描述,我们就可以看到数据量对于本功能是非常重要的,需要承受40MB的文件大小而不会导致程序崩溃,这对于Python来说不是很大的数据量,所以Python自身就帮助我解决了这一难点。
(2).命令行参数
本功能相较于功能一,其主要区别就在于命令行参数的变化,命令行只有一个参数,所以,程序必然需要根据参数多少进行相应的功能处理,所以,根据参数个数进行判断也是本功能的重点内容,只需要在原来的基础上加上判断条件就可以了。
4.功能二的执行效果截图
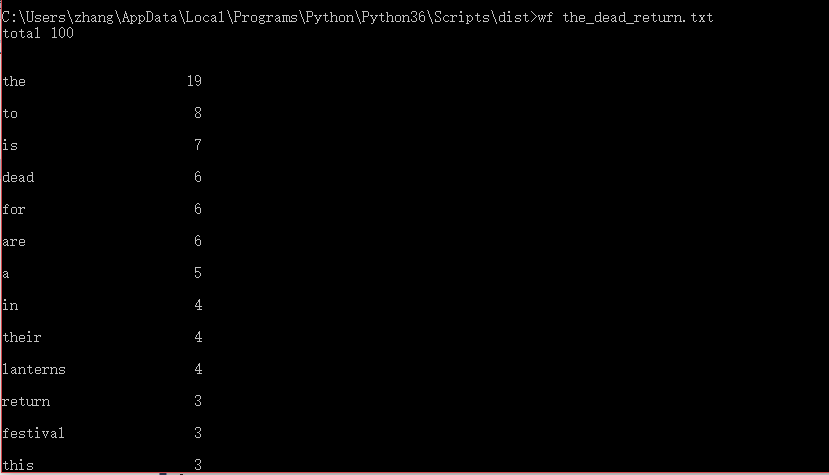
数据量稍大,所以截图主要截了执行的前半部分。
5.功能三中的重点和难点
(1).处理和功能二命令行参数之间的区别
因为功能三从命令行参数来看和功能二是相似的,但是二者的功能差别由很大,所以区分二者的命令行参数就成为了本功能第一个重点也是难点。这里我采取的方法是使用正则表达式匹配输入的命令行参数,也就是匹配字符串,因为功能二中是txt文件,参数以.txt结尾,功能三是文件夹,名称只是单独的字符串,虽然是比较简单的正则,但是能想到使用正则也是个人的一个得意之处,根据正则表达式所写的代码如下:
1 pattern = re.compile('.+\.txt') #匹配.txt>结尾的正则表达式 2 folder_name = argv[-1] #通过argv传入的参数名称 3 m = re.findall(pattern,folder_name) #寻找匹配项 4 if len(m) != 0: #如果匹配则列表存在元素,为文件名,执行功能二 5 ... 6 else #如果不匹配则列表不存在元素,为文件夹名,执行功能三 7 ...
(2).打开文件夹并获取文件名称
本功能最后要做的还是词频统计,与之前的功能一、二不同的是,本功能需要根据文件夹的名字找出其中包含的文件并且进行词频统计,也就是多了一个进入指定文件夹并执行获取文件名的过程,进入文件夹并获取文件名的具体过程为:一.5.(1)一节中已经完成了对文件夹名称的匹配识别,我们已经得到了文件夹的名称,这时候可以通过os模块中的chdir(path)命令进入文件夹,path即为文件夹的名称,然后还是使用os模块的listdir()命令获取文件名列表,代码如下:
1 os.chdir(folder_name) #进入folder_name文件夹 2 filename_list = os.listdir() #获取文件夹中的文件名并生成一个列表
(3).得到文件名后分别计算词频
进行完之前的步骤后我们得到了文件名,又回到了功能二的范畴,和功能二产生了交集,所以想到可以把整个项目分为几个函数方便重用,所以在原来代码的基础上,我写了2个函数,一个叫做file_read(str),负责读取文件并返回一个包含文档中所有单词的列表,另一个叫做word_count(argv),负责对单词列表进行计数等处理,因为这一重点内容和下一小节联系十分紧密,所以代码和下一小节一起贴出来。
(4).取前十和递归调用
功能一和二要求列出所有单词,本功能只需要前十,所以本来的word_count(argv)函数无法达到目的,所以我在原有的基础多加了一个标志位,在功能三调用这个函数时单独把标志位置1(初始设为0),当标志位为1时执行取前十操作,标志位为0时取所有元素列表。还有就是文件夹操作和文件读取为了方便我放在了同一个函数中,所以,在得到文件名之后很容易的就可以进行递归操作,完成词频统计及输出的过程,接下来把功能三的完整代码贴出来,如下:
1 def file_read(str): #用于读取文件并返回分词之后的单词列表 2 f = open(str,'r',-1,'utf-8','ignore',None,True,None) 3 tet = f.read().lower() 4 text = tet.replace('\n',' ').replace('.',' ').replace(',',' ').\ 5 replace('!',' ').replace('\\',' ').replace('#',' ').\ 6 replace('[',' ').replace(']',' ').replace(':',' ').\ 7 replace('?',' ').replace('-',' ').replace('\'',' ').\ 8 replace('\"',' ').replace('(',' ').replace(')',' ').\ 9 replace('—',' ').replace(';',' ').split() 10 count_dict = {} 11 for str in text: 12 if str in count_dict.keys(): 13 count_dict[str] = count_dict[str] + 1 14 else: 15 count_dict[str] = 1 16 count_list=sorted(count_dict.items(),key=lambda x:x[1],reverse=True) 17 f.close() 18 return count_list #返回的分词列表 19 20 def get_words(argv,flag): #对分完词之后的列表进行计算total、词频、输出等操作 21 22 if len(argv) == 2: #如果有两个命令行参数 23 try: 24 list = file_read(argv[-1]) 25 opts, args = getopt.getopt(argv,"sh",["ifile","ofile"]) 26 except getopt.GetoptError: 27 print("test.py -i <inputfile> -o <outputfile>") 28 sys.exit(2) 29 for opt,arg in opts: 30 if opt == "-s": #如果第一个参数是-s 31 num = len(list) 32 print('total',num) 33 print('\n') 34 for word in list: 35 print('{:20s}{:>5d}{}'.format(word[0],word[1],'\n')) 36 elif opt == "-h": 37 print("please input the parameter") 38 elif len(argv) == 1: #如果有一个命令行参数 39 pattern = re.compile('.+\.txt') 40 folder_name = argv[-1] 41 m = re.findall(pattern,folder_name) 42 if len(m) != 0: #参数以.txt结尾,为文件名,直接执行词频操作 43 list = fileRead(argv[-1]) 44 if flag == 0: #标志位为0,把所有单词都列出来 45 print('total',len(list)) 46 print('\n') 47 for item in list: 48 print('{:20s}{:>5d}{}'.format(item[0],item[1],'\n')) 49 else: #标志位不为0,只列出前十 50 print('total',len(list), 'words') 51 print('\n') 52 if len(list) > 10: 53 for i in range(10): 54 print('{:20s}{:>5d}'.format(list[i][0],list[i][1])) 55 else: #如果本身不超过10个单词量,则列出所有单词即可 56 for item in list: 57 print('{:20s}{:>5d}'.format(item[0],item[1])) 58 else: 59 os.chdir(folder_name) #文件夹操作 60 filename_list = os.listdir() 61 for file_name in filename_list: 62 print(file_name[:-4] + '\n') 63 file_list = [file_name] 64 get_words(file_list,1) #得到文件名,进行递归操作,标志位置1,说明要取前10 65 print('----\n') 66 67 def main(argv): 68 get_words(argv,0) 69 70 if __name__ == "__main__": 71 main(sys.argv[1:])
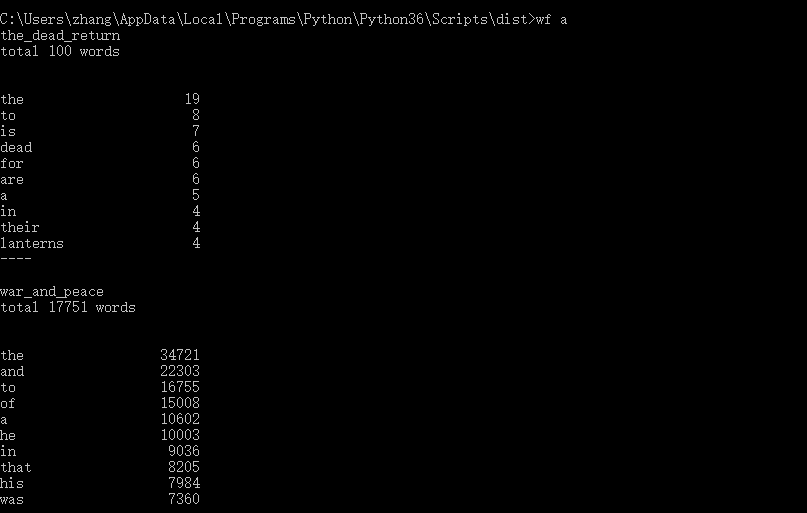
6.功能三的执行效果截图(文件夹名字为'a')
7.功能四中的重点和难点
(1).重定向
之前没了解过什么是linux中的重定向,而重定向又是本功能中必不可少的功能,自然而然重定向就成为了本节的重点和难点,那么linux重定向是什么呢?