章节1 第零周:开始之前
勤快写,多动手,不浮躁,坚持坚持坚持。-----慢慢来,做完美
科学上网 好的IDE 工具 理解 模仿 实战
画流程图,添加异常处理
几种爬虫比较
urllib+正则:无第三方依赖
requests+BeautifulSoup:library
scrapy:框架
从上往下抽象程度增加,方便程度增加。“路怎么走,自己选。”bs4官网基础知识
tag中包含多个字符串 ,可以使用 .strings 来循环获取
.stripped_strings 可以去除多余空白内容
1、prettify() 方法将Beautiful Soup的文档树格式化后以Unicode编码输出,每个XML/HTML标签都独占一行
2、想得到tag中包含的文本内容,那么可以用 get_text() 方法,这个方法获取到tag中包含的所有文版内容包括子孙tag中的内容,并将结果作为Unicode字符串返回
3、使用Beautiful Soup解析后,文档都被转换成了Unicode
4、通过Beautiful Soup输出文档时,不管输入文档是什么编码方式,输出编码均为UTF-8编码
对计算时间要求很高或者计算机的时间比程序员的时间更值钱,那么就应该直接使用 lxml .
章节2 第一周:学会爬取网页信息
网页的构成 结构,样式,文档树,各种层级标签(唯一定位即可)
本地网页:
1、BeautifulSoup解析网页,类似css选择器,能在文档树里标识唯一位置即可 获取
2、找到正确元素,审查元素 定位
3、处理标签文本,释放元素 筛选
from bs4 import BeautifulSoup
path = './1_2_homework_required/index.html' #这里使用了相对路径,只要你本地有这个文件就能打开
with open(path, 'r') as wb_data: # 使用with open打开本地文件,自带检测,不需要关闭
Soup = BeautifulSoup(wb_data, 'lxml') # 解析网页内容,lxmlb比较快
titles = Soup.select('div.caption > h4 > a') # 复制每个元素的css selector 路径即可
stars = Soup.select('div.col-md-9 > div > div > div > div.ratings > p:nth-of-type(2)')
# 为了从父节点开始取,此处保留:nth-of-type(2),观察网页,多取几个星星的selector,就发现规律了for title, image, star in zip(titles, images, stars): # 使用for循环,把每个元素装到字典中,方便查询
data = {
'title': title.get_text(), # 使用get_text()方法取出文本
'image': image.get('src'), # 使用get方法取出带有src的图片链接
'star': len(star.find_all("span", class_='glyphicon glyphicon-star'))
# 观察发现,每一个星星会有一次<span class="glyphicon glyphicon-star"></span>,所以我们统计有多少次
# 使用find_all 统计有几处是★的样式,第一个参数定位标签名,第二个参数定位css 样式,具体可以参考BeautifulSoup
# 由于find_all()返回的结果是列表,我们再使用len()方法去计算列表中的元素个数,也就是星星的数量
}
print(data)
----------------------------
print(1,2,3,sep='\n--------\n')
'''
1
--------
2
--------
3
'''title可以去头部标签里面取,更快
address = soup.select('div.pho_info > p')[0].get('title') # 和 get('href')通过属性取值
cates = Soup.select('div.article-info > p.meta-info') #解析多子标签,返回列表
'cate': list(cates.stripped_strings)
#Object.stripped_strings【父集下面所有子标签的文本信息(聚合信息)】 高级版本get_text()外网解析:requests+Beautifulsoup
1、服务器与本地交换机制 http协议,Request请求八种get,post 。Response回应,返回状态码
2、选择,大范围,利用属性缩小范围。# a[target='_blank']' 属性选择缩小范围
3、cookies伪造登录信息,headers
4、获取多页,定义函数,找每一页链接规律,列表解析式,反扒加入时间延时模块,大型网站换IP,模拟难搞的用手机页面伪造,简单。
#str(i)表示变量
urls = ['http://www.mm131.com/xinggan/3520_{}.html'.format(str(i)) for i in range(1,23,1)]
for single_url in urls:
get_attractions(single_url) #遍历列表并执行,保护反扒增加延时
-------------------------------------------
#另外一种,传递参数
def get_page_link(page_number):
for each_number in range(1,page_number): # 每页24个链接,这里输入的是页码
full_url = 'http://bj.xiaozhu.com/search-duanzufang-p{}-0/'.format(each_number)
wb_data = requests.get(full_url)5、登录爬取,使用cookies。扒手机页面
6、动态(异步)加载,去network找链接规律,xhr下滑几页。

字典和列表,都是可变,一般用data=None保证数据安全。
from bs4 import BeautifulSoup
import requests
import time
url = 'https://knewone.com/discover?page='
def get_page(url,data=None):
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text,'lxml')
imgs = soup.select('a.cover-inner > img')
links = soup.select('section.content > h4 > a')
if data==None:
for img,title,link in zip(imgs,titles,links):
data = {
'img':img.get('src'),
'link':link.get('href')
}
print(data) #数据被污染,从新使用置为None
def get_more_pages(start,end):
for one in range(start,end):
get_page(url+str(one))
time.sleep(2) #暂停保护
get_more_pages(1,2)实战:58同城二手平板
设计工作流,分析页面,分析详情……
第一步:得到urls链接
巧用:id = url.split('/')[-1].strip('x.shtml')
构造字典可以这样:
'cate' : '个人' if who_sells == 0 else '商家' #列表解析式
404检测:if wb_data.status_code == 404:
核心代码
-----------config.py--------------------
import pymongo
client = pymongo.MongoClient('localhost', 27017)
tongcheng = client['ceshi']
url_list = tongcheng['url_list4']
item_info = tongcheng['item_info4']
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/52.0.2743.116 Safari/537.36 Edge/15.15063'}
-------------参数传递---------------------------
def get_links_from(channel, pages, who_sells='o'):
# http://bj.ganji.com/ershoubijibendiannao/o3/
list_view = '{}{}{}/'.format(channel, str(who_sells), str(pages))
-----------多进程------------------------
def get_all_links_from(channel): #新增参数
for i in range(1,100):
get_links_from(channel,i)
if __name__ == '__main__':
pool = Pool()
# pool = Pool(processes=6)
pool.map(get_all_links_from,channel_list.split()) #map里面函数没括号
------------数据库计数---------------------
import time
from pages_parsing import url_list #导入数据库
while True:
print(url_list.find().count())
time.sleep(5)
--------------断点续传,集合去重-------------
db_urls = [item['url'] for item in url_list.find()]
index_urls = [item['url'] for item in item_info.find()]
x = set(db_urls)
y = set(index_urls)
rest_of_urls = x-y
章节3 第二周:学会爬取大规模数据
Mongdb类似Excel,可见即可得工具,Mongo Explore插件
命名小心关键字啊!!!
爬取大规模大数据流程:
思路最重要
1、观察页面特征(不同用户商家男女),编写通用程序
2、设计工作流程 爬虫一得到列表页url,得到商品链接,爬虫二得到详情页,得到每个商品详情。各司其职。
3、一页一页向下面解析,不一定全符合规律,小心
代理及404判断
wb_data = requests.get(list_view,headers=headers,proxies=proxies),伪造浏览器,代理ip
----------------------------------
if wb_data.status_code == 404:
pass
else:
soup = BeautifulSoup(wb_data.text, 'lxml')单进程,单进程单线程:单人单桌(仅一桌仅一人) 单进程多线程:多人单桌(一桌多人)
多进程单线程:单人多桌(每桌一人) 多进程多线程:吃喜酒(电脑得多核)
try函数:出错继续运行
def try_to_make(a_mess):
try:
print(1/a_mess)
except (ZeroDivisionError,TypeError): #错误代码放这
print('ok~')
try_to_make(10)太扯了,一爬就被封ip了,哎
赶集
'pub_date':soup.select('.pr-5')[0].text.strip().split(' ')[0],
# 复杂地区解析
'area':list(map(lambda x:x.text,soup.select('ul.det-infor > li:nth-of-type(3) > a'))),
---------------map函数-------------后面列表迭代
'cates':list(soup.select('ul.det-infor > li:nth-of-type(1) > span')[0].stripped_strings)
---------------字符串--------------爬虫加速:多核,lxml的xpath快10倍,异步
用下一页标签判断是否为最后页
章节4 第三周:数据统计与分析
怎么让数据说话?
1、提出正确问题,正确解释现象(不要结论去验证假设),正确验证假设,幸存者偏差,对比(别人,以前)
2、数据论证,细分,因果关联(脑图,excel)
3、解读数据,数据会说话,数据会说谎,样本偏差
整理清洗数据(删除不要的,整理美观变成我们需要的,重新写入数据库或生成器)
更新数据库
数据可视化
jupyter notebook(不错教程)工具 esc+m 切换模式 tab补全 shift+enter执行代码
MongoDB导入数据json,安装charts库 开始导入json格式的文件:注意是在CMD目录下, 而不是在客户端shell运行mongoimport命令 shift+回车,执行代码
# 导入数据须知
1. 首先运行 mongo shell在数据库中创建一个 collection —— db.createCollection('your_name')
2. 接下来直接在终端/命令行(cmd)中使用命令导入 json 格式的数据 —— mongoimport -d database_name
-c collection_name path/file_name.json
eg: cmd后直接运行
—— mongoimport -d ceshi -c beijing C:\Users\Administrator\Desktop\fourpython源码\week3\week3_homework\data_sample/sample.json数据边筛选边显示(Highcharts),分析
#列表变集合去重
arealist=[]
for i in item_info.find(): #全部遍历
# print(i['area'])
arealist.append(i['area'][0])
#列表转集合,遍历完成之后
area_index = list(set(arealist)) #去集合重然后再转为列表
print(area_index)#统计次数,结合取出的area_times=[]
for item in area_index:
area_times.append(arealist.count(item))
print(area_times)妙用生成器,比for快多了
find函数精确查找数据,强大
聚合管道高效查找,管道模型层次筛选,最后输出数据(类似mysql的聚合函数)

已知 求解 所需数据结构
Python Charts库的使用
charts库实际是对调用Highcharts API 进行封装,通过python生成Highcharts脚本
show = 'inline',如果没有这个选项,会开启新标签页面
data = [[1,8],[2,7],[3,4],[4,3],[5,9],[6,0],[7,10],[8,5]]
表示第一个值 x坐标1,y坐标8,默认从0开始
可以在serie中指定color颜色,type显示的形式(column:柱状图,bar:横向柱状图,line:曲线,area:范围,spline:曲线,scatter:点状,pie:饼状图)
章节5 第四周:搭建 Django 数据可视化网站
以前忽略了,这个需要重点学习
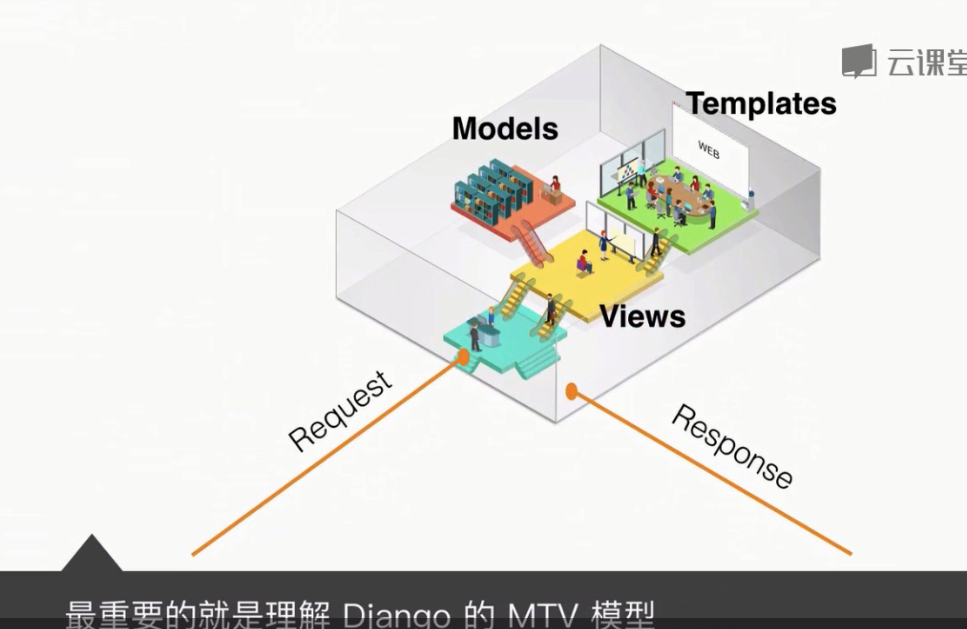
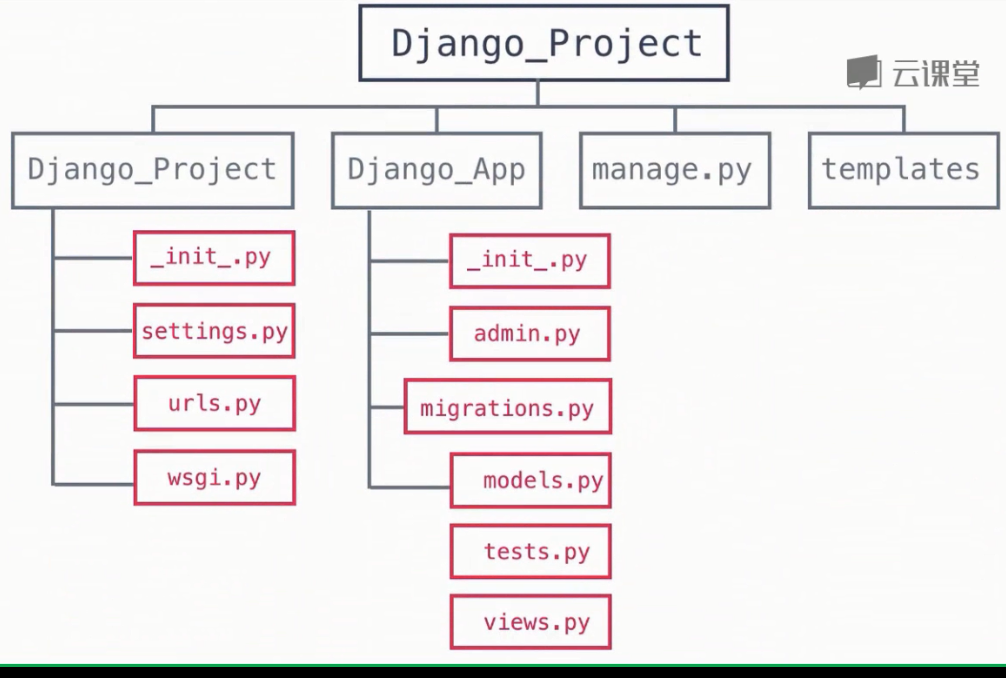
创建流程:
- 建立虚拟环境
- 启动应用,python manage.py startapp django_web
- 总设置里面添加应用
- 添加模板,templates里面建新文件
- 在view里面调用视图函数
- urls里面分配网址(正则模糊匹配),先引入库
- 运行服务,python manage.py runserver,修改后重新启动
- 访问正确网址
- static文件位置放对,根目录,引用样式,获取静态文件,修改总设置
-
STATICFILES_DIRS=(os.path.join(BASE_DIR,'static'),)
模板语言:
- 理解上下文 render函数,模板填空content,原文改造 {{ }}
- model,数据结构
- 分页工具(数据分页加载)
-
Semantic UI 模板框架
-
Semantic UI Gird布局 ,jQuery生成图标
- 模板继承,减少代码重写
-
pymongo来操作MongoDB数据库,但是直接把对于数据库的操作代码都写在脚本中,这会让应用的代码耦合性太强,而且不利于代码的优化管理,一般应用都是使用MVC框架来设计的,为了更好地维持MVC结构,需要把数据库操作部分作为model抽离出来,这就需要借助MongoEngine
MongoEngine是一个对象文档映射器(ODM),相当于一个基于SQL的对象关系映射器(ORM),MongoEngine提供的抽象是基于类的,创建的所有模型都是类
静态替换:{% %},动态替换{{ }}
分页器