概述
该文概要介绍了一些神经网络模型如何应用到NLP相关的任务上,对于想使用神经网络技术来解决NLP相关任务的初学者非常有帮助,可以当做一个综述文章来读。主要介绍以下几个主要知识点:
1. 神经网络问题建模和求解
2. NLP问题建模
3. NLP中应用的神经网络结构
4. 总结
神经网络问题建模
用机器学习模型解决实际问题时,需要解决三个主要问题输入输出是什么(如何表示)?如何选择模型?如何求解模型参数?
神经网络、深度学习模型也是机器学习中的一种,也需要解决以上问题。深度学习的主要优势能够表示任何线性、非线性模型,并且能自动学习特征,方便使用。
特征表示
对于神经网络模型输入常常为固定大小的向量,输出为连续性数值或者离散类别。
对于NLP问题,常用的特征包括词特征(前后左右不同距离位置的词)、POS(词性)以及一些语言特征等。
对于这些核心特征的表示主要有稀疏和稠密两种表现形式即one-hot和embedding。其主要区别显而易见:
1)one-hot,假设特征为M维度,每一个维度代表一个特征,如果该特征存在则值为1.稀疏并且特征之间相互独立
2)Embeding方法将每一维度特征表示为一个D维度的向量,向量之间可能存在语义或者结构上的相似度。
NLP特征表示问题
- 特征长度不固定,由于NLP主要针对文本而文本长度不一致常常需要将变长特征向量表示为固定长度向量。常常有两种表示方式
- CBOW:将词向量进行累加或者求平均值。
CBOW(f1,f2...fk)=1k∑ki=1v(fi) - WCBOW:不同特征加权方式不一致,可以和TF_IDF共同使用。
WCBOW(f1,f2...fk)=1∑kj=1wj∑ki=1wiv(fi)
- CBOW:将词向量进行累加或者求平均值。
- 位置特征:某些辅助特征和核心特征的相对位置相关,距离核心特征越近特征越强。可以将位置和特征一起训练得到位置相关的词向量表示,由于其稀疏性训练复杂度和存储比较高,往往通过其他方式加入位置相关信息,例如CNN、RNN等。
- 特征组合:对于线性特征常常收工进行特征组合来提升模型效果,也有模型本身支持特征组合,例如FM、FFM等。对于SVM等可以使用核函数进行特征变换等。对于神经网络结构可以自动进行特征抽取,可以不用关注特征组合。
- 向量共享:可以通过模型级联以及多任务学习来共享某些特征,从而学习特征的分布式表示。
前向神经网络(FNN)
FNN作为最简单的网络结构,是其他网络结构的基础。
一个典型的神经网络如下图所示。
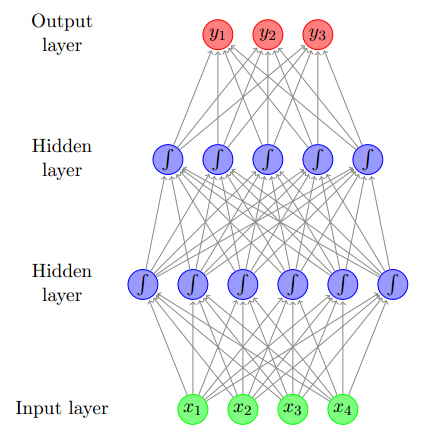
对于一个神经网络需要关注其输入层、隐藏层、输出层。对于多层网络结构会有多个隐藏层。网络结构包括线性变换、非线性变换以及输出变换。
对于类似网络结构也称之为完全连接层或者仿射层。
网络表示
可以参考之前博客,一般网络结果有两次遍历,前向遍历求解节点值和后向遍历进行梯度传播
非线性变换
常用非线性变换有:
1. sigmoid
2. tanh
3. Hard tanh
4. ReLU
其中ReLu表现比tanh好,tanh比sigmoid表现较好。不同问题其选择也不一样,当然也可以创建自己的非线性变换。
输出变换
分类问题根据二分类和多分类进行sigmoid和softmax变换
回归问题直接线性变换
嵌入层
NLP问题常常选择词向量,对于多个特征常常有多个词向量。对于神经网络的输入可以选择将词向量进行连接或者加权平均。
损失函数
- Hinge-二分类最大边缘分类损失,
L=(y^,y)=max(0,1−y∗y^) ,即当预测和真实值相同时损失最小 - Hinge-多分类,可以将最大边缘分类扩展到多个类别
L=max(0,1−(y^t−y^k)) 其中y^t 是真实类别的输出值,y^k 是非真实类别之外最大输出值。即当真实输出最大时并且非真实类别最小时,损失最小 - LogLoss:也是最常用的损失之一,即
L=log(1+exp(−(y^t−y^k))) - 交叉熵损失:
L=−∑yilog(y^i) - Ranking loss:对于排序类问题可能没有类别之分,有的只是相对顺序,此时可以定义两个网络结构的输出的损失函数,例如margin-based损失
L(X,X′)=max(0,1−(NN(x)−NN(x′))) ,这类思想可以扩展到其他损失。
词向量
词向量即将词表示为一个稠密的低维向量,在NLP相关的任务中发挥重要的作用。
1. 随时初始化,通过均匀分布采样的方式获取,常见获取方式
2. 无监督学习:word2vec或者Glove
3. 词向量的上下文选择:无监督的词向量一般通过语言模型训练得到,即给定一个上下文预测下一个词出现的概率,根据窗口选择方式有 CBOW和SG两种方式。
4. 窗口大小的影响:窗口比较小可以学习到相同结构的语义词向量,例如狗、猫等;窗口比较大可以学习到组成结构的词向量,例如汽车、排量等;窗口扩展到整个句子或者文本时可以学习到主题表示。
字符或者字基本表示
由于未登陆词的问题一些词可能获取不到词向量,可以通过学习到字符或者字级别的表示,可以解决该问题。
神经网络训练
目前大部分的神经网络训练都是通过随机梯度下降进行学习,训练简单可并行化。
基本SGD

miniBatch SGD

SGD优化
SGD扩展可以通过SGD+Momentum或者Nesterov Momentum进行算法优化,也可以通过自适应学习率进行优化,常见的有AdaGrad、AdaDelta、RMSPorp、Adam适用于不同的网络结构
图计算抽象
神经网络结构可以抽象为图计算,即前向计算和后向梯度传播
优化trick
- 权重初始化。Xavier 初始化,即
W−U[−6√d√in+d√out,6√d√in+d√out] 。对于ReLU非线性函数,使用2din−−−√ 能够产生较好的效果。 - 梯度消减和扩展
- 神经元饱和和死节点,网络结构中值始终为1或者0称之为饱和或者死亡节点,可以通过改变初始化值和学习率进行调整。
- Shuffling
- 学习率
- 批量更新
- 正则化
NLP特殊问题
模型级联和多任务学习
模型级联:是指一个模型的输出作为另外一个模型的输入,此时可以将两者混合起来训练。
多任务学习:是指多个相关任务共同学习,共享输入层和隐藏层,不同输出层对应不同的任务,参数共享增加训练数据。
结构化预测
NLP的输出可能是序列(词性、命名实体识别以及词块化)、树(句法分析)或者图。可以选择贪心预测、搜索预测等策略
常见NLP神经网络模型
CNN
卷积神经网络常用于图像或者计算视觉中,CNN包括一个或者多个卷积层和采样层(Pooling),其中卷积层也叫做过滤器(Filtering)可以进行特征抽取。
动机
对于普通的神经网络结构,对特征进行CBOW没有考虑词的顺序。CNN**能够获取局部有效不变特征**,准确预测结果。
基础卷积层和Pooling层
卷积也称为过滤器,能够将有效特征进行保留,去掉一些无用的信息。过滤器通常表示为线性变换+非线性变换组合,相当于一个隐藏层。
1. 假设输入为
2. 过滤器将连续的K个特征串联作为输入,进行一次特征变换,线性+非线性变换,转换为R^d
3. 根据是否补足前后的空白,可以分为窄卷积(输出为n-k+1个向量)和宽卷积(n+k+1个向量)
4. 对于输出的m个向量进行Pooling操作,常见有均值或最大化
对于一维的卷积和Pooling操作示意如下:
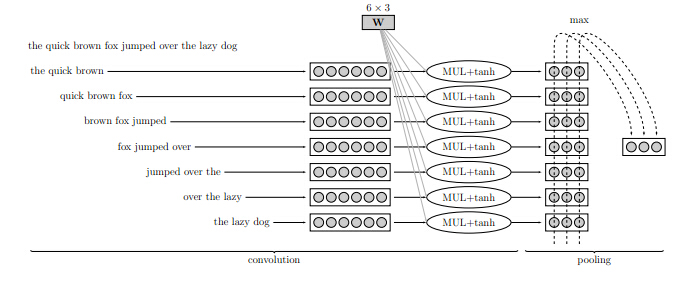
多过滤器卷积
基础的卷积层只有一个过滤器,抽取同一类特征。可以根据需求选择不同长度K,共同组成一个固定大小的输入。
示意如下
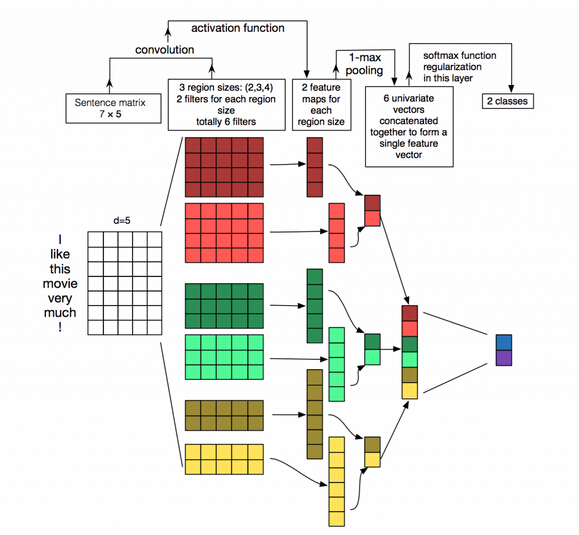
变种
K-max pooling 之前的Pooling操作只是抽取局部特征但是丢失了位置信息,此时有两种思路保持位置信息1)将卷积后的结果进行分组,每一组分别进行Pooling然后组合。2)选择K个最大值,然后进行特征串联
循环神经网络Recurrent Neural Network
序列化标注问题常常采用循环神经网络RNN,比较适合求解当前输出受历史行为、特征影响。虽然CNN也能解决词顺序问题,但是只能抽取局部特征,保证局部顺序。对于全局还是束手无策。
- RNN求解的问题可以表示为条件概率
p(e=j|x1:i) ,在给定历史x1.x2…xi去预测当前输出。RNN可以不用依赖马尔科夫假设,即可以不受历史特征个数的限制。 - RNN对于每一个输入引入状态向量s_i,此时RNN表示为
即当前输出依赖于历史状态和当前输入
RNN(s0,x1:n)=s1:n,y1:nsi=R(si−1,xi)yi=O(si) - 如果将每一层RNN进行展开,结构如下
- 具体例如:
- RNN可以解释为
- Acceptor 过滤器保留有效状态
- Encoder 编码器,将变成输入转换为定长向量
- Transducer 换能器,可以将每一层的状态输出进行串联或者均值化得到该变长输入的向量化表示
- Encoder-Decoder
- 多层RNN:深度RNN可以得到更好的效果
- BI_RNN:双向RNN,某节点的输出不仅和历史相关也可能和未来特征相关,此时可以将进行前向和后向两遍RNN,将该节点两次结果进行累加得到最终状态。实验证明该方法有效。
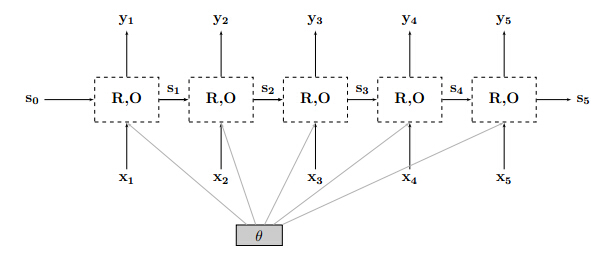
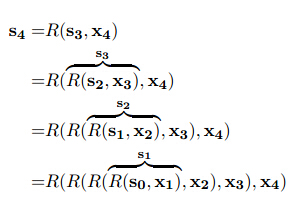
RNN网络结构
可以根据不同问题选择不同的网络结构,常见的RNN如下
简单RNN
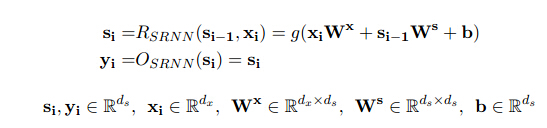
简单RNN对输入和历史状态进行线性加权
LSTM
由于简单RNN对于比较长的输入造成梯度弥减问题,LSTM引入内存单元和门组件进行弥补,使得较长的输入能有效影响后面的输出。模型结构如下:
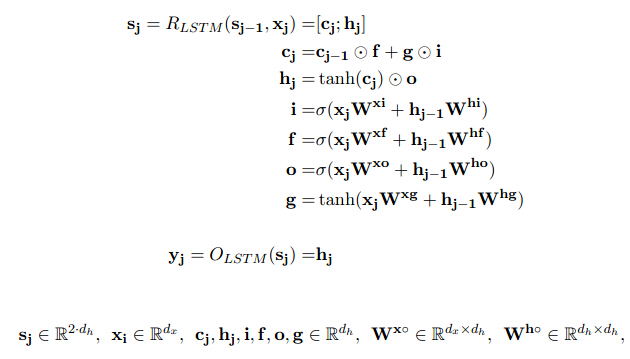
模型引入输入门(i)、遗忘门(f)和输出门(o)分别控制输入、历史状态和输出逻辑。
GRU
由于LSTM太过复杂,提出GRU(Gate Recurrent Unit)减少门的数量并能达到和LSTM可比的效果。
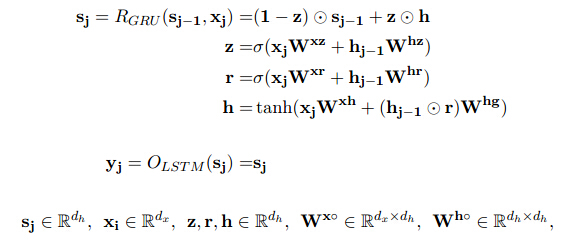
模型去掉内存单元,仅仅引入r控制历史输出和当前输入的比例;通过z控制历史状态和当前输出的比例。
递归神经网络Recursive Neural Network
循环神经网络常常用于对序列进行建模,对于树状结构需要采用递归网络建模,能有效表示网络结构。
示例表示
递归神经网络的输入是序列的树状表示以及相关节点输出状态。通常用(i,k, j)表示一个无标签的树,其中(i,k)为左子树,(k+1,j)为右子树。用(A->B,C ,i,k,j)六元组表示带标签的树,其中ABC分别表示根节点、左右子树的标签。
例如对于输入树状结构和标签状态
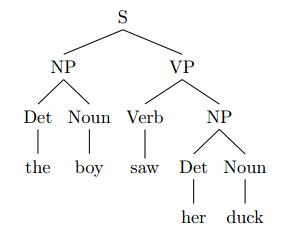
可以表示为
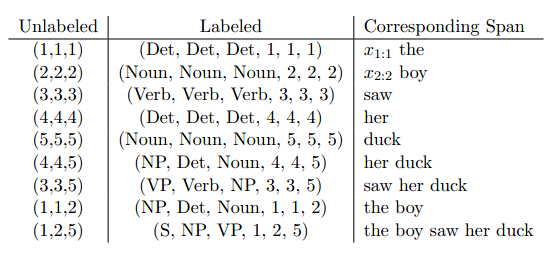
树中的每一个节点都可以表示为一个R^d的向量,左右子树到根节点需要进行一个非线性变换得到,即将R^2d -> R^d
结论
本文作为神经网络求解NLP问题的入门,需要了解
1. 前向神经网络的经典架构
2. 不同神经网络结构适用范围以及优劣
3. 不同神经网络可以相互使用,但是能够达到的效果不一样。具体问题还需要具体分析。