文章转自:
csrf介绍:
https://www.cnblogs.com/shytong/p/5308667.html
http://www.cnblogs.com/hyddd/archive/2009/04/09/1432744.html
https://www.cnblogs.com/cxying93/p/6035031.html
xss介绍:
https://www.cnblogs.com/digdeep/p/4695348.html
CSRF攻击原理及防御
一、CSRF攻击原理
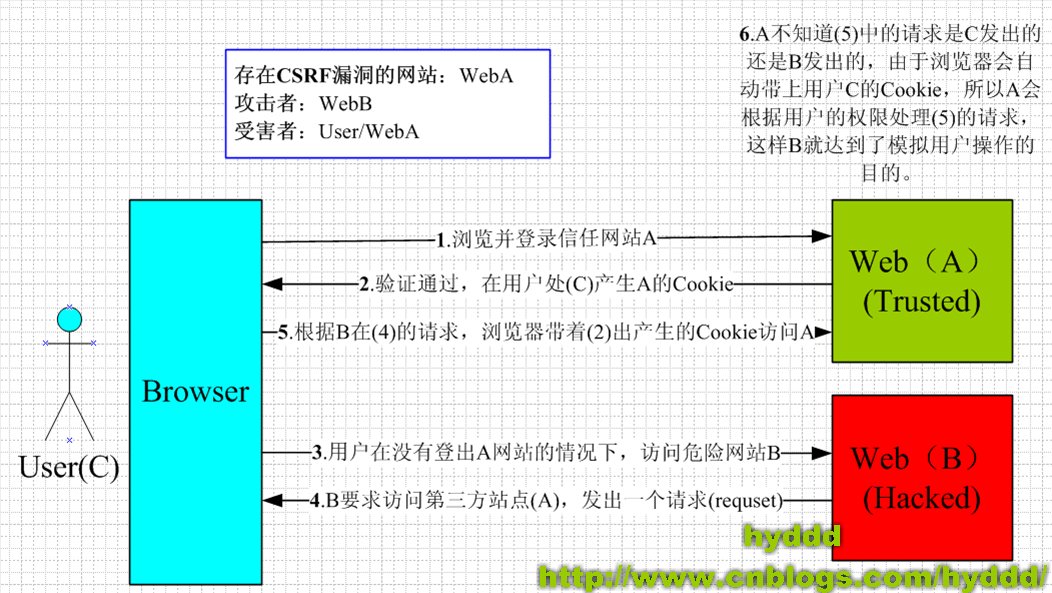
CSRF是什么呢?CSRF全名是Cross-site request forgery,是一种对网站的恶意利用,CSRF比XSS更具危险性。想要深入理解CSRF的攻击特性我们有必要了解一下网站session的工作原理。
session我想大家都不陌生,无论你用.net或PHP开发过网站的都肯定用过session对象,然而session它是如何工作的呢?如果你不清楚请往下看。
先问个小问题:如果我把浏览器的cookie禁用了,大家认为session还能正常工作吗?
答案是否定的,我在这边举个简单的例子帮助大家理解session。
比如我买了一张高尔夫俱乐部的会员卡,俱乐部给了我一张带有卡号的会员卡。我能享受哪些权利(比如我是高级会员卡可以打19洞和后付费喝饮料,而初级会员卡只能在练习场挥杆)以及我的个人资料都是保存在高尔夫俱乐部的数据库里的。我每次去高尔夫俱乐部只需要出示这张高级会员卡,俱乐部就知道我是谁了,并且为我服务了。
这里我们的高级会员卡卡号 = 保存在cookie的sessionid;
而我的高级会员卡权利和个人信息就是服务端的session对象了。
我们知道http请求是无状态的,也就是说每次http请求都是独立的无关之前的操作的,但是每次http请求都会将本域下的所有cookie作为http请求头的一部分发送给服务端,所以服务端就根据请求中的cookie存放的sessionid去session对象中找到该会员资料了。
当然session的保存方法多种多样,可以保存在文件中,也可以内存里,考虑到分布式的横向扩展我们还是建议把它保存在第三方媒介中,比如redis或者mongodb。
我们理解了session的工作机制后,CSRF也就很容易理解了。CSRF攻击就相当于恶意用户A复制了我的高级会员卡,哪天恶意用户A也可以拿着这张假冒的高级会员卡去高尔夫俱乐部打19洞,享受美味的饮料了,而我在月底就会收到高尔夫俱乐部的账单!
了解CSRF的机制之后,危害性我相信大家已经不言而喻了,我可以伪造某一个用户的身份给其好友发送垃圾信息,这些垃圾信息的超链接可能带有木马程序或者一些欺骗信息(比如借钱之类的),如果CSRF发送的垃圾信息还带有蠕虫链接的话,那些接收到这些有害信息的好友万一打开私信中的连接就也成为了有害信息的散播着,这样数以万计的用户被窃取了资料种植了木马。整个网站的应用就可能在瞬间奔溃,用户投诉,用户流失,公司声誉一落千丈甚至面临倒闭。曾经在MSN上,一个美国的19岁的小伙子Samy利用css的background漏洞几小时内让100多万用户成功的感染了他的蠕虫,虽然这个蠕虫并没有破坏整个应用,只是在每一个用户的签名后面都增加了一句“Samy 是我的偶像”,但是一旦这些漏洞被恶意用户利用,后果将不堪设想,同样的事情也曾经发生在新浪微博上面。
举例:
CSRF攻击的主要目的是让用户在不知情的情况下攻击自己已登录的一个系统,类似于钓鱼。如用户当前已经登录了邮箱,或bbs,同时用户又在使用另外一个,已经被你控制的站点,我们姑且叫它钓鱼网站。这个网站上面可能因为某个图片吸引你,你去点击一下,此时可能就会触发一个js的点击事件,构造一个bbs发帖的请求,去往你的bbs发帖,由于当前你的浏览器状态已经是登陆状态,所以session登陆cookie信息都会跟正常的请求一样,纯天然的利用当前的登陆状态,让用户在不知情的情况下,帮你发帖或干其他事情。

二、CSRF防御
- 通过 referer、token 或者 验证码 来检测用户提交。
- 尽量不要在页面的链接中暴露用户隐私信息。
- 对于用户修改删除等操作最好都使用post 操作 。
- 避免全站通用的cookie,严格设置cookie的域。
基于 Token 的身份验证方法
使用基于 Token 的身份验证方法,在服务端不需要存储用户的登录记录。大概的流程是这样的:
- 客户端使用用户名跟密码请求登录
- 服务端收到请求,去验证用户名与密码
- 验证成功后,服务端会签发一个 Token,再把这个 Token 发送给客户端
- 客户端收到 Token 以后可以把它存储起来,比如放在 Cookie 里或者 Local Storage 里
- 客户端每次向服务端请求资源的时候需要带着服务端签发的 Token
- 服务端收到请求,然后去验证客户端请求里面带着的 Token,如果验证成功,就向客户端返回请求的数据
参考:https://segmentfault.com/q/1010000004869663/a-1020000004870005
1. XSS攻击原理
XSS原称为CSS(Cross-Site Scripting),因为和层叠样式表(Cascading Style Sheets)重名,所以改称为XSS(X一般有未知的含义,还有扩展的含义)。XSS攻击涉及到三方:攻击者,用户,web server。用户是通过浏览器来访问web server上的网页,XSS攻击就是攻击者通过各种办法,在用户访问的网页中插入自己的脚本,让其在用户访问网页时在其浏览器中进行执行。攻击者通过插入的脚本的执行,来获得用户的信息,比如cookie,发送到攻击者自己的网站(跨站了)。所以称为跨站脚本攻击。XSS可以分为反射型XSS和持久性XSS,还有DOM Based XSS。(一句话,XSS就是在用户的浏览器中执行攻击者自己定制的脚本。)
1.1 反射型XSS
反射性XSS,也就是非持久性XSS。用户点击攻击链接,服务器解析后响应,在返回的响应内容中出现攻击者的XSS代码,被浏览器执行。一来一去,XSS攻击脚本被web server反射回来给浏览器执行,所以称为反射型XSS。
特点:
1> XSS攻击代码非持久性,也就是没有保存在web server中,而是出现在URL地址中;
2> 非持久性,那么攻击方式就不同了。一般是攻击者通过邮件,聊天软件等等方式发送攻击URL,然后用户点击来达到攻击的;
1.2 持久型XSS
区别就是XSS恶意代码存储在web server中,这样,每一个访问特定网页的用户,都会被攻击。
特点:
1> XSS攻击代码存储于web server上;
2> 攻击者,一般是通过网站的留言、评论、博客、日志等等功能(所有能够向web server输入内容的地方),将攻击代码存储到web server上的;
有时持久性XSS和反射型XSS是同时使用的,比如先通过对一个攻击url进行编码(来绕过xss filter),然后提交该web server(存储在web server中), 然后用户在浏览页面时,如果点击该url,就会触发一个XSS攻击。当然用户点击该url时,也可能会触发一个CSRF(Cross site request forgery)攻击。
1.3 DOM based XSS
基于DOM的XSS,也就是web server不参与,仅仅涉及到浏览器的XSS。比如根据用户的输入来动态构造一个DOM节点,如果没有对用户的输入进行过滤,那么也就导致XSS攻击的产生。过滤可以考虑采用esapi4js。
参见:http://www.freebuf.com/articles/web/29177.html , http://www.zhihu.com/question/26628342/answer/33504799
2. XSS 存在的原因
XSS 存在的根本原因是,对URL中的参数,对用户输入提交给web server的内容,没有进行充分的过滤。如果我们能够在web程序中,对用户提交的URL中的参数,和提交的所有内容,进行充分的过滤,将所有的不合法的参数和输入内容过滤掉,那么就不会导致“在用户的浏览器中执行攻击者自己定制的脚本”。
但是,其实充分而完全的过滤,实际上是无法实现的。因为攻击者有各种各样的神奇的,你完全想象不到的方式来绕过服务器端的过滤,最典型的就是对URL和参数进行各种的编码,比如escape, encodeURI, encodeURIComponent, 16进制,10进制,8进制,来绕过XSS过滤。那么我们如何来防御XSS呢?
3. XSS 攻击的防御
XSS防御的总体思路是:对输入(和URL参数)进行过滤,对输出进行编码。
也就是对提交的所有内容进行过滤,对url中的参数进行过滤,过滤掉会导致脚本执行的相关内容;然后对动态输出到页面的内容进行html编码,使脚本无法在浏览器中执行。虽然对输入过滤可以被绕过,但是也还是会拦截很大一部分的XSS攻击。
3.1 对输入和URL参数进行过滤(白名单和黑名单)
下面贴出一个常用的XSS filter的实现代码:

public class XssFilter implements Filter {
public void init(FilterConfig config) throws ServletException {}
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
XssHttpServletRequestWrapper xssRequest = new XssHttpServletRequestWrapper((HttpServletRequest)request);
chain.doFilter(xssRequest, response);
}
public void destroy() {}
}
public class XssHttpServletRequestWrapper extends HttpServletRequestWrapper {
HttpServletRequest orgRequest = null;
public XssHttpServletRequestWrapper(HttpServletRequest request) {
super(request);
orgRequest = request;
}
/**
* 覆盖getParameter方法,将参数名和参数值都做xss过滤。<br/>
* 如果需要获得原始的值,则通过super.getParameterValues(name)来获取<br/>
* getParameterNames,getParameterValues和getParameterMap也可能需要覆盖
*/
@Override
public String getParameter(String name) {
String value = super.getParameter(xssEncode(name));
if (value != null) {
value = xssEncode(value);
}
return value;
}
/**
* 覆盖getHeader方法,将参数名和参数值都做xss过滤。<br/>
* 如果需要获得原始的值,则通过super.getHeaders(name)来获取<br/>
* getHeaderNames 也可能需要覆盖
*/
@Override
public String getHeader(String name) {
String value = super.getHeader(xssEncode(name));
if (value != null) {
value = xssEncode(value);
}
return value;
}
/**
* 将容易引起xss漏洞的半角字符直接替换成全角字符
*
* @param s
* @return
*/
private static String xssEncode(String s) {
if (s == null || s.isEmpty()) {
return s;
}
StringBuilder sb = new StringBuilder(s.length() + 16);
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
switch (c) {
case '>':
sb.append('>');// 全角大于号
break;
case '<':
sb.append('<');// 全角小于号
break;
case '\'':
sb.append('‘');// 全角单引号
break;
case '\"':
sb.append('“');// 全角双引号
break;
case '&':
sb.append('&');// 全角
break;
case '\\':
sb.append('\');// 全角斜线
break;
case '#':
sb.append('#');// 全角井号
break;
case '%': // < 字符的 URL 编码形式表示的 ASCII 字符(十六进制格式) 是: %3c
processUrlEncoder(sb, s, i);
break;
default:
sb.append(c);
break;
}
}
return sb.toString();
}
public static void processUrlEncoder(StringBuilder sb, String s, int index){
if(s.length() >= index + 2){
if(s.charAt(index+1) == '3' && (s.charAt(index+2) == 'c' || s.charAt(index+2) == 'C')){ // %3c, %3C
sb.append('<');
return;
}
if(s.charAt(index+1) == '6' && s.charAt(index+2) == '0'){ // %3c (0x3c=60)
sb.append('<');
return;
}
if(s.charAt(index+1) == '3' && (s.charAt(index+2) == 'e' || s.charAt(index+2) == 'E')){ // %3e, %3E
sb.append('>');
return;
}
if(s.charAt(index+1) == '6' && s.charAt(index+2) == '2'){ // %3e (0x3e=62)
sb.append('>');
return;
}
}
sb.append(s.charAt(index));
}
/**
* 获取最原始的request
*
* @return
*/
public HttpServletRequest getOrgRequest() {
return orgRequest;
}
/**
* 获取最原始的request的静态方法
*
* @return
*/
public static HttpServletRequest getOrgRequest(HttpServletRequest req) {
if (req instanceof XssHttpServletRequestWrapper) {
return ((XssHttpServletRequestWrapper) req).getOrgRequest();
}
return req;
}
}
然后在web.xml中配置该filter:
<filter>
<filter-name>xssFilter</filter-name>
<filter-class>com.xxxxxx.filter.XssFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>xssFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
主要的思路就是将容易导致XSS攻击的边角字符替换成全角字符。< 和 > 是脚本执行和各种html标签需要的,比如 <script>,& 和 # 以及 % 在对URL编码试图绕过XSS filter时,会出现。我们说对输入的过滤分为白名单和黑名单。上面的XSS filter就是一种黑名单的过滤,黑名单就是列出不能出现的对象的清单,一旦出现就进行处理。还有一种白名单的过滤,白名单就是列出可被接受的内容,比如规定所有的输入只能是“大小写的26个英文字母和10个数字,还有-和_”,所有其他的输入都是非法的,会被抛弃掉。很显然如此严格的白名单是可以100%拦截所有的XSS攻击的。但是现实情况一般是不能进行如此严格的白名单过滤的。
对于输入,处理使用XSS filter之外,对于每一个输入,在客户端和服务器端还要进行各种验证,验证是否合法字符,长度是否合法,格式是否正确。在客户端和服务端都要进行验证,因为客户端的验证很容易被绕过。其实这种验证也分为了黑名单和白名单。黑名单的验证就是不能出现某些字符,白名单的验证就是只能出现某些字符。尽量使用白名单。
3.2 对输出进行编码
在输出数据之前对潜在的威胁的字符进行编码、转义是防御XSS攻击十分有效的措施。如果使用好的话,理论上是可以防御住所有的XSS攻击的。
对所有要动态输出到页面的内容,通通进行相关的编码和转义。当然转义是按照其输出的上下文环境来决定如何转义的。
1> 作为body文本输出,作为html标签的属性输出:
比如:<span>${username}</span>, <p><c:out value="${username}"></c:out></p>
<input type="text" value="${username}" />
此时的转义规则如下:
< 转成 <
> 转成 >
& 转成 &
" 转成 "
' 转成 '
2> javascript事件
<input type="button" onclick='go_to_url("${myUrl}");' />
除了上面的那些转义之外,还要附加上下面的转义:
\ 转成 \\
/ 转成 \/
; 转成 ;(全角;)
3> URL属性
如果 <script>, <style>, <imt> 等标签的 src 和 href 属性值为动态内容,那么要确保这些url没有执行恶意连接。
确保:href 和 src 的值必须以 http://开头,白名单方式;不能有10进制和16进制编码字符。
4. HttpOnly 与 XSS防御
XSS 一般利用js脚步读取用户浏览器中的Cookie,而如果在服务器端对 Cookie 设置了HttpOnly 属性,那么js脚本就不能读取到cookie,但是浏览器还是能够正常使用cookie。(下面的内容转自:http://www.oschina.net/question/12_72706)
一般的Cookie都是从document对象中获得的,现在浏览器在设置 Cookie的时候一般都接受一个叫做HttpOnly的参数,跟domain等其他参数一样,一旦这个HttpOnly被设置,你在浏览器的 document对象中就看不到Cookie了,而浏览器在浏览的时候不受任何影响,因为Cookie会被放在浏览器头中发送出去(包括ajax的时 候),应用程序也一般不会在js里操作这些敏感Cookie的,对于一些敏感的Cookie我们采用HttpOnly,对于一些需要在应用程序中用js操作的cookie我们就不予设置,这样就保障了Cookie信息的安全也保证了应用。
如果你正在使用的是兼容 Java EE 6.0 的容器,如 Tomcat 7,那么 Cookie 类已经有了 setHttpOnly 的方法来使用 HttpOnly 的 Cookie 属性了。
| 1 |
|
设置完后生成的 Cookie 就会在最后多了一个 ;HttpOnly
另外使用 Session 的话 jsessionid 这个 Cookie 可通过在 Context 中使用 useHttpOnly 配置来启用 HttpOnly,例如:
| 1 2 |
|
也可以在 web.xml 配置如下:
| 1 2 3 4 5 |
|
对于 不支持 HttpOnly 的低版本java ee,可以手动设置(比如在一个过滤器中):
String sessionid = request.getSession().getId();
response.setHeader("SET-COOKIE", "JSESSIONID=" + sessionid + "; HttpOnly"); 对于 .NET 2.0 应用可以在 web.config 的 system.web/httpCookies 元素使用如下配置来启用 HttpOnly?
| 1 |
|
而程序的处理方式如下:
C#:
| 1 2 3 |
|
VB.NET:
| 1 2 3 |
|
.NET 1.1 只能手工处理:
| 1 |
|
PHP 从 5.2.0 版本开始就支持 HttpOnly
| 1 |
|
PS: 实际测试在 Tomcat 8.0.21 中在 web.xml 和 context中设置 HttpOnly 属性不起作用。只有cookie.setHttpOnly(true); 和
response.setHeader("SET-COOKIE", "JSESSIONID=" + sessionid+ "; HttpOnly"); 起作用。
参考链接:https://www.owasp.org/index.php/HttpOnly#Using_Java_to_Set_HttpOnly
5. 总结下
XSS攻击访问方法:对输入(和URL参数)进行过滤,对输出进行编码;白名单和黑名单结合;
--------------------------------------------分割线----------------------------------------------------
6. 使用 OWASP AntiSamy Project 和 OWASP ESAPI for Java 来防御 XSS(还有客户端的esapi4js: esapi.js)
上面说到了防御XSS的一些原理和思想,对输入进行过滤,对输出进行编码。那么OWASP组织中项目 AntiSamy 和 ESAPI 就恰恰能够帮助我们。其中 AntiSamy 提供了 XSS Filter 的实现,而 ESAPI 则提供了对输出进行编码的实现。(samy是一个人名,他第一次在MySpace上实现第一个XSS工具蠕虫,所以AntiSamy项目就是反XSS攻击的意思; ESAPI就是enterprise security api的意思;owasp: Open Web Application Securtiy Project)
使用maven可以引入依赖包:
<dependency>
<groupId>org.owasp.antisamy</groupId>
<artifactId>antisamy</artifactId>
<version>1.5.3</version>
</dependency>
<dependency>
<groupId>org.owasp.esapi</groupId>
<artifactId>esapi</artifactId>
<version>2.1.0</version>
</dependency>
使用AntiSamy构造XSS Filter的方法如下:
 XssFilter
XssFilter
XssRequestWrapper
然后在web.xml中配置:
web.xml
上面我们不仅对输入进行扫描过滤,而且设置了response中sessionId的httponly属性,我们看下httponly的实际效果:

我们看到baidu使用了httponly=true,我们的localhost的httponly=true也其作用了。
ESAPI 编码输出,使用方法入下:
ESAPI.encoder().encodeForHTML(String input);
ESAPI.encoder().encodeForHTMLAttribute(String input);
ESAPI.encoder().encodeForJavaScript(String input);
ESAPI.encoder().encodeForCSS(String input);
ESAPI.encoder().encodeForURL(String input);
MySQLCodec codec = new MySQLCodec(Mode.STANDARD);
ESAPI.encoder().encodeForSQL(codec, String input);
对应上面 3.2 中说到的编码输出。encodeForSQL 用于 防御 MySQL 的 sql 注入。
(压缩版的esapi-compressed.js,大小为51K。)
-----------------------------------------------------
低危漏洞- X-Frame-Options Header未配置
X-Frame-Options 响应头
X-Frame-Options HTTP 响应头是用来给浏览器指示允许一个页面可否在 <frame>, </iframe> 或者 <object> 中展现的标记。网站可以使用此功能,来确保自己网站的内容没有被嵌到别人的网站中去,也从而避免了点击劫持 (clickjacking) 的攻击。
使用 X-Frame-Options
X-Frame-Options 有三个值:
DENY
表示该页面不允许在 frame 中展示,即便是在相同域名的页面中嵌套也不允许。
SAMEORIGIN
表示该页面可以在相同域名页面的 frame 中展示。
ALLOW-FROM uri
表示该页面可以在指定来源的 frame 中展示。
换一句话说,如果设置为 DENY,不光在别人的网站 frame 嵌入时会无法加载,在同域名页面中同样会无法加载。另一方面,如果设置为 SAMEORIGIN,那么页面就可以在同域名页面的 frame 中嵌套。
配置 Apache
配置 Apache 在所有页面上发送 X-Frame-Options 响应头,需要把下面这行添加到 ‘site’ 的配置中:
Header always append X-Frame-Options SAMEORIGIN配置 nginx
配置 nginx 发送 X-Frame-Options 响应头,把下面这行添加到 ‘http’, ‘server’ 或者 ‘location’ 的配置中:
add_header X-Frame-Options SAMEORIGIN;配置 IIS
配置 IIS 发送 X-Frame-Options 响应头,添加下面的配置到 Web.config 文件中:
<system.webServer>
...
<httpProtocol>
<customHeaders>
<add name="X-Frame-Options" value="SAMEORIGIN" />
</customHeaders>
</httpProtocol>
...
</system.webServer>结果
在 Firefox 尝试加载 frame 的内容时,如果 X-Frame-Options 响应头设置为禁止访问了,那么 Firefox 会用 about:blank 展现到 frame 中。也许从某种方面来讲的话,展示为错误消息会更好一点。
Tomcat处理:
定义一个过滤器filter,在HTTP请求头中加入x-frame-options: SAMEORIGIN即可。
最后补充代码:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
|
进行配置:
| 1 2 3 4 5 6 7 8 |
|
进行验证生效:


区别:
https://blog.csdn.net/qq_24797461/article/details/71104089
https://www.cnblogs.com/maggie-pan/p/6392167.html
(1)CSRF比XSS漏洞危害更高。
(2)CSRF可以做到的事情,XSS都可以做到。
(3)XSS有局限性,而CSRF没有局限性。
(4)XSS针对客户端,而CSRF针对服务端。
(5)XSS是利用合法用户获取其信息,而CSRF是伪造成合法用户发起请求。
关于http头部信息: