之前看过一次AdaBoost分类模型,现在结合大神的讲解准备自己从头理解一下。主要包含一下几个方面:
1.泰勒展开式
2.AdaBoost算法思想
3.指数损失函数的意义
4.迭代权重参数的求解
1.泰勒展开式
泰勒公式是将一个在x=x0处具有n阶导数的函数f(x)利用关于(x-x0)的n次多项式来逼近函数的方法。
若函数f(x)在包含x0的某个闭区间[a,b]上具有n阶导数,且在开区间(a,b)上具有(n+1)阶导数,则对闭区间[a,b]上任意一点x,成立下式:

其中Rn(x)为误差项。其中皮亚诺误差项:
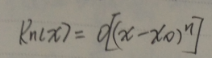
将函数ex在x0=0处展开:

2.AdaBoost模型思想
采用集成学习方式进行分类,采用多个基学习器的输出组合来实现最终分类。一般采用基学习器的加权平均来实现组合。
![]()
每个学习器的权重需要根据预测结果来进行调整:

每个样本的权重分布也需要根据分类结果进行调整:

整体算法流程如下:

3.指数损失函数的意义
在导出AdaBoost权重迭代式的过程中使用指数损失函数,在此指数损失函数与0--1损失是一致的。
第t轮输出为前几轮的加权平均:
![]()
在样本分布D下,希望指数损失函数的期望最小:
![]()
L对于H求导等于零:
![]()
解之得:
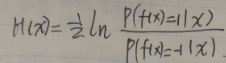
最终输出:

由指数损失函数期望最小,可以导出最优的H即为最优分类器,分类错误率最小,即可达到指数损失函数期望最小
4.迭代权重参数求解
数据样本在Dt分布下,调节参数使指数函数期望最小:

分类错误率的定义:
![]()
有:
![]()
L对于alphat求导等于零:

以上便是第k个基学习器的权重系数。
现在求Dt的迭代公式:
由于:


由于f(x) ht(x)输出为1或-1,有:

泰勒展开式有:


最优的ht学习器要满足:

![]() 为一常数,不会影响最终结果。
为一常数,不会影响最终结果。
令Dt表示分布:

对Dt(f(x)h(x))求期望:

最优ht(x)等价于:
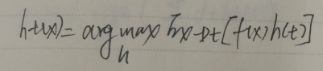
![]()
最优ht分类器如下:即错误期望最小

求解Dt+1与Dt关系:

最后一项为常数,不影响结果,进行归一化如下:

以上便是样本权重的迭代式。
参考地址: