从今天开始进入深度学习领域,深度学习我在前两年的理论学习过程中,体会颇深,其中主要有两个算法CNN和RNN,但是本人喜欢追本溯源,喜欢刨根问题。最重要的是每个算法并不是拍脑袋想出来的,是根据当时的研究进程和研究环境有关,因此想要深入理解深度学习的精髓,我们需要去了解,深度学习因为什么被提出来的,解决了什么问题,为什么能解决问题以及这个算法和机器学习有什么本质的区别等等。想要回答这些问题,就不能上来就学习CNN和RNN,我们需要寻找问题的根源,通过引入问题,然后为了解决这个问题在引入深度学习,这时候才符合我们的认知规律,而不是本末倒置,本末倒置的后果是对算法理解的不深,更不会使用这个算法,当然时间长了自然理解,但是这总归没有体系化,你说呢?学习知识不在于你学了多少,而是在于你内化多少,遇到问题时能输出多少,这才是最有效率的学习。在这里我计划从最简单的问题开始,一步步深入下去,直到CNN和RNN,然后针对这两个算法再好好的实战,当然,一旦这两个算法学好以后就可以多学习这两个算法的衍生算法,因此理解很重要,内化更重要,到公司以后知识的输出更重要。好,废话不多说,今天就开始,本节主要介绍神经网络的总体的模型,介绍不同的学习规则,这些规则在以后的文章中都会使用到,所以请大家多留心。
在机器学习中,我们知道有监督学习,无监督学习和半监督学习,在神经网络中分为监督学习、无监督学习和灌输式学习。
监督学习也叫有导师学习,这种学习模式采用纠错规则,即需要给网络不断输入数据,把神经网络输出和期望输出的相比较,当两者不同时,根据差错方向和大小按一定规则调整权值,以使下一步网络更接近期望结果,一旦当网络对于各种给定的输入均能参数所期望的输出时,即认为网络学会了,就可以用来工作了。
无监督学习也叫无导师学习,学习过程中需要不断的给网络提供动态的输入信息,网络能根据特有的内部结构和学习规则,再输入的信息中去发现任何可能存在的模式和规律,同时能根据网络的功能和输入信息调整权值,这个过程称为网络的自组织,其结果就是使网络能对属于同一类的模式进行自动的分类,在这种学习模式中,网络的权值调整不取决于外来的教师信号,而是取决于网络的内部。
灌输式学习是指将网络设计成能记忆特别的例子,以后当给定有关该例子的输入信息时,例子便会被回忆起来。网络权值一旦设计好就不在变动,因此学习是一次性的而不是一个训练过程。
下面给出神经网络权值调整的通用规则,该规则是由日本著名神经网络学者Amari与1990年提出的:

上图中神经元j是神经网络中的某个节点,其输入用向量表示,该输入可以是来自网络的外部,也可以来自其他神经元的输出。第i个输入与神经元j的连接权值用
表示,连接到神经元j的全部权值构成了权向量
,其中
对应神经元的阈值,对应的输入分量x0恒为-1,图中
代表学习信号(r是regulation的缩写即学习规则),该信号通常是
和
的函数,如果是监督学习则也会有
(desired,期望的缩写)信号。
通用学习规则的表达式为:
权向量的在t时刻的调整量
与t时刻的输入向量
和学习信号r乘积成正比,用数学表达式为:
式子中的为正数,称为学习常数,其值决定了学习的速率,下一时刻的权向量应为:
不同的学习规则对有不同的意义,也是形成不同的神经网络的原因,因此下面将重点介绍这些学习规则,这些规则是网络的学习本质,请大家好好体会,我也会尽可能的讲解深入,同时这些规则在后面的网络中都会使用,例如BP等。
1.Hebb学习规则
1949年,心理学家D.O.Hebb最早提出了关于神经网络学习机理的‘突触修正’的假设。当神经元i与神经元j同时处于兴奋状态时,两者之间的连接强度应增强。
在Hebb学习规则中,学习信号简单的等于神经元的输出:
权向量的调整公式为:
权向量中,每个分量的调整由下式确定:
从上式可以看出。权值调整向量与输入输出乘积成正比,因此经常出现的输入模式对权向量影响很大,因此需要预先设置权饱和值,防止权值无限增长。
2.Perceptron学习规则
1958年,美国学者Frank Rosenblatt 首次提出感知器,感知器的学习规则也由此诞生,该规则规定,学习信号等于神经元期望输出与实际输出的之差:
式中,为期望输出,
,感知器采用符号函数作为转移函数,其表达式为;
因此权值调整公式为:
从上式我们可以看到,当实际输出和期望值值相同时,权值不调整,反之调整,权值调整公式可化简为:
感知器学习规则只适用于二进制神经元,初值可任取。
3.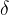 学习规则
学习规则
1986年,认知心理学家McClelland 和 Rumelhart在神经网络训练中引入了规则,该规则称为连续感知器学习规则,与上面的离散感知器类似,
规则的学习信号规定为:
上式的学习信号称为,式中
是转移函数
的导数,显然
规则要求激活函数可导。如Sigmoid函数
事实,规则可以通过输出值和期望值的最小平方误差推倒。定义神经元输出值与期望值的最小平方误差为:
其中,误差E是权向量的函数,为了使E最小,
应与误差的负梯度成正比即:
其中,梯度为:
权值调整公式为:
由此可看到上式的中间项和r是相同的,因此它是根据梯度进行迭代更新的,BP就是使用这个学习规则。
4.LMS学习规则
1962年BernardWrow和Marcian Hoff提出了Widrow-Hoff学习规则,因为它能使神经元实际输出与期望输出之间的平方差最小,所以又称为最小均方规则(LMS),学习规则如下定义:
权向量的调整量为:
的各分量为:
实际上,LMS是学习规则的一种特殊情况,如果是
,则
,此时
学习规则的学习规则就是LMS的学习规则,该学习规则好处是不需要对激活函数求导,学习速度快,精度较高。
5.Corrclation学习规则
Correlation(相关)学习规则规定学习信号为:
得到和
分别为:
该规则表明,当dj是xi的期望输出时,相应的权值增量就是期望和输入的乘积。
如果Hebb学习规则中的转移函数为二进制函数,且有,则相关学习规则可看着Hebb的一种特殊情况。
6. Winner - Take - All学习规则
Winner - Take - All(胜者为王)学习规则是一种竞争关系的学习规则,用于无监督学习,一般将网络的某一层确定为竞争层,对于一个特定的输入x,竞争层的所有的p个神经元均有输出响应,其中响应值最大的神经元为在竞争中获胜的神经元,即:
只有获胜的神经元才有权调整其向量Wm,调整量为:
由于两个向量的点积越大,表明两者越相近,所以调整获胜神经元权值的结果是使wm进一步接近当前输入x,显然下次出现与x相似的输入模式时,上次获胜的神经元更容易获胜,在反复的竞争学习中,竞争层的个各神经元所对应的权向量被逐渐调整为输入样本空间的聚类中心。
还有一个是外星节点学习规则,上面这个为内星学习规则,外星和其类似。
下面给出对比列表:

各个学习之间并不是完全独立的,这几个学习规则在下面的神经网络中都会用到,到时再细讲,下一节就开始讲BP,大家就知道了。刚开始看这些东西可能感觉不理解,大家只需知道有这个学习规则就行,等学习具体的神经网络时就一且明朗了,好本节到此结束,下一节开始BP神经网络。