参考: 静觅scrapy教程
爬取目标:顶点小说网 http://www.23us.com/

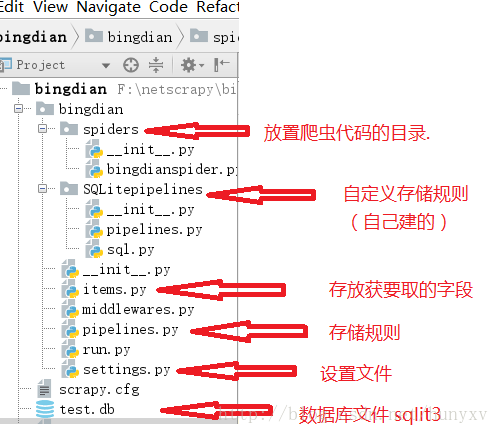
首先来编写items.py
#-*- coding:utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class BingdianItem(scrapy.Item):
name = scrapy.Field()
#小说名
author = scrapy.Field()
#作者
novelurl = scrapy.Field()
#小说地址
serialstatus = scrapy.Field()
#状态
serialnumber = scrapy.Field()
#连载字数
category = scrapy.Field()
#文章类别
name_id = scrapy.Field()
#小说编号
class DcontentItem(scrapy.Item):
id_name = scrapy.Field() #小说编号
chaptercontent = scrapy.Field() #章节内容
num = scrapy.Field() #用于绑定章节顺序
chapterurl = scrapy.Field() #章节地址
chaptername = scrapy.Field() #章节名字spider文件
#bingdian.py
#-*- coding:utf-8 -*-
import scrapy
# import re
# from bs4 import BeautifulSoup
# from scrapy.http import Response
from bingdian.items import BingdianItem ,DcontentItem
from bingdian.SQLitepipelines.sql import Sql
class bingdian_spider(scrapy.Spider):
name = 'bingdian'
allowed_domains = ['23us.com']
start_urls = [
'http://www.23us.com/class/1_1.html',
'http://www.23wx.com/class/2_1.html',
'http://www.23wx.com/class/3_1.html',
'http://www.23wx.com/class/4_1.html',
'http://www.23wx.com/class/5_1.html',
'http://www.23wx.com/class/6_1.html',
'http://www.23wx.com/class/7_1.html',
'http://www.23wx.com/class/8_1.html',
'http://www.23wx.com/class/9_1.html',
'http://www.23wx.com/class/10_1.html'
]
def parse(self,response):
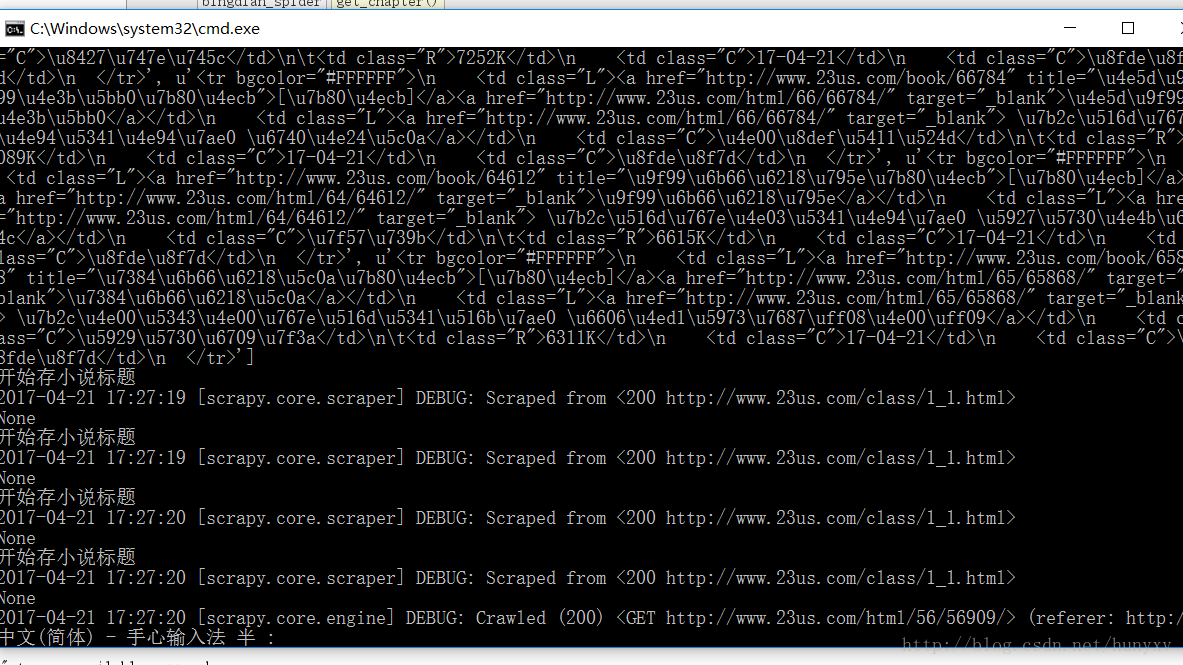
books = response.xpath('//dd/table/tr[@bgcolor="#FFFFFF"]')#/table/tbody/tr[@bgcolor="#FFFFFF"]
print (books.extract())
for book in books:
name = book.xpath('.//td[1]/a[2]/text()').extract()[0]
author = book.xpath('.//td[3]/text()').extract()[0]
novelurl = book.xpath('.//td[1]/a[2]/@href').extract()[0]
serialstatus = book.xpath('.//td[6]/text()').extract()[0]
serialnumber = book.xpath('.//td[4]/text()').extract()[0]
category = book.xpath('//dl/dt/h2/text()').re(u'(.+) - 文章列表')[0]
jianjieurl = book.xpath('.//td[1]/a[1]/@href').extract()[0]
item = BingdianItem()
item['name'] = name
item['author'] = author
item['novelurl'] = novelurl
item['serialstatus'] = serialstatus
item['serialnumber'] = serialnumber
item['category'] = category
item['name_id'] = jianjieurl.split('/')[-1]
yield item
yield scrapy.Request(novelurl,callback = self.get_chapter,meta = {'name_id' : item['name_id']})
next_page = response.xpath('//dd[@class="pages"]/div/a[12]/@href').extract()[0] #获取下一页地址
if next_page:
yield scrapy.Request(next_page)
#获取章节名
def get_chapter(self,response):
num = 0
allurls = response.xpath('//tr')
for trurls in allurls:
tdurls = trurls.xpath('.//td[@class="L"]')
for url in tdurls:
num = num + 1
chapterurl = response.url + url.xpath('.//a/@href').extract()[0]
chaptername = url.xpath('.//a/text()').extract()[0]
rets = Sql.select_chapter(chapterurl)
if rets[0] == 1:
print(u'章节已经存在了')
pass
else:
yield scrapy.Request(url = chapterurl,callback = self.get_chaptercontent,meta={'num':num,
'name_id':response.meta['name_id'],
'chaptername':chaptername,
'chapterurl':chapterurl})
#获取章节内容
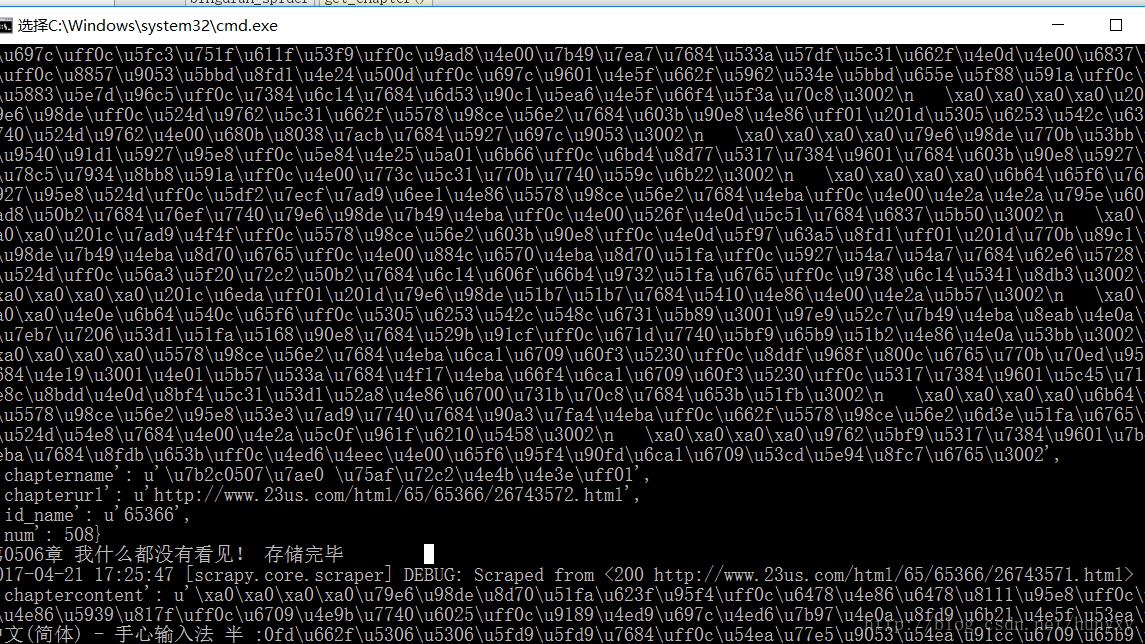
def get_chaptercontent(self,response):
item = DcontentItem()
item['num'] = response.meta['num']
item['id_name'] = response.meta['name_id']
item['chaptername'] = response.meta['chaptername']
item['chapterurl'] = response.meta['chapterurl']
content = response.xpath('//dd[@id="contents"]/text()').extract()
item['chaptercontent'] = '\n '.join(content)
return itemname:
定义spider名字的字符串(string)。spider的名字定义了Scrapy如何定位(并初始化)spider,所以其必须是唯一的。 不过您可以生成多个相同的spider实例(instance),这没有任何限制。 name是spider最重要的属性,而且是必须的。
allowed_domains:
可选。包含了spider允许爬取的域名(domain)列表(list)。 当 OffsiteMiddleware 启用时, 域名不在列表中的URL不会被跟进。
parse():
是spider的一个方法。Request()默认回调函数(可以通过传递callback=(函数名)修改回调函数,例如后面的get_chapter()函数)。被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
修改settings.py文件
ITEM_PIPELINES = {
# 'bingdian.pipelines.BingdianPipeline': 300,
'bingdian.SQLitepipelines.pipelines.BingdingPipeline' : 1 #启用自定义pipelines 1 是优先级程度(1-1000随意设置,数值越低,组件的优先级越高)
}#pipelines.py
#-*- coding:utf-8 -*-
from .sql import Sql
from bingdian.items import BingdianItem,DcontentItem
class BingdingPipeline(object):
def process_item(self,item,spider):
if isinstance(item,BingdianItem):
name_id = item['name_id']
ret = Sql.select_name(name_id)
if ret[0] == 1:
print('已经存在了')
pass
else:
xs_name = item['name']
xs_author = item['author']
category = item['category']
Sql.insert_dd_name(xs_name,xs_author,category,name_id)
print(u'开始存小说标题')
if isinstance(item,DcontentItem):
url = item['chapterurl']
name_id = item['id_name']
num_id = item['num']
xs_chaptername = item['chaptername']
xs_content = item['chaptercontent']
Sql.insert_dd_chaptername(xs_chaptername,xs_content,name_id,num_id,url)
print(u'%s 存储完毕') % xs_chaptername
return itemsql操作文件
#-*- coding:utf-8 -*-
import sqlite3
conn = sqlite3.connect('test.db')
cursor = conn.cursor()
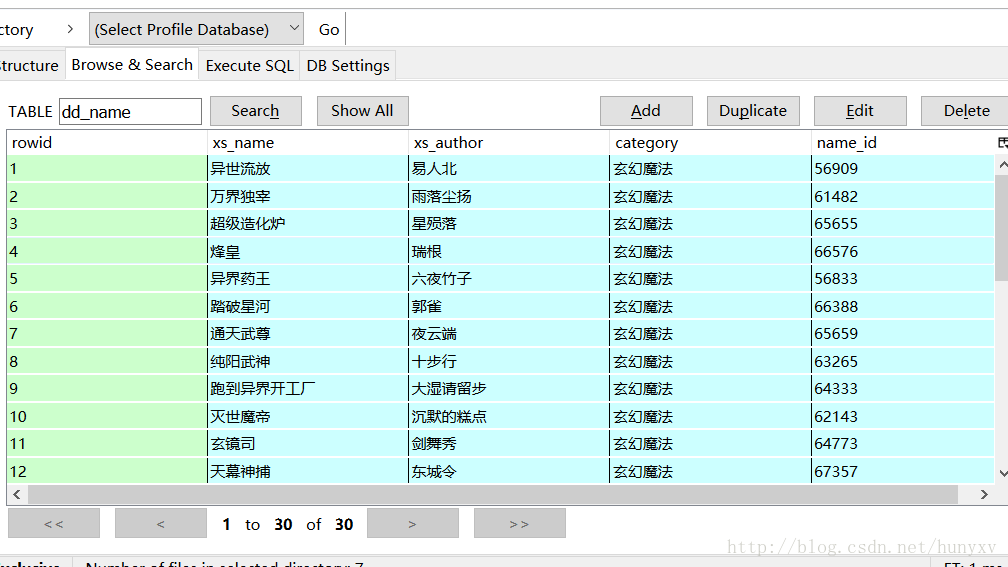
#创建 dd_name 表
cursor.execute('DROP TABLE IF EXISTS dd_name')
cursor.execute('create table dd_name(xs_name VARCHAR (255) DEFAULT NULL ,xs_author VARCHAR (255),category VARCHAR (255),name_id VARCHAR (255))')
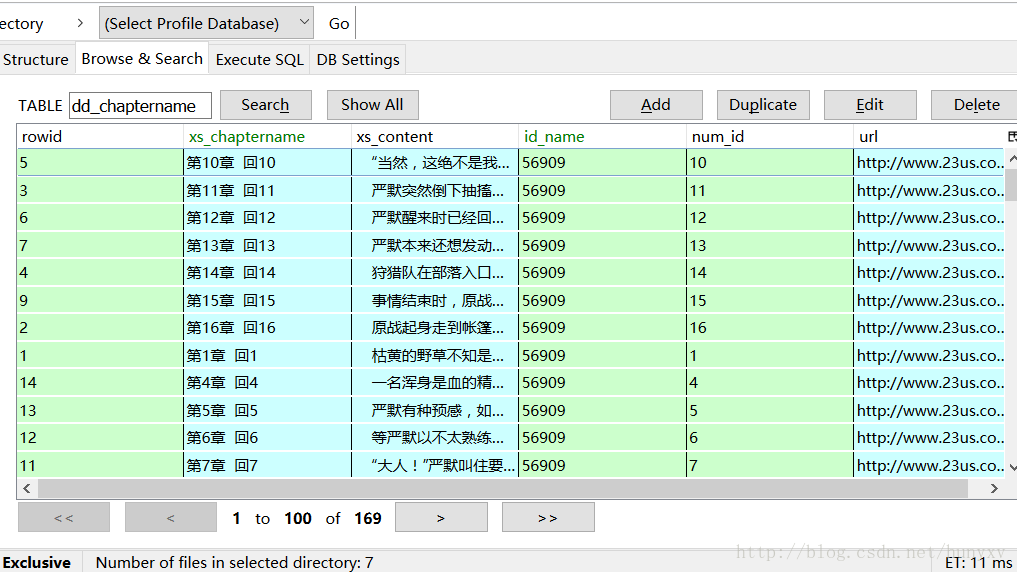
#创建 dd_chaptername 表
cursor.execute('DROP TABLE IF EXISTS dd_chaptername')
cursor.execute('''CREATE TABLE dd_chaptername(xs_chaptername VARCHAR(255) DEFAULT NULL ,xs_content TEXT,id_name INT(11) DEFAULT NULL,
num_id INT(11) DEFAULT NULL ,url VARCHAR(255))''')
class Sql:
#插入数据
@classmethod
def insert_dd_name(cls,xs_name,xs_author,category,name_id):
# sql = "insert into dd_name (xs_name,xs_author,category,name_id) values (%(xs_name)s , %(xs_author)s , %(category)s , %(name_id)s)"
sql = "insert into dd_name (xs_name,xs_author,category,name_id) values ('%s','%s','%s','%s')" % (xs_name,xs_author,category,name_id)
cursor.execute(sql)
conn.commit()
#查重
@classmethod
def select_name(cls,name_id):
sql = "SELECT EXISTS (select 1 from dd_name where name_id = '%s')" % name_id
cursor.execute(sql)
return cursor.fetchall()[0]
@classmethod
def insert_dd_chaptername(cls,xs_chaptername,xs_content,id_name,num_id,url):
sql = '''INSERT INTO dd_chaptername(xs_chaptername , xs_content , id_name ,num_id ,
url) VALUES ('%s' ,'%s' ,%s ,%s ,'%s')''' % (xs_chaptername,xs_content,id_name,num_id,url)
cursor.execute(sql)
conn.commit()
@classmethod
def select_chapter(cls,url):
sql = "SELECT EXISTS (select 1 from dd_chaptername where url = '%s')" % url
cursor.execute(sql)
return cursor.fetchall()[0]