对于某些问题,其特征的表述极其困难,比如人脸的识别,其影响因素可能涉及到角度,光影,颜色,形状等。深度学习旨在将原复杂的映射关系分解成一系列嵌套的简单映射。
一、深度前馈网络简要
深度前馈网络又称多层感知机(MLP),对于分类器,函数 将输入
映射到类别
上。而MLP定义了一个映射
,通过学习参数
,以达到最佳近似
的效果。由于模型的输出和模型本身没有反馈连接,所以称作前馈神经网络,例如卷积神经网络(在之后的文章中会详细说明,本次先说明神经网络的基础部分)。而被扩展为包含反馈连接的,称作循环神经网络(后续文章会陆续涉及)。
二、深层神经网络的直观理解
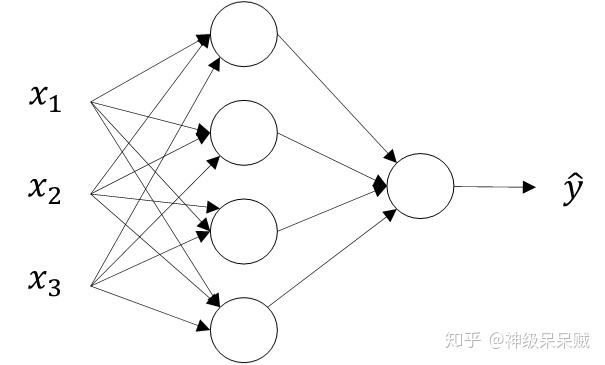
深层神经网络(Deep Neural Network)模型图
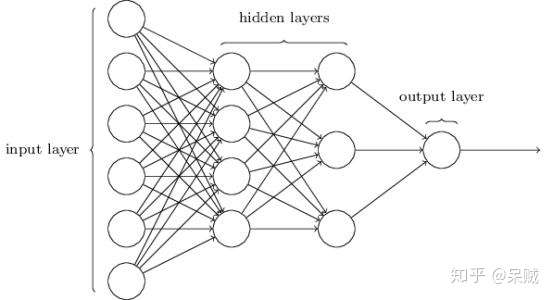
神经网络分为三层:输入层、隐藏层、输出层。网络模型通过一个有向无环图关联,图中描述了各节点(函数)如何复合在一起
深度学习中,网络即意味着将很多不同的函数复合在一起,以能达到表示复杂问题的能力。
网络模型通过一个有向无环图关联,图中描述了各节点(函数)如何复合在一起能得到最佳的函数的近似效果。整个网络工作的流程从图中反应就是,变量 的特征属性导入至输入层,通过隐藏层内部的计算,从输出层导出输出结果
,再经过比对
与
,不断地从函数集群中选取合适函数(简单但不准确地理解就是:调整参数
),以能更好地近似
。
网络模型中含有很多层次,每个层次可以抽象成函数 ,其中
表示当前层数,相对于最开始的模型图,可以得到一个链式结构:
,对于某层来说,上层的输出作为该层的输入。
三、神经节点
网络模型中含有多个节点,这形象的称作"神经元",又称"神经节点"。神经节点的意义其实就类似于之前提到的多个函数复合(这里是神经节点之间通过某种规则互连),而单个神经节点又是最基本的函数。除输入层外,每个神经节点根据功能的划分一般有线性函数和激活函数两大部分(当然不是绝对的)。仅通过线性函数难以去表述某些非线性问题,这可以从XOR实例中很好地体现。从线性代数的角度上理解,线性变换一般只能在该向量空间中表示某些情况,对于高维度的信息,则难以表达,因此需要通过激活函数跳转至更高维的向量空间。单个神经元节点如下图所示:
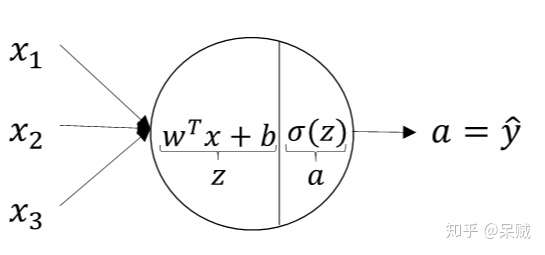
上图中 属于线性部分,
为上层的输出,作为本层的输入。之后经过一个激活函数
,因此每个神经元的信息主要包括有参数
和选取哪个激活函数。
四、激活函数
激活函数负责将神经节点的输入映射到输出端上,如果不使用激活函数,那么无论神经网络有多少层,都是输入的线性组合,因此不能解决非线性问题。
列举一些常用的激活函数:
Sigmoid:

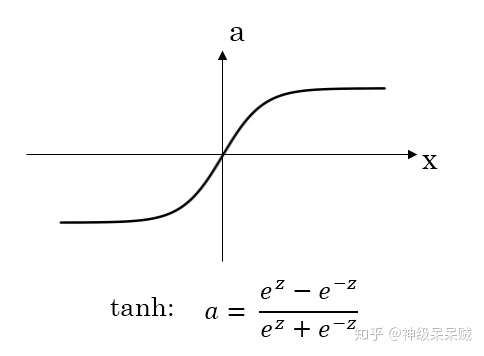
双曲正切:
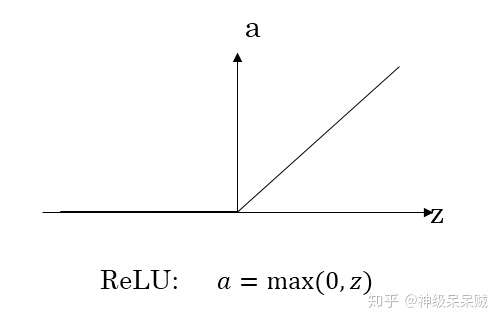
线性整流:
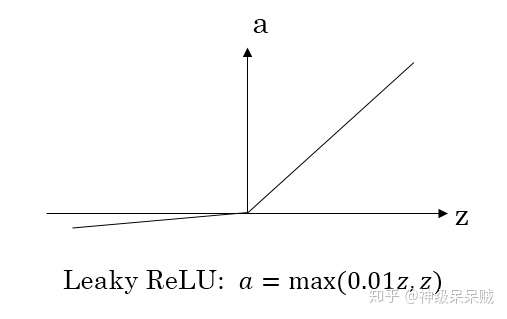
渗漏整流线性:
softmax:
五、代价函数
1.代价函数概述
网络模型通过学习算法,在数据集上训练模型,发掘 的映射关系。引入代价函数评估算法性能,为学习算法指明优化方向。这样来说,参数模型经过训练样本定义了一个分布
,所以使用最大似然原理估计模型参数。
2.交叉熵代价函数
以二分类问题为例,其符合伯努利分布,对样本 有:
因此样本 的分布律是:
由似然函数:
为了构建近似样本真实的概率分布,需要取似然函数的最大值,因此对似然函数两边取对数并乘以-1,即最小化下面的式子:
该式子称作交叉熵代价函数,常用作二分类问题,此时神经网络输出层一般会选择Sigmoid作为激活函数。观察上式,直观地理解下,当出现预测错误,交叉熵代价函数的值将会变得非常大。
3.对数释然代价函数
对于多分类问题,输出层一般会选择softmax作为激活函数。此时代价函数一般选择对数释然代价函数,对共有 个类别问题有:
注意:这里为什么不选择均方误差代价函数的原因在于,使用均方误差代价函数容易造成softmax和sigmoid运算单元的饱和现象,这样不利于基于梯度的学习方法,使用上述函数可以消去函数中的指数运算从而有利于梯度学习过程。
六、正向传播
神经网络的训练过程主要分为正向传播和反向传播过程。
1.正向传播
假定输入矩阵 ,即有
个样本,
个特征值。正向传播过程中,对于第
层(第0层为输入层),有:
其中 表示第
层激活函数。当传至输出层时,此时:
2.正向传播示例
假设网络模型如下图所示,网络共有 层
输入矩阵维度表示成:
对于第 层:
第一层向第二层传播过程:
第二层向第三层传播过程:
七、反向传播

反向传播是根据代价函数通过链式求导算得,以上图的网络模型图作为示例,此处是针对二分类问题(选用交叉熵代价函数,输出层激活函数sigmoid):
正向传播过程:
反向传播过程:
表示点乘
表示矩阵乘法
一次循环开始-----------------------------------------
(这里解释一下为什么乘以 ,因为在正向传播中,
的矩阵乘法过程相当于将
样本的结果压缩到矩阵
中,反向传播过程可看成一个逆向的过程)
一次循环结束-----------------------------------------
所以,整个反向传播算法的过程:
八、代码
为了更清晰的表示这些传播过程,下面使用python代码来具体体现(来自Andrew ng 作业):
import numpy as np
def sigmoid(Z):
cache = Z
A = 1.0 / (1 + np.exp(-Z))
assert(A.shape == Z.shape)
return A, cache
def sigmoid_derivative(dA,cache):
Z = cache
f = 1.0 / (1 + np.exp(-Z))
dZ = dA * f * (1 - f)
assert(dZ.shape == Z.shape)
return dZ
def ReLU(Z):
cache = Z
A = np.maximum(0, Z)
assert(A.shape == Z.shape)
return A, cache
def ReLU_derivative(dA,cache):
Z = cache
dZ = np.array(dA, copy = True)
dZ[Z <= 0] = 0
assert(dZ.shape == Z.shape)
return dZ
# 初始化参数
def initialize_parameters(layer):
np.random.seed(1)
parameters = {}
L = len(layer)
for i in range(1,L):
parameters["W" + str(i)] = np.random.randn(layer[i], layer[i-1]) * np.sqrt(1 / layer[i-1])
parameters["b" + str(i)] = np.zeros((layer[i], 1))
assert(parameters["W" + str(i)].shape == (layer[i], layer[i-1]))
assert(parameters["b" + str(i)].shape == (layer[i], 1))
return parameters
# 正向线性化
def linear_forward(A_prev, W, b):
Z = np.dot(W, A_prev) + b
assert(Z.shape == (W.shape[0], A_prev.shape[1]))
cache = (A_prev, W, b)
return Z,cache
# 正向激活
def linear_forward_activation(A_prev, W, b, activation_function):
if activation_function == 'sigmoid':
Z, linear_cache = linear_forward(A_prev, W, b)
A, activation_cache = sigmoid(Z)
elif activation_function == 'ReLU':
Z, linear_cache = linear_forward(A_prev, W, b)
A, activation_cache = ReLU(Z)
assert(A.shape == (W.shape[0], A_prev.shape[1]))
cache = (linear_cache, activation_cache)
return A, cache
# 正向传播
def L_model_forward(X, parameters):
A = X
L = len(parameters) // 2
caches = []
# 输入层与隐藏层正向传播
for i in range(1, L):
A_prev = A
A, cache = linear_forward_activation(A_prev, parameters['W' + str(i)], parameters['b' + str(i)], 'ReLU')
caches.append(cache)
# 输出层正向传播
AL, cache = linear_forward_activation(A, parameters['W' + str(L)], parameters['b' + str(L)],'sigmoid')
caches.append(cache)
assert(AL.shape == (1, X.shape[1]))
return AL, caches
# 计算成本函数
def compute_cost(AL, Y):
m = Y.shape[1]
cost = -np.sum(np.multiply(np.log(AL),Y) + np.multiply(np.log(1 - AL), 1 - Y)) / m
cost = np.squeeze(cost)
return cost
# 反向线性传播
def linear_backward(dZ, cache):
A_prev, W, b = cache
m = A_prev.shape[1]
dW = 1.0 / m * np.dot(dZ, A_prev.T)
db = 1.0 / m * np.sum(dZ, axis = 1, keepdims = True)
dA_prev = np.dot(W.T, dZ)
assert(dW.shape == (dZ.shape[0], A_prev.shape[0]))
assert(db.shape == db.shape)
assert(dA_prev.shape == (W.T.shape[0], dZ.shape[1]))
return dA_prev, dW, db
# 反向激活
def linear_backward_activation(dA, cache, function_activation):
linear_cache, activation_cache = cache
if function_activation == 'sigmoid':
dZ = sigmoid_derivative(dA, activation_cache)
dA_prev, dW, db = linear_backward(dZ, linear_cache)
elif function_activation == 'ReLU':
dZ = ReLU_derivative(dA, activation_cache)
dA_prev, dW, db = linear_backward(dZ, linear_cache)
return dA_prev, dW, db
# 反向传播
def L_model_backward(Y, AL, caches):
grads = {}
L = len(caches)
Y = Y.reshape(AL.shape)
dAL = -(np.divide(Y, AL) - np.divide(1-Y, 1-AL))
grads['dA' + str(L)], grads['dW' + str(L)], grads['db' + str(L)] = \
linear_backward_activation(dAL, caches[L-1], 'sigmoid')
for i in reversed(range(L - 1)):
grads['dA' + str(i + 1)], grads['dW' + str(i + 1)], grads['db' + str(i + 1)] = \
linear_backward_activation(grads['dA' + str(i + 2)], caches[i],'ReLU')
return grads
# 参数更新
def updata_parameters(parameters, grads, learning_rate):
L = len(parameters) // 2
for i in range(L):
parameters['W' + str(i + 1)] = parameters['W' + str(i + 1)] \
- learning_rate * grads['dW' + str(i + 1)]
parameters['b' + str(i + 1)] = parameters['b' + str(i + 1)] \
- learning_rate * grads['db' + str(i + 1)]
return parameters
# 输出结果评估
def predict(X, y, parameters, print_result = True):
m = X.shape[1]
p = np.zeros((1, m))
AL, caches = L_model_forward(X, parameters)
for i in range(m):
if AL[0, i] > 0.5:
p[0,i] = 1
elif AL[0, i] < 0.5:
p[0, i] = 0
if print_result == True:
print("Accuracy:" + str(np.sum(p == y) / m))
return p
# 神经网络传播
def L_layer_model(X, Y, layer, iteration, learning_rate):
costs = []
parameters = initialize_parameters(layer)
for i in range(0, iteration):
AL, caches = L_model_forward(X, parameters)
cost = compute_cost(AL, Y)
grads = L_model_backward(Y, AL, caches)
parameters = updata_parameters(parameters, grads, learning_rate)
if i % 100 == 0:
print("cost after iteration %d:%f" %(i, cost))
costs.append(cost)
plt.plot(np.squeeze(costs))
plt.xlabel('iteration')
plt.ylabel('cost')
plt.title('learning-rate:' + str(learning_rate))
plt.show()
return parameters