版权声明:点个赞,来个评论(夸我),随便转~ https://blog.csdn.net/qq_28827635/article/details/83758587
上一篇:机器学习-神经网络(一)
神经网络的代价函数
| 符号 |
意义 |
|
L |
神经网络结构总层数 |
|
Sl |
第
l 层的单元数量 (不包括偏差单元) |
|
K=SL |
输出层的单元数量 |
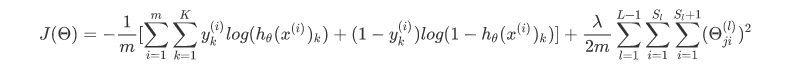
(日了个仙人板板,手写一直渲染错误只能贴图了,: ) 浪费好久时间 )
代价函数中
θ0 总是被忽略的,因为我们并不想把
θ0 加入到正则化里,也不想使它为 0,即不把偏差项正则化。
反向传播
为什么使用反向传播
在神经网路中,我们的
θ 数量居多,如果一个一个计算代价函数的偏导项再进行梯度下降计算,计算量实在是太大了,在使用梯度下降算法进行训练时速度会特别慢。因此,为了计算代价函数的偏导项,我们选择使用反向传播计算每一个神经节点激励值与期望神经节点激励值的误差,然后通过误差与神经元的激励值再次计算得出偏导项的计算结果。
思想
我们能够明白,如果输出层的输出与期望得到的输出 存在误差,那么当下的每个神经元的激励值必定与得到期望输出时的每个神经元的激励值 也存在误差,我们将使用
δj(l) 代表第
l 层的第
j 个神经元当下激励值与期望神经元的激励值之间存在的误差。
而反向传播算法从直观上说,就是从输出层开始到输入层为止,反向推导出每一个神经节点的激励值的误差
δ。
方法
使用反向传播前,也就是求代价函数的导数前,首先需要使用前向传播将每一个神经节点的激励值算出,然后从后向前计算每一个神经节点的
δ。我们还要明白的就是:我们此时只知道输出层神经节点的期望激励值,因此我们只能够从输出层开始计算。
那么,假设我们有一层输入层,一层输出层,两层隐藏层,一共四层,我们能够以
δ2(4) 表示输出层的第二个神经节点的激励值误差, 并且它的值能够通过计算得出:
δ2(4)=a2(4)−y2 ,通常我们会以向量化的形式表示整个一层的误差值 即
δ(4) =
a(4)−y。
而我们会使用这样一个公式,反向计算上一层的误差值:
δ(l−1)=(Θ(l−1))Tδ(l).∗g′(z(l−1))
如 第 3 层:
δ(3)=(Θ(3))Tδ(4).∗g′(z(3))
.∗ 代表两个向量(矩阵)对应值两两相乘。
g 代表激励函数,通过计算能够得出
g′(z(l))=a(l).∗(1−a(l))
同样的,我们能够计算出 第 2 层
δ(2) ,但是我们并不需要计算
δ(1),因为输入层是明确的已知值。
如何计算代价函数的导数项
不使用求导的方法,我们能够通过以下公式得到导数项的最终结果(忽略正则化):
∂(Θij(l))∂J(Θ)=aj(l)δi(l+1)
也就是代价函数
J(θ) 对 第
l 层 第
i 行
j 列 的
θ 求偏导
= 第
l 层 第
j 个 神经节点的激励值
a × 第
l+1 层 第
i 个 神经节点的误差值
δ
由此,我们能够很快求出 所有参数
θ 的偏导数。
但是
由于每条训练集数据都不相同,因此针对与每条数据,得到的输出层结果与期望结果也总是不同的,那么 虽然每层的参数矩阵
Θ 一直不变,但由于每条数据的每层的误差
δ 各不相同,那么每条数据的代价函数求导自然得出的值也不相同。
所以我们需要计算出针对于每层
Θ 的每条数据的代价偏导
∂(Θij(l))∂J(Θ),然后进行相加,最终得出针对
m 条数据算出的第
l 层的总体代价函数偏导值:
Δij(l) 。
所以我们能够得出代价函数针对每一个参数的平均偏导数
Dij(l) :
∂(Θij(l))∂J(Θ)=Dij(l)=m1Δij(l)
当
j=0 时,最终结果为上式。
当
j̸=0 时,最终结果应为
∂(Θij(l))∂J(Θ)=Dij(l)=m1Δij(l)+λΘij(j)
为什么取平均值:稳定性。
矩阵向量化
其实就是把矩阵写为一行。
梯度检验
本质上就是使用求斜率的方法计算出偏导项结果,然后与反向传播算法计算出的偏导项结果进行比较校验
随机初始化
为了训练神经网络,应该对权重进行随机初始化,初始化为
−ϵ<θ<ϵ 接近于0的小数,然后进行反向传播,执行梯度检验,使用梯度下降或者使用更好的优化算法试着使
J 最小。
作为参数
θ 的需要使用随机的初始值来打破对称性,使得梯度下降或是更好的优化算法找到
θ 的最优值。
关于隐藏层的层数设定与每层隐藏单元的个数设定
- 第一层的单元数即我们训练集的特征数量。
- 最后一层的单元数是我们训练集的结果的类的数量。
- 普遍地,我们会设定隐藏层的层数为 1 层。
- 如果隐藏层数大于1,确保每个隐藏层的单元个数相同,通常情况下隐藏层单元的个数越多越好。
- 一般来讲,每个隐藏层所包含的单元数量还应该和输入
x 的维度相匹配,也要和特征的数目相匹配。
- 可能隐藏单元的单元数量和输入特征的数量相同,一般来说,隐藏单元的数目取为稍大于输入特征数目。
关于神经网络的使用过程总结
- 参数的随机初始化
- 利用正向传播方法计算所有的
hθ(x)
- 编写计算代价函数 J 的代码
- 利用反向传播方法计算所有偏导数
- 利用数值检验方法检验这些偏导数
- 使用优化算法来最小化代价函数
ps
- 代价函数
J 度量的就是这个神经网络对训练数据的拟合情况。
- BP算法的基本思想是,学习过程由信号的正向传播与误差的反向传播两个过程组成。
查看更多:https://breezedawn.gitthub.io