梯度
梯度是一个矢量。
函数上某点的梯度的方向:导数最大的方向。梯度的大小(梯度的模):该点的导数的大小。
梯度下降
对于一般二次函数而言:
由于梯度的方向是导数最大的方向,顺着梯度方向走,函数值就变大的最快,顺着梯度的反方向,那么函数值减小最快的方向,导数也慢慢减小。当导数减为0时,该点极为最小值或最大值。
梯度下降算法可用来求函数的最大值最小值。
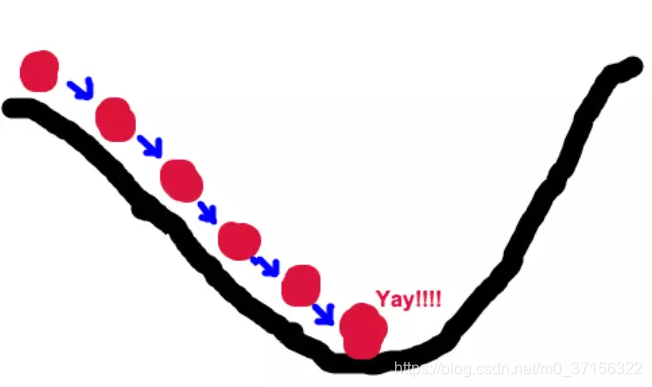
为什么要使用梯度下降算法
对于一般的线性回归方程,用最小二乘法表示其损失函数:
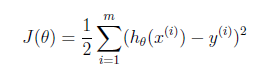
损失函数表示我们使用根据训练数据建立的线性回归模型用于测试数据得到的测试值和测试数据的真实值之前的差别。这个差别肯定越小越小。我们通过求损失函数的最小值,来获取一个能让差别最小的θ值。
对于像这样的一般的线性回归以最小二乘法表示的损失函数是一个开口向上的一元二次函数,一般我们可以通过直接对损失函数求导,让导数等于0 求得最小值。
但是对于有些回归方程的损失函数,我们无法通过解析的方法求出最小值(例如logistic回归的损失函数),所以我们需要使用梯度下降计算函数的最小值。
梯度下降算法:

其中,这就是损失函数在θ点的梯度。

α为步长用于控制每次移动的距离,也叫做学习率。θ0为初始点。
具体思路为 : 从初始点开始,迭代得往梯度反方向进行靠近。步长用于控制每次移动的大小,太小需要移动的次数过多,太大可能或跳过最小值。我们减去步长乘以梯度,就是依次靠近梯度的反方向。直到θ达到我们满意的值为止。