一、为什么使用序列模型
能处理非固定大小输入的问题,例如语音识别,DNA序列分析,机器翻译这种是一串序列的问题。
二、 数学符号表示
以自然语言处理为例:
符号
说明
X < 1 > = [ 0 , 0 , 0 , 1 , 0 , 0 , . . . , 0 , 0 ]
X
<
1
>
=
[
0
,
0
,
0
,
1
,
0
,
0
,
.
.
.
,
0
,
0
]
X < i >
X
<
i
>
表示该句话的第
i
i
个单词,在此处表示Harry在词典中序号为4。
Y < i >
Y
<
i
>
表示第
i
i
个单词的输出。
T x = 9
T
x
=
9
这个序列的长度为9
T y = 9
T
y
=
9
这个序列的输出长度为9
X ( i ) < t >
X
(
i
)
<
t
>
样本中第
i
i
个序列的第
t
t
个单词
T ( i ) x
T
x
(
i
)
样本中第
i
i
个输入序列的长度
注意:如果样本中出现了词典中不包含的单词,需要定义一个Unknown向量,以及每句话的结尾EOS向量。
三、循环神经网络模型
1 为什么不能用标准的神经网络
在序列输入问题中,大部分的输入不能输出都不能统一
在同一个单词在文本的不同位置不能分享特征
2 循环神经网络
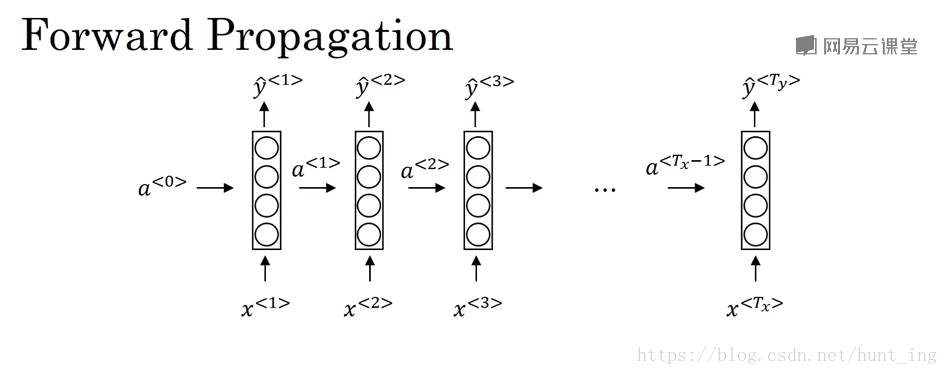
2.1 前向传播
a < t > = g 1 ( W a a a < t − 1 > + W a x x < t > + b a )
a
<
t
>
=
g
1
(
W
a
a
a
<
t
−
1
>
+
W
a
x
x
<
t
>
+
b
a
)
y ^ = g 2 ( W y a a < t > + b y )
y
^
=
g
2
(
W
y
a
a
<
t
>
+
b
y
)
公式可以简化为
a < t > = g 1 ( W a [ a < t − 1 > , x < t > ] + b a )
a
<
t
>
=
g
1
(
W
a
[
a
<
t
−
1
>
,
x
<
t
>
]
+
b
a
)
y ^ = g 2 ( W y a < t > + b y )
y
^
=
g
2
(
W
y
a
<
t
>
+
b
y
)
2.2 方向传播
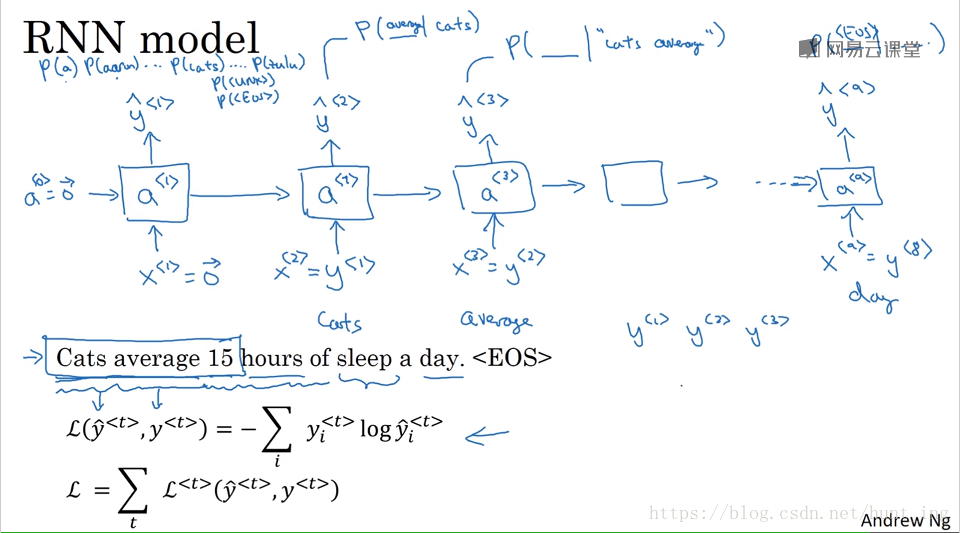
对于一个判断是否为人名的二分类问题,可以定义损失函数:
L < t > ( y ^ < t > , y < t > ) = − y < t > log y ^ < t > − ( 1 − y < t > ) log ( 1 − y ^ < t > )
L
<
t
>
(
y
^
<
t
>
,
y
<
t
>
)
=
−
y
<
t
>
log
y
^
<
t
>
−
(
1
−
y
<
t
>
)
log
(
1
−
y
^
<
t
>
)
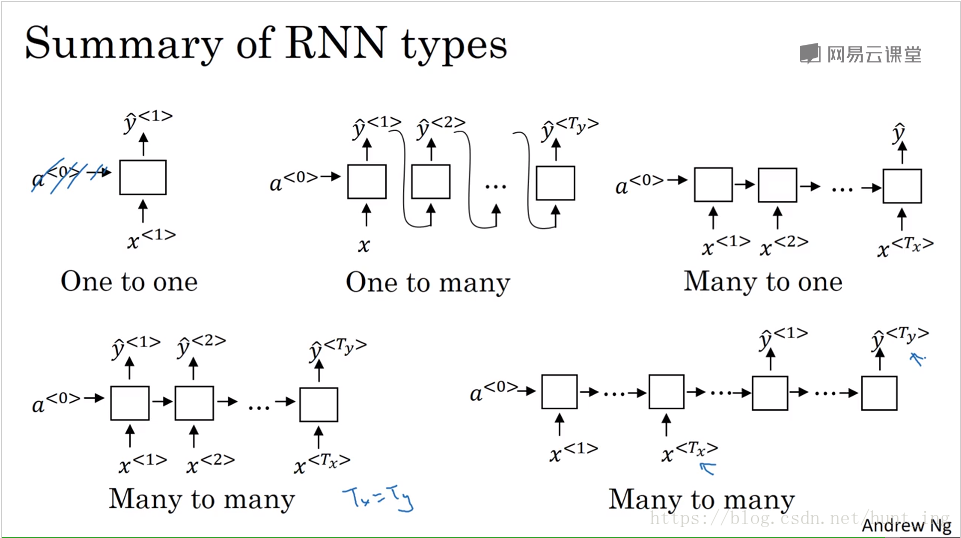
2.3 不同类型的循环神经网络
3 语言模型和序列生成
3.1 生成过程
一句话概括就是:单词出现的概率。
3.2 生成采样
通过每个单元生成的softmax概率,然后以每个单词的概率做随机,到第二个单元时以第一个单元的结果为输入,然后再生成softmax概率,如此循环直到生成EOS标志或者限定时间数。
3.3 字符模型
相比较词汇模型而言,字符模型是以字母,标点符号,数字为字典元素。相比较词汇模型而言,会得到更多的输入,网络相对更加深,训练起来计算成本也比较昂贵。
4 梯度问题
梯度爆炸:梯度修剪
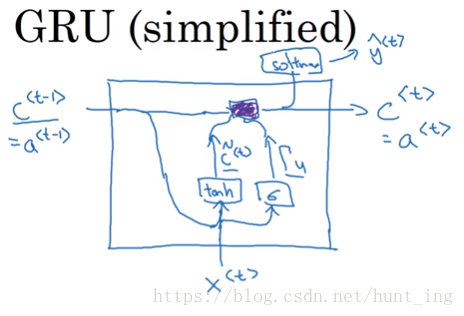
4.1 GRU(Gated Recurrent Unit 门控循环单元)
学习非常深的连接
c ^ < t > = tanh ( W c [ c < t − 1 > , x < t > ] + b c )
c
^
<
t
>
=
tanh
(
W
c
[
c
<
t
−
1
>
,
x
<
t
>
]
+
b
c
)
Γ u = σ ( W u [ c < t − 1 > , x < t > ] + b u )
Γ
u
=
σ
(
W
u
[
c
<
t
−
1
>
,
x
<
t
>
]
+
b
u
)
c < t > = Γ u ∗ c ^ < t > + ( 1 − Γ u ) ∗ c < t − 1 >
c
<
t
>
=
Γ
u
∗
c
^
<
t
>
+
(
1
−
Γ
u
)
∗
c
<
t
−
1
>
a < t > = c < t >
a
<
t
>
=
c
<
t
>
Full GRU
c ^ < t > = tanh ( W c [ Γ r ∗ c < t − 1 > , x < t > ] + b c )
c
^
<
t
>
=
tanh
(
W
c
[
Γ
r
∗
c
<
t
−
1
>
,
x
<
t
>
]
+
b
c
)
Γ u = σ ( W u [ c < t − 1 > , x < t > ] + b u )
Γ
u
=
σ
(
W
u
[
c
<
t
−
1
>
,
x
<
t
>
]
+
b
u
)
Γ r = σ ( W r [ c < t − 1 > , x < t > ] + b r )
Γ
r
=
σ
(
W
r
[
c
<
t
−
1
>
,
x
<
t
>
]
+
b
r
)
c < t > = Γ u ∗ c ^ < t > + ( 1 − Γ u ) ∗ c < t − 1 >
c
<
t
>
=
Γ
u
∗
c
^
<
t
>
+
(
1
−
Γ
u
)
∗
c
<
t
−
1
>
a < t > = c < t >
a
<
t
>
=
c
<
t
>
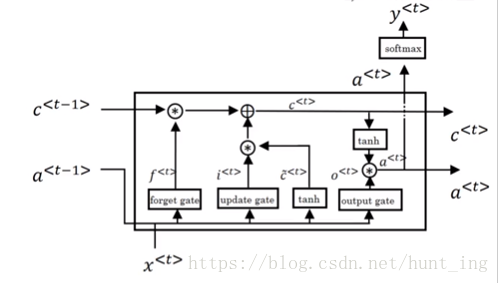
4.1 LSTM(Long Short Term Memory Unit 长短时记忆单元)
学习非常深的连接
c ^ < t > = tanh ( W c [ a < t − 1 > , x < t > ] + b c )
c
^
<
t
>
=
tanh
(
W
c
[
a
<
t
−
1
>
,
x
<
t
>
]
+
b
c
)
Γ u = σ ( W u [ a < t − 1 > , x < t > ] + b u )
Γ
u
=
σ
(
W
u
[
a
<
t
−
1
>
,
x
<
t
>
]
+
b
u
)
Γ f = σ ( W f [ a < t − 1 > , x < t > ] + b f )
Γ
f
=
σ
(
W
f
[
a
<
t
−
1
>
,
x
<
t
>
]
+
b
f
)
Γ o = σ ( W o [ a < t − 1 > , x < t > ] + b o )
Γ
o
=
σ
(
W
o
[
a
<
t
−
1
>
,
x
<
t
>
]
+
b
o
)
c < t > = Γ u ∗ c ^ < t > + Γ f ∗ c < t − 1 >
c
<
t
>
=
Γ
u
∗
c
^
<
t
>
+
Γ
f
∗
c
<
t
−
1
>
a < t > = Γ o ∗ tanh c < t >
a
<
t
>
=
Γ
o
∗
tanh
c
<
t
>
5 双向循环神经网络(Bidirectional RNN) (BRNN)
因为语言有上下文的语境关系,所以采用双向循环,是的特征信息能够保全得更加完整。
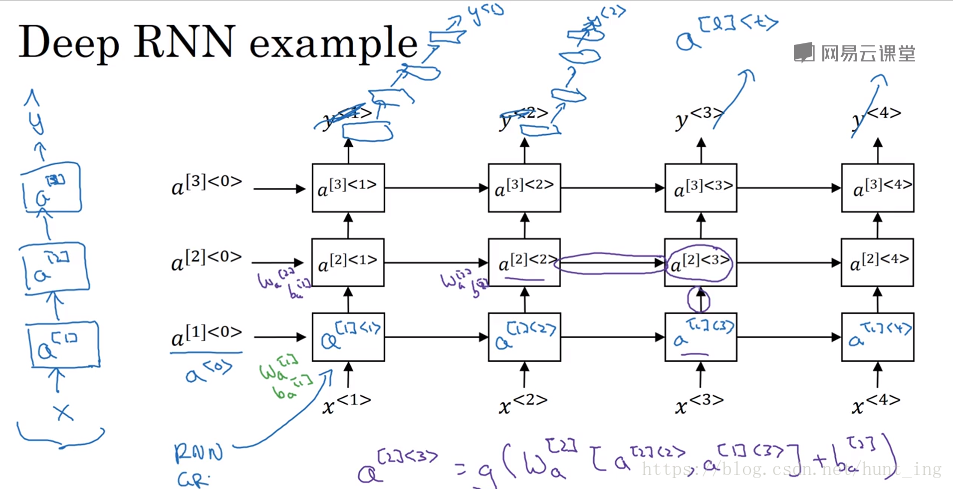
深层循环神经网络
测试题