K-means算法延伸
对于之前的一篇文章中说过K-means虽然效果可以,但是对给定的K值敏感,簇中心位置敏感以及计算量大。所以针对以上两点有了一些优化的方法。
对于给定的K值偏大或者偏小都将影响聚类效果。而由于对于需要聚类的数据本身没有一个y值即分类值,这正是需要算法最后得出的。所以一般对于不给定K值的话,可以通过canopy 算法来确定K值。
Canopy算法
Canopy算法属于一种“粗”聚类算法,执行速度较快,但精度较低,算法
执行步骤如下:
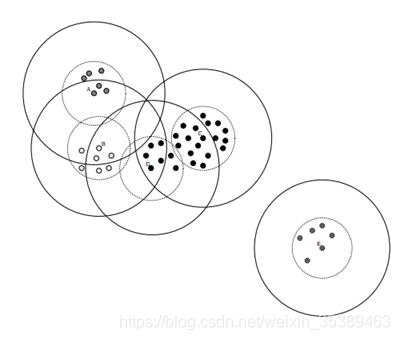
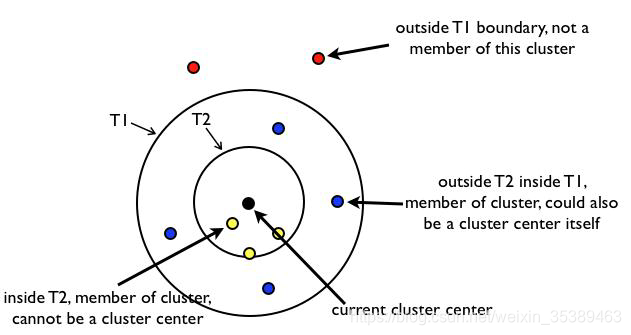
• 给定样本列表L=x1,x,2…,xm以及先验值r1和r2(r1>r2)
• 从列表L中获取一个节点P,计算P到所有聚簇中心点的距离(如果不存在聚簇中心,
那么此时点P形成一个新的聚簇),并选择出最小距离D(P,aj)
• 如果距离D小于r1,表示该节点属于该聚簇,添加到该聚簇列表中
• 如果距离D小于r2,表示该节点不仅仅属于该聚簇,还表示和当前聚簇中心点非常近,
所以将该聚簇的中心点设置为该簇中所有样本的中心点,并将P从列表L中删除
• 如果距离D大于r1,那么节点P形成一个新的聚簇,并将P从列表L中删除
• 直到列表L中的元素数据不再有变化或者元素数量为0的时候,结束循环操作
Canopy算法得到的最终结果的值,聚簇之间是可能存在重叠的,但是不会
存在某个对象不属于任何聚簇的情
Canopy算法常用应用场景
由于K-Means算法存在初始聚簇中心点敏感的问题,常用使用Canopy+K-
Means算法混合形式进行模型构建
• 先使用canopy算法进行“粗”聚类得到K个聚类中心点
• K-Means算法使用Canopy算法得到的K个聚类中心点作为初始中心点,进行“细”
聚类
• 优点:
• 执行速度快(先进行了一次聚簇中心点选择的预处理)
• 不需要给定K值,应用场景多
• 能够缓解K-Means算法对于初始聚类中心点敏感的问题
K值的问题解决了,该解决簇中心的问题了。对于簇中心的解决算法有K-Means++算法和K-Means||算法,后者是前者的更进一步改进。
K-Means++算法
•解决K-Means算法对初始簇心比较敏感的问题,K-Means++算法和K-
Means算法的区别主要在于初始的K个中心点的选择方面,K-Means算法使
用随机给定的方式,K-Means++算法采用下列步骤给定K个初始质点:
• 从数据集中任选一个节点作为第一个聚类中心
• 对数据集中的每个点x,计算x到所有已有聚类中心点的距离和D(X),基于D(X)采用
线性概率选择出下一个聚类中心点(距离较远的一个点成为新增的一个聚类中心点)
• 重复步骤2直到找到k个聚类中心点
• 缺点:由于聚类中心点选择过程中的内在有序性,在扩展方面存在着性能方
面的问题(第k个聚类中心点的选择依赖前k-1个聚类中心点的值)
K-Means||算法
解决K-Means++算法缺点而产生的一种算法;主要思路是改变每次遍历时
候的取样规则,并非按照K-Means++算法每次遍历只获取一个样本,而是
每次获取K个样本,重复该取样操作O(logn)次,然后再将这些抽样出来的
样本聚类出K个点,最后使用这K个点作为K-Means算法的初始聚簇中心点。
实践证明:一般5次重复采用就可以保证一个比较好的聚簇中心点。
看似K-means的问题几乎解决了,但是有一点不容忽视,就是计算量大。对于计算量的话,可以参照以前的梯度下降法中的小批量梯度下降法。这里也可以进行小批量的K-means算法叫做Mini Batch K-Means算法
Mini Batch K-Means算法
• Mini Batch K-Means算法是K-Means算法的一种优化变种,采用小规模的数据子集(每次
训练使用的数据集是在训练算法的时候随机抽取的数据子集)减少计算时间,同时试图优化
目标函数;Mini Batch K-Means算法可以减少K-Means算法的收敛时间,而且产生的结
果效果只是略差于标准K-Means算法
• 算法步骤如下:
• 首先抽取部分数据集,使用K-Means算法构建出K个聚簇点的模型
• 继续抽取训练数据集中的部分数据集样本数据,并将其添加到模型中,分配给距离最近的聚簇中心点
• 更新聚簇的中心点值(每次更新都只用抽取出来的部分数据集)
• 循环迭代第二步和第三步操作,直到中心点稳定或者达到迭代次数,停止计算操作
一般的话Mini Batch K-Means是 K-means算法的3倍执行速度。
说了这么多,到目前位置还没有提到衡量聚类算法好坏的指标。像监督学习还要损失函数,而聚类的话则没有损失函数之说,但是聚类算法也有几个衡量指标,比如:
• 混淆矩阵
• 均一性
• 完整性
• V-measure
• 调整兰德系数(ARI)
• 调整互信息(AMI)
• 轮廓系数(Silhouette)
但是常用的指标是轮廓系数。
聚类算法的衡量指标-轮廓系数
• 簇内不相似度:计算样本i到同簇其它样本的平均距离为ai;ai越小,表示样本i越
应该被聚类到该簇,簇C中的所有样本的ai的均值被称为簇C的簇不相似度。
• 簇间不相似度:计算样本i到其它簇Cj的所有样本的平均距离bij,
bi=min{bi1,bi2,…,bik};bi越大,表示样本i越不属于其它簇。
• 轮廓系数:si值越接近1表示样本i聚类越合理,越接近-1,表示样本i应该分类
到另外的簇中,近似为0,表示样本i应该在边界上;所有样本的si的均值被成为
聚类结果的轮廓系数
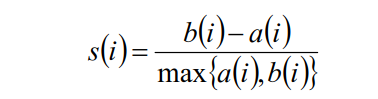
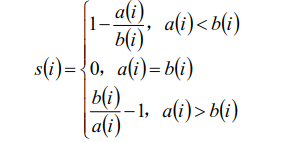
【机器学习三】梯度下降法K-means优化算法
猜你喜欢
转载自blog.csdn.net/weixin_35389463/article/details/84558052
今日推荐
周排行