Hadoop3.1 集群搭建指南
前言
本实验基于Hadoop3.1 和 jdk1.8安装,主要涉及内容是linux网络设置,主机设置,ssh远程登陆设置,
用的操作系统是Centos6.8。
一:LINUX基本配置
步骤:(注:#代表超级用户下使用)
1 创建单个用户用于Hadoop集群搭建
#:useradd username
再键入密码就行了
2 修改sudoers文件,使在Hadoop下可以使用sudo操作
在root下修改:#:/etc/sudoers 添加如下
3 修改主机名
# vi /etc/sysconfig/network

4 linux网络配置
# vi /etc/sysconfig/network-scripts/ifcfg-eth0

5 修改hosts文件
# vi /etc/hosts

注:以上都是一台主机的操作,如果进行集群需要在hosts文件添加节点主机IP和主机名
二:安装JDK
1 解压jdk
# tar -zxvf jdkname
2 配置环境变量
# vi /etc/profile 添加
export JAVA_HOME=/usr/java/jdk1.8.0_161
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
# source /etc/profile
(温馨提示:如果你的centos预装了jdk ,java -version会显示预装的版本,例如我安装的明明是jdk1.8
他显示1.7的

解决:
查看安装的版本
# rpm -qa | grep java

删除预装的版本(我的里预装的是这两个)
# rpm -e --nodeps java-1.7.0-openjdk-1.7.0.99-2.6.5.1.el6.x86_64
# rpm -e --nodeps java-1.6.0-openjdk-1.6.0.38-1.13.10.4.el6.x86_64
再次检查发现只剩一个了

此时再java -version就会报错,说没有该命令

解决:输入
# source /etc/profile 成功解决。)
三 :安装hadoop3.1
集群规划
| 主机名 | 角色 | IP | 账户 | 密码 | CPU | 内存 |
| master | NameNode JobTracker |
192.168.58.131 | root | 111111 | 4vCPU | 12GB |
| slave1 | DataNode TaskTracker |
192.168.58.132 | root | 111111 | 4vCPU | 12GB |
| slave2 | DataNode TaskTracker |
192.168.58.133 | root | 111111 | 4vCPU | 12GB |
1 解压
# tar -zxvf hadoop-3.1.1.tar.gz
假设解压的文件目录在:/usr/hadoop下
2 修改配置文件
# vi /usr/hadoop/etc/hadoop/core-site.xml
| <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:///usr/hadoop/tmp</value> </property> </configuration> |
# vi /usr/hadoop/etc/hadoop/hdfs-site.xml
| <configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///usr/hadoop/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///usr/hadoop/hdfs/data</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>slave1:9001</value> </property> </configuration> |
# vi /usr/hadoop/etc/hadoop/workers
| slave1 slave2 |
# vi /usr/hadoop/etc/hadoop/mapred-site.xml
| <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.application.classpath</name> <value> /usr/hadoop/etc/hadoop, /usr/hadoop/share/hadoop/common/*, /usr/hadoop/share/hadoop/common/lib/*, /usr/hadoop/share/hadoop/hdfs/*, /usr/hadoop/share/hadoop/hdfs/lib/*, /usr/hadoop/share/hadoop/mapreduce/*, /usr/hadoop/share/hadoop/mapreduce/lib/*, /usr/hadoop/share/hadoop/yarn/*, /usr/hadoop/share/hadoop/yarn/lib/* </value> </property> </configuration> |
# vi /usr/hadoop/etc/hadoop/yarn-site.xml
| <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandle</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8025</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master:8040</value> </property> </configuration> |
# vi /usr/hadoop/etc/hadoop/hadoop-env.sh
| export JAVA_HOME=/usr/java/jdk1.8.0_161 # source /opt/hadoop-3.1.0/etc/hadoop/hadoop-env.sh |
# vi /usr/hadoop/etc/hadoop/start-yarn.sh
| export YARN_RESOURCEMANAGER_USER=root export HADOOP_SECURE_DN_USER=root export YARN_NODEMANAGER_USER=root |
# vi /usr/hadoop/etc/hadoop/stop-yarn.sh
| export YARN_RESOURCEMANAGER_USER=root export HADOOP_SECURE_DN_USER=root export YARN_NODEMANAGER_USER=root |
# vi /usr/hadoop/etc/hadoop/start-dfs.sh
| export HDFS_NAMENODE_SECURE_USER=root export HDFS_DATANODE_SECURE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root |
# vi /usr/hadoop/etc/hadoop/stop-dfs.sh
| export HDFS_NAMENODE_SECURE_USER=root export HDFS_DATANODE_SECURE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root |
3 克隆slave1和slave2
(注:centos6.8克隆后自动分配ip地址,ifconfig查看ip地址,修改ifcfg-eth0文件)
①:修改,点击克隆slave1的网络适配器如下

②:修改内容如下
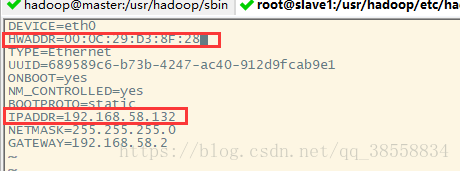
slave2同上。
每个结点都执行
| # vi /etc/profile export HADOOP_HOME=/usr/hadoop export PATH=$PATH:$HADOOP_HOME/bin # source /etc/profile # source /usr/hadoop/etc/hadoop/hadoop-env.sh |
在master结点修改hadoop-env.sh
| # vi /usr/hadoop/etc/hadoop/hadoop-env.sh export HDFS_NAMENODE_SECURE_USER=root export HDFS_DATANODE_SECURE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root # source /usr/hadoop/etc/hadoop/hadoop-env.sh |
4 配置ssh免密登录
在每个主机上都执行:ssh-keygen,提示直接键入y和enter
在master结点上执行:
ssh-copy-id 192.168.58.132
ssh-copy-id 192.168.58.132
格式化集群
hdfs namenode -format
格式化成功

启动集群
start-all.sh
如果namenode没有启动则输入:./hadoop-daemon.sh namenode start
jps
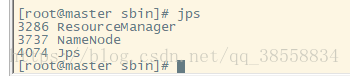
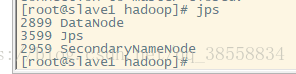
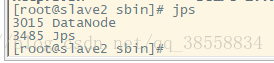
通过网页访问:
192.168.58.131:8088/
192.168.58.131:9870/
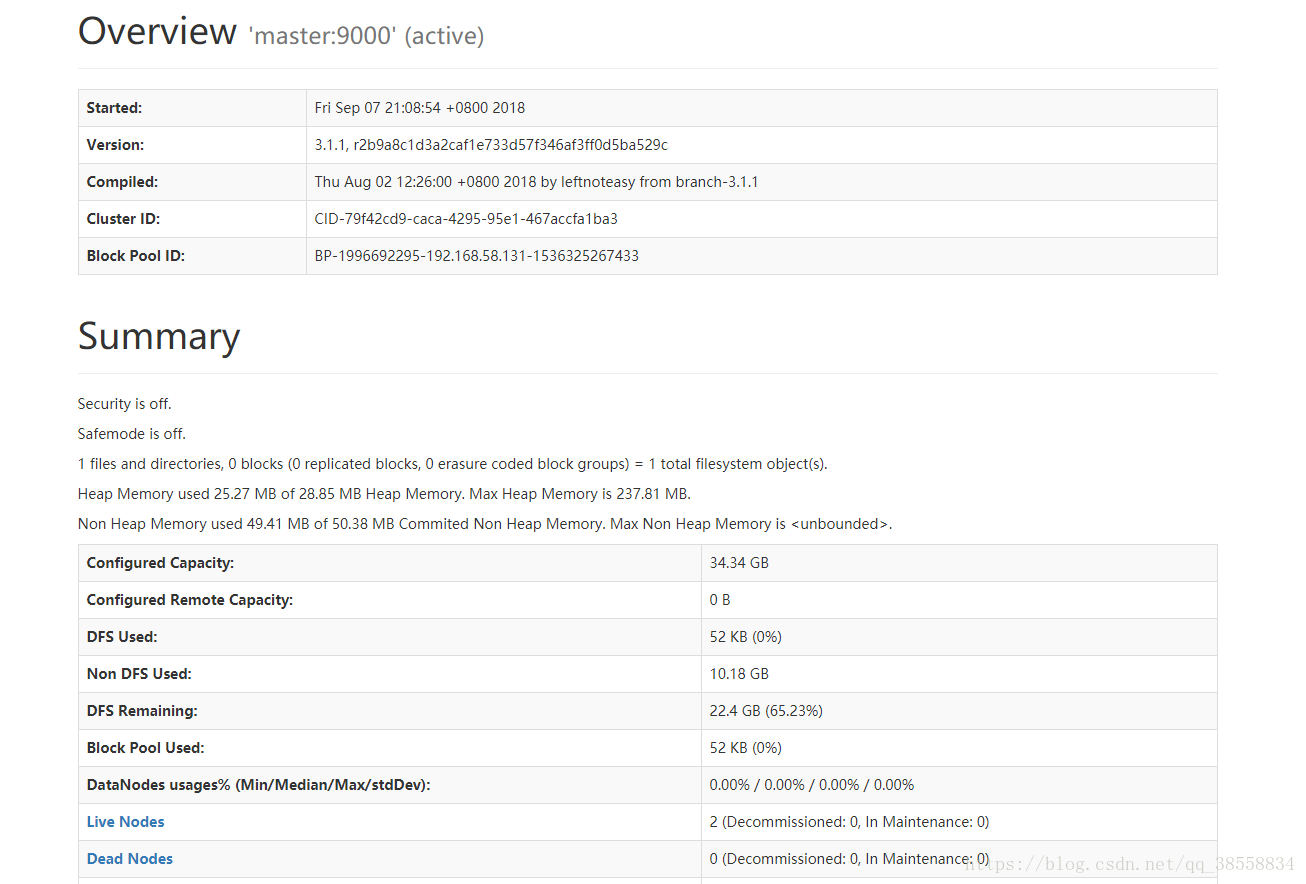
(注意:有的浏览器进不去192.168.58.131:9870,例如QQ浏览器就不行,也许我没更新的原因,改用Chrome就好了。)