日常开发中我们经常会遇到大表的情况,所谓的大表是指存储了百万级乃至千万级条记录的表。这样的表过于庞大,导致数据库在查询和插入的时候耗时太长,性能低下,如果涉及联合查询的情况,性能会更加糟糕。分表的目的就是减少数据库的负担,提高数据库的效率,通常点来讲就是提高表的增删改查效率,本文将介绍我的一次利用存储过程给一张2600万数据的地址库大表(数据网上下载也可以自己造)进行水平分表处理。对于MySQL存储过程大家都了解,我就不介绍概念了,本文主要介绍分表的过程。我的上一篇文章也简单介绍了存储过程的一些语法、创建语句等,参考文章:https://blog.csdn.net/caiqing116/article/details/84843908 开门见山,进入正文。
1.创建IP地址库总数据表
CREATE TABLE `tb_data_ipaddrlib_free` (
`id` INT (11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 'id',
`minip` INT (11) UNSIGNED DEFAULT NULL COMMENT 'IP 块最小端 IP,整数形式',
`maxip` INT (11) UNSIGNED DEFAULT NULL COMMENT 'IP 块最大端 IP,整数形式',
`continent` VARCHAR (16) DEFAULT NULL COMMENT '大洲',
`areacode` VARCHAR (4) DEFAULT NULL COMMENT 'IP 块所在国家的国家编码',
`country` VARCHAR (50) DEFAULT NULL COMMENT 'IP 块所在国家',
`multiarea` text COMMENT 'IP 块定位信息,是单或多区域',
`user` VARCHAR (200) DEFAULT NULL COMMENT 'IP 使用者名称',
PRIMARY KEY (`id`)
KEY `index_minip_maxip` (`minip`, `maxip`)
) AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8;
2.创建IP地址区间和分表后缀关系表
在后面我将IP地址库总表每100万条IP地址记录作为一条关联记录存储,id值在这里从1001开始累加(后缀都4位,这个可以自己定义2位3位都行),作为分表的区分后缀,minip为这100万条数据的开始ip,maxip为这100万条数据的结束ip。以上这些定义是可以灵活变动的,根据个人需要定义,后续根据存储过程插入记录结果形如:
1000,minip1,maxip2
1001,minip3,maxip4
1002,minip5,maxip6
建表语句如下
DROP TABLE IF EXISTS tb_data_ipaddrlib_tables;
CREATE TABLE `tb_data_ipaddrlib_tables` (
`id` INT (11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 'id',
`minip` INT (11) UNSIGNED DEFAULT NULL COMMENT 'IP 块最小端 IP,整数形式',
`maxip` INT (11) UNSIGNED DEFAULT NULL COMMENT 'IP 块最大端 IP,整数形式',
PRIMARY KEY (`id`)
) DEFAULT CHARSET = utf8;
3.导入IP地址库总数据作为分表依据
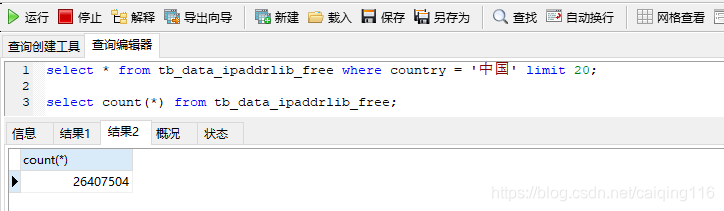
Navicat for MySQL提供了导入数据的功能,我们也可以根据tb_data_ipaddrlib_free表结构自己手动造数据,这里就不详细介绍怎么导数据了。如果需要可以找我(评论区)。导入结果如下,可以看到我这里导入了26407540条数据
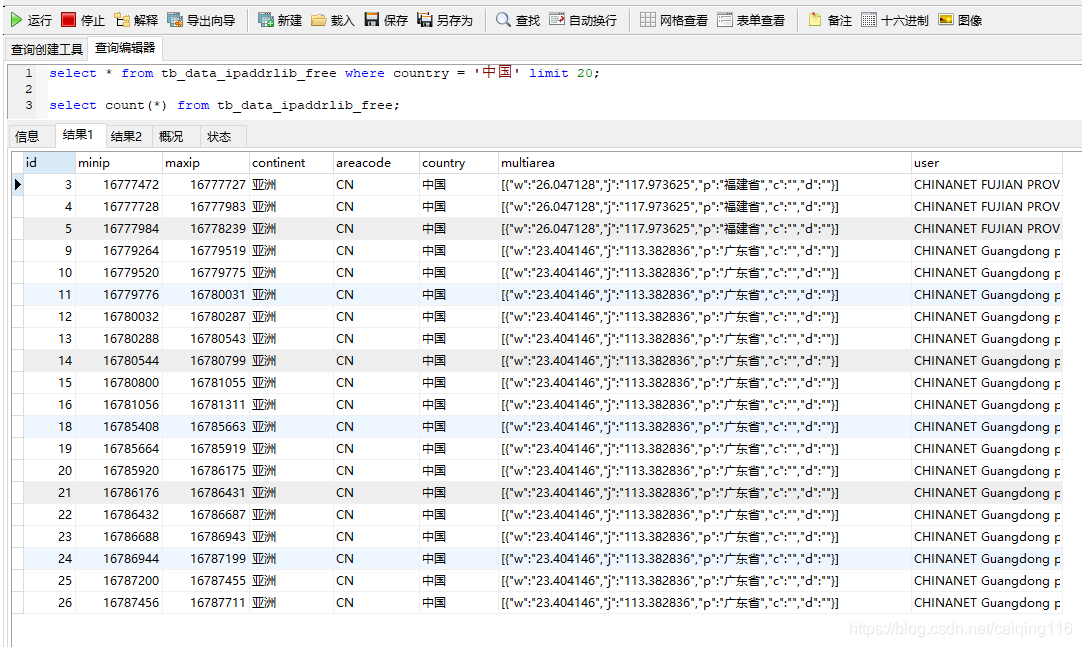
数据格式如下
4.定义存储过程为IP地址区间和动分表后缀关系表插入数据
每张表100万数据,冗余的插入在最后一张表,分表后缀从1001开始累加
DELIMITER //
create PROCEDURE proc_ip_split_tables()
begin
#定义变量 i 循环起始值,init分表后缀起始值,datanum每张表最大数据量, count分表个数
declare i int default 0;
declare init int default 1001;
declare datanum int default 1000000;
declare count int ;
#计算出分表个数并赋值给count
select FLOOR(count(id) / datanum) into count from tb_data_ipaddrlib_free;
truncate tb_data_ipaddrlib_tables;
while i<= count do
IF i = count THEN
insert into tb_data_ipaddrlib_tables set
id = init + i,
#查询开始ip赋值
minip = (select minip from tb_data_ipaddrlib_free where id = (1+datanum*i) ),
#查询结束ip赋值,最后一条记录
maxip = (select maxip from tb_data_ipaddrlib_free ORDER BY id desc limit 1 );
ELSE
insert into tb_data_ipaddrlib_tables set
id = init + i,
#查询开始ip赋值
minip = (select minip from tb_data_ipaddrlib_free where id = (1+datanum*i) ),
#查询结束ip赋值
maxip = (select maxip from tb_data_ipaddrlib_free where id = (datanum+datanum*i) );
END IF;
set i = i+1;
end while;
end//
DELIMITER ;
执行此存储过程 call proc_ip_split_tables();
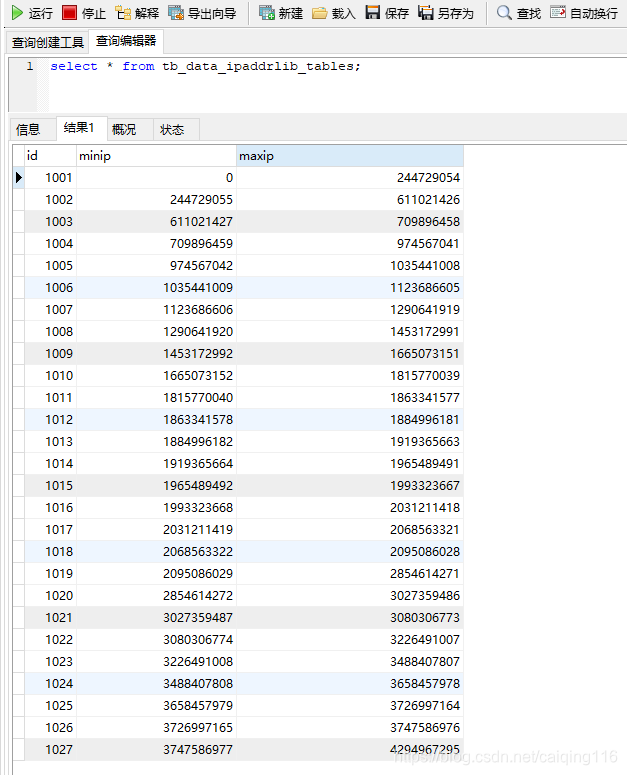
根据2600万+的数据量,每张表100万,我们可以断定会生成27张分表。结果如下:
5.定义存储过程创建所有的分表
DELIMITER //
create PROCEDURE proc_ip_tables_create()
begin
#定义变量 i 循环起始值,init分表后缀起始值,datanum每张表最大数据量, count分表个数
declare i int default 0;
declare init int default 1001;
declare datanum int default 1000000;
declare count int;
#计算出分表个数并赋值给count
select FLOOR(count(id) / datanum) into count from tb_data_ipaddrlib_free;
#开始创建表
while i<= count do
set @sql_create_table = concat(
'CREATE TABLE IF NOT EXISTS tb_data_ipaddrlib_free_', init+i,
"(
`id` INT (11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 'id',
`minip` INT (11) UNSIGNED DEFAULT NULL COMMENT 'IP 块最小端 IP,整数形式',
`maxip` INT (11) UNSIGNED DEFAULT NULL COMMENT 'IP 块最大端 IP,整数形式',
`continent` VARCHAR (16) DEFAULT NULL COMMENT '大洲',
`areacode` VARCHAR (4) DEFAULT NULL COMMENT 'IP 块所在国家的国家编码',
`country` VARCHAR (50) DEFAULT NULL COMMENT 'IP 块所在国家',
`multiarea` text COMMENT 'IP 块定位信息,是单或多区域',
`user` VARCHAR (200) DEFAULT NULL COMMENT 'IP 使用者名称',
PRIMARY KEY (`id`),
KEY `index_minip_maxip` (`minip`, `maxip`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8" );
PREPARE sql_create_table FROM @sql_create_table;
EXECUTE sql_create_table;
set i = i+1;
end while;
end//
DELIMITER ;
执行此存储过程 call proc_ip_tables_create();
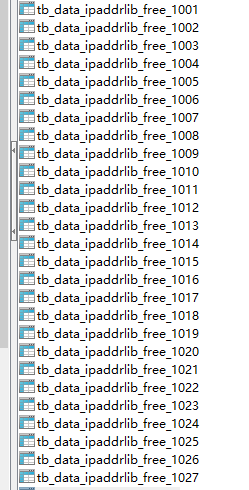
根据2600万+的数据量,每张表100万,我们可以断定会生成27张分表。结果如下:
6.定义存储过程为所有的分表插入数据
DELIMITER //
create PROCEDURE proc_ip_inserttotables()
BEGIN
#定义变量 i 循环起始值,init分表后缀起始值,datanum每张表最大数据量, count分表个数
declare i int default 0;
declare datanum int default 1000000;
declare init int default 1001;
declare count int ;
#计算出分表个数并赋值给count
select FLOOR(count(id) / datanum) into count from tb_data_ipaddrlib_free;
#开始插入数据
WHILE i<= count DO
set @sql_insert_ip = CONCAT(
'insert into tb_data_ipaddrlib_free_',
init+i,
' select * from tb_data_ipaddrlib_free where minip BETWEEN (select minip from tb_data_ipaddrlib_tables where id =',
init+i,
' ) AND (select minip from tb_data_ipaddrlib_free where maxip in (select maxip from tb_data_ipaddrlib_tables where id =',
init+i,
' )limit 1 )');
set @sql_truncate_ip = CONCAT("truncate tb_data_ipaddrlib_free_", 1001+1);
PREPARE sql_truncate_ip FROM @sql_truncate_ip;
PREPARE sql_insert_ip FROM @sql_insert_ip;
EXECUTE sql_truncate_ip;
EXECUTE sql_insert_ip;
set i = i+1;
end WHILE;
end//
DELIMITER;
执行此存储过程 call proc_ip_inserttotables();
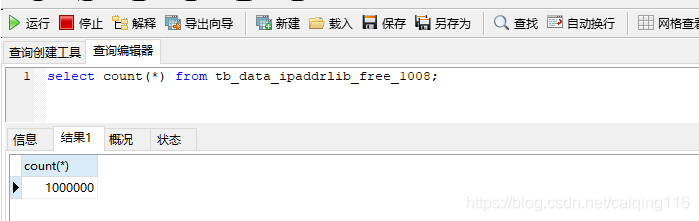
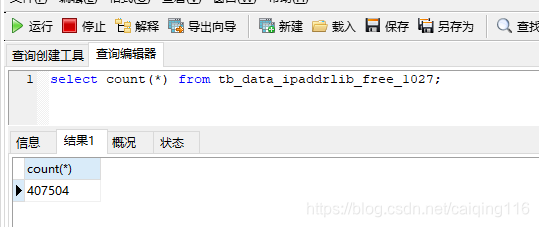
验证步骤1,我们可以查询任意分表然后查看是否是100万条数据,查看最后一张表1027是否是407504条数据
查询分表1008验证
查询分表1027验证
查询某个ip(221.224.63.146)地址进行验证
查询此ip地址落在哪个分表
select * from tb_data_ipaddrlib_tables where INET_ATON('221.224.63.146') BETWEEN minip and maxip;

根据结果我们知道该ip落在了分表1025,我们根据此ip在tb_data_ipaddrlib_free_1025表查询,看是否存在该ip记录
select * from tb_data_ipaddrlib_free_1025 where INET_ATON('221.224.63.146') BETWEEN minip and maxip;
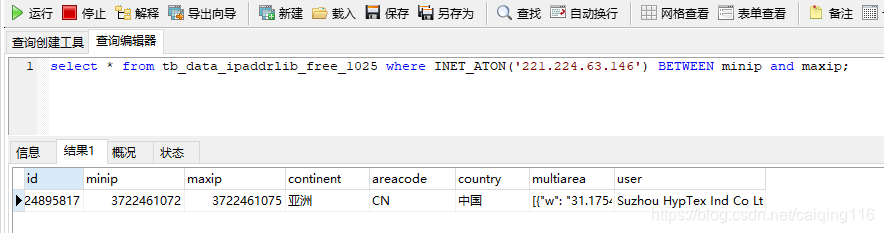
综上根据存储过程创建分表成功。