1.reduceByKeyAndWindow这个算子也是lazy的,它用来计算一个区间里面的数据,如下图:
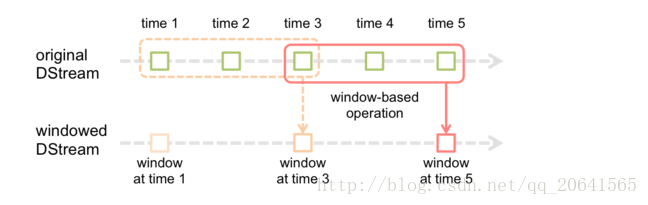
截图自官网,例如每个方块代表5秒钟,上面的虚线框住的是3个窗口就是15秒钟,这里的15秒钟就是窗口的长度,其中虚线到实线移动了2个方块表示10秒钟,这里的10秒钟就表示每隔10秒计算一次窗口长度的数据
举个例子: 如下图
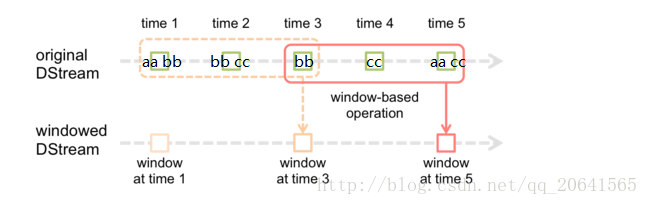
我是这样理解的:如果这里是使用窗口函数计算wordcount 在第一个窗口(虚线窗口)计算出来(aa, 1)(bb,3)(cc,1)当到达时间10秒后窗口移动到实线窗口,就会计算这个实线窗口中的单词,这里就为(bb,1)(cc,2)(aa,1)
附上程序:
注意:窗口滑动长度和窗口长度一定要是SparkStreaming微批处理时间的整数倍,不然会报错.
import org.apache.log4j.Level
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
object SparkWindowDemo {
val myfunc = (it: Iterator[(String, Seq[Int], Option[Int])]) => {
it.map(x => {
(x._1, x._2.sum + x._3.getOrElse(0))
})
}
def main(args: Array[String]): Unit = {
MyLog.setLogLeavel(Level.WARN)
val conf = new SparkConf().setMaster("local[2]").setAppName("window")
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc, Seconds(2))
sc.setCheckpointDir("C:\\Users\\Administrator\\Desktop\\myck01")
val ds = ssc.socketTextStream("192.168.80.123", 9999)
//Seconds(20)表示窗口的宽度 Seconds(10)表示多久滑动一次(滑动的时间长度)
val re = ds.flatMap(_.split(" ")).map((_, 1)).reduceByKeyAndWindow((a: Int, b: Int) => a + b, Seconds(20), Seconds(10))
// 窗口长度和滑动的长度一致,那么类似于每次计算自己批量的数据,用updateStateByKey也可以累计计算单词的wordcount 这里只是做个是实验
// val re = ds.flatMap(_.split(" ")).map((_, 1)).reduceByKeyAndWindow((a: Int, b: Int) => a + b, Seconds(4), Seconds(4)).updateStateByKey(myfunc, new HashPartitioner(sc.defaultParallelism), true)
re.print()
ssc.start()
ssc.awaitTermination()
}
}2.
reduceByKeyAndWindow基于滑动窗口的热点搜索词实时统计
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
*
* 基于滑动窗口的热点搜索词实时统计
* 每隔5秒钟,统计最近20秒钟的搜索词的搜索频次,
* 并打印出排名最靠前的3个搜索词以及出现次数
*
*/
object WindowDemo {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setAppName("WindowDemo")
.setMaster("local[2]")
val ssc=new StreamingContext(conf,Seconds(5))
//从nc服务中获取数据,数据格式:name word,比如:张三 大数据
val linesDStream=ssc.socketTextStream("tgmaster",9999)
//将数据中的搜索词取出
val wordsDStream=linesDStream.map(_.split(" ")(1))
//通过map算子,将搜索词形成键值对(word,1),将搜索词记录为1次
val searchwordDStream=wordsDStream.map(searchword=>(searchword,1))
//通过reduceByKeyAndWindow算子,每隔5秒统计最近20秒的搜索词出现的次数
val reduceDStream=searchwordDStream.reduceByKeyAndWindow(
(v1:Int,v2:Int)=>
v1+v2,Seconds(20),Seconds(5)
)
//调用DStream中的transform算子,可以进行数据转换
val transformDStream=reduceDStream.transform(searchwordRDD=>{
val result=searchwordRDD.map(m=>{ //将key与value互换位置
(m._2,m._1)
}).sortByKey(false) //根据key进行降序排列
.map(m=>{ //将key与value互换位置
(m._2,m._1)
}).take(3) //取前3名
for(elem<-result){
println(elem._1+" "+elem._2)
}
searchwordRDD //注意返回值
})
transformDStream.print()
ssc.start()
ssc.awaitTermination()
}
}
4.
最近在玩spark streaming, 感觉到了他的强大。 然后看 StreamingContext的源码去理解spark是怎么完成计算的。 大部分的源码比较容易看懂, 但是这个
reduceByKeyAndWindow(_+_, _-_, Duration, Duration)
还是花了不少时间。 主要还是由于对spark不熟悉造成的吧, 还好基本弄明白了。
总的来说SparkStreaming提供这个方法主要是出于效率考虑。 比如说我要每10秒计算一下前15秒的内容,(每个batch 5秒), 可以想象每十秒计算出来的结果和前一次计算的结果其实中间有5秒的时间值是重复的。
那么就是通过如下步骤
1. 存储上一个window的reduce值
2.计算出上一个window的begin 时间到 重复段的开始时间的reduce 值 =》 oldRDD
3.重复时间段的值结束时间到当前window的结束时间的值 =》 newRDD
4.重复时间段的值等于上一个window的值减去oldRDD
这样就不需要去计算每个batch的值, 只需加加减减就能得到新的reduce出来的值。
从代码上面来看, 入口为:
reduceByKeyAndWindow(_+_, _-_, Duration, Duration)
一步一步跟踪进去, 可以看到实际的业务类是在ReducedWindowedDStream 这个类里面:
代码理解就直接拿这个类来看了: 主要功能是在compute里面实现, 通过下面代码回调mergeValues 来计算最后的返回值
- val mergedValuesRDD = cogroupedRDD.asInstanceOf[RDD[(K, Array[Iterable[V]])]]
- .mapValues(mergeValues)
先计算oldRDD 和newRDD
//currentWindow 就是以当前时间回退一个window的时间再向前一个batch 到当前时间的窗口 代码里面有一个图很有用:
我们要计算的new rdd就是15秒-25秒期间的值, oldRDD就是0秒到10秒的值, previous window的值是1秒 - 15秒的值
然后最终结果是 重复区间(previous window的值 - oldRDD的值) =》 也就是中间重复部分, 再加上newRDD的值, 这样的话得到的结果就是10秒到25秒这个时间区间的值
- // 0秒 10秒 15秒 25秒
- // _____________________________
- // | previous window _________|___________________
- // |___________________| current window | --------------> Time
- // |_____________________________|
- //
- // |________ _________| |________ _________|
- // | |
- // V V
- // old RDDs new RDDs
- //
- val currentTime = validTime
- val currentWindow = new Interval(currentTime - windowDuration + parent.slideDuration,
- currentTime)
- val previousWindow = currentWindow - slideDuration
- val oldRDDs =
- reducedStream.slice(previousWindow.beginTime, currentWindow.beginTime - parent.slideDuration)
- logDebug("# old RDDs = " + oldRDDs.size)
- // Get the RDDs of the reduced values in "new time steps"
- val newRDDs =
- reducedStream.slice(previousWindow.endTime + parent.slideDuration, currentWindow.endTime)
- logDebug("# new RDDs = " + newRDDs.size)
得到newRDD和oldRDD后就要拿到previous windows的值: 如果第一次没有previous window那么建一个空RDD, 为最后计算结果时 arrayOfValues(0).isEmpty 铺垫
- val previousWindowRDD =
- getOrCompute(previousWindow.endTime).getOrElse(ssc.sc.makeRDD(Seq[(K, V)]()))
然后把所有的值放到一个数组里面 0是previouswindow, 1到oldRDD.size是oldrdd, oldRDD.size到newRDD.size是newrdd
- val allRDDs = new ArrayBuffer[RDD[(K, V)]]() += previousWindowRDD ++= oldRDDs ++= newRDDs
将每个RDD的(K,V) 转变成(K, Iterator(V))的形式:
比如说有两个值(K,a) 和(K,b) 那么coGroup后就会成为(K, Iterator(a,b))这种形式
- val cogroupedRDD = new CoGroupedRDD[K](allRDDs.toSeq.asInstanceOf[Seq[RDD[(K, _)]]],
- partitioner)
进行最后的计算:
- val mergeValues = (arrayOfValues: Array[Iterable[V]]) => {
- ...
- }
首先判断RDD的value数量是不是正确 previous window因为已经计算过所以只有一组值
正确值为 1 (previous window value) + numOldValues (oldRDD 每个RDD的value) + numNewValues (newRDD 每个RDD的value)
- if (arrayOfValues.size != 1 + numOldValues + numNewValues) {
- throw new Exception("Unexpected number of sequences of reduced values")
- }
接下来取出oldRDD的值和newRDD的值:
- val oldValues = (1 to numOldValues).map(i => arrayOfValues(i)).filter(!_.isEmpty).map(_.head)
- val newValues =
- (1 to numNewValues).map(i => arrayOfValues(numOldValues + i)).filter(!_.isEmpty).map(_.head)
如果previous window是空的, 那么就直接计算newRDD的值(这也是为什么每次计算时候第一次打出来的值都比较少, 因为他只有newRDD部分没有重合部分, 也就是只有10秒的内容而不是15秒)
- if (arrayOfValues(0).isEmpty) {
- // If previous window's reduce value does not exist, then at least new values should exist
- if (newValues.isEmpty) {
- throw new Exception("Neither previous window has value for key, nor new values found. " +
- "Are you sure your key class hashes consistently?")
- }
- // Reduce the new values
- newValues.reduce(reduceF) // return
- }
如果有previous window的值, 那么先存到tempValue, 如果有oldRDD那么减去oldRDD, 如果有newRDD (一般都有) 那么加上newRDD的值 这样就组成上图里面10到25秒区间的值了
- else {
- // Get the previous window's reduced value
- var tempValue = arrayOfValues(0).head
- // If old values exists, then inverse reduce then from previous value
- if (!oldValues.isEmpty) {
- tempValue = invReduceF(tempValue, oldValues.reduce(reduceF))
- }
- // If new values exists, then reduce them with previous value
- if (!newValues.isEmpty) {
- tempValue = reduceF(tempValue, newValues.reduce(reduceF))
- }
- tempValue // return
- }
最后如果有filter的function的话就filter一下:
- if (filterFunc.isDefined) {
- Some(mergedValuesRDD.filter(filterFunc.get))
- } else {
- Some(mergedValuesRDD)
- }
参考:
http://humingminghz.iteye.com/blog/2308231
http://www.cnblogs.com/zDanica/p/5471592.html
https://yq.aliyun.com/articles/60315
http://www.medsci.cn/article/show_article.do?id=87c455942b8