版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/ZZZJX7/article/details/78252735
参考了之前的路径fuzz的工具,例如猪猪侠的工具:https://github.com/ring04h/weakfilescan,这个工具主要就是先爬取网页的路径,然后再对每个路径进行fuzz,这种思路跟以前的路径fuzz的差别就在于可获取更多存在的链接进行fuzz;而不单单只是进行对根目录或者某个路径进行字典加载。
但上面的工具有一些缺点就是可能会导致一些网址会重复爬取,爬取的链接也不是很全,默认好像是设置3层。
参考了以上的有缺点,也造了一个轮子。我的做法就是先对网站的url链接进行爬取,获取的链接可以有很多用处,之前主要是用于倒进扫描器进行一些sql注入,url跳转和命令注入等的扫描。
扫描器的原理基本就是:先对爬取的url进行去重,然后把url链接倒进一个修改过的轮子(https://github.com/Mosuan/FileScan),这个fuzz路径的扫描器可以对每个扫描的路径都能扫描,并且是进行多个状态进行比对。例如 www.abc.com/a/b,扫描的路径就会有www.abc.com,www.abc.com/a,www.baidu.com/a/b。但爬取的url路径可能会有重复的情况,例如www.abc.com/a/b/c,这时候也进行一个路径的去重,把之前扫描过一次的路径进行标记,下次扫描的时进行状态的比对,结果主要存在mongodb中。
效果图:
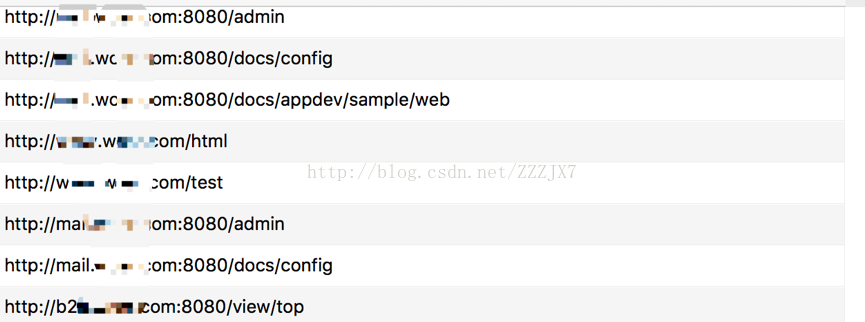
目前存在的情况是由于一些路径没有进行规则的匹配,还是存在一点误报的情况。好东西不是一蹴而就,需要不停地进行优化,这里分享了一下自己在路径fuzz上面的看法。
更新:
进行了优化,一是当命中规则时会再一次进行返回包长度的检验;二是当命中规则数超过一个伐值,会舍弃这些数据。
这样误报率一下子下降,准确率提高了很多。