Andrew Ng’s Coursera Machine Leaning(ML) Notes Week2
Author: Yu-Shih Chen
December 22, 2018 6:55 PM
Intro:
本人目前是在加州上大学的大二生,对人工智能和数据科学有浓厚的兴趣所以在上学校的课的同时也喜欢上一些网课。主要目的是希望能够通过在这个平台上分享自己的笔记来达到自己更好的学习/复习效果所以notes可能会有点乱,有些我认为我自己不需要再复习的内容我也不会重复。当然,如果你也在上这门网课,然后刚好看到了我的notes,又刚好觉得我的notes可能对你有点用,那我也会很开心哈哈!有任何问题或建议OR单纯的想交流OR单纯想做朋友的话可以加我的微信:y802088
Week3
大纲:
- Classification
- Hypothesis Representation
- Decision Boundary
- Cost Function
- Simplified Cost Function and Gradient Descent
- Advanced Optimization
- Multiclass Classification: One-vs-all
- The Problem of Overfitting
- Cost Function
- Regularized Linear Regression
- Regularized Logistic Regression
Classification
Classification跟之前学的不一样的地方就在我们要predict的东西不是一个数值(如:yes or no), 但我们只要把它转换为数值(0和1)就可以了。我们先学习binary classification problem,也就是只会有0和1的output。
Section 重点:这个section主要就是introduce classification的大概思路。
Hypothesis Representation
在学习如何表达我们的预测公式之前,有一个核心的公式需要知道,那就是:Sigmoid Function(also known as Logistic function)。
Sigmoid Function表达式:
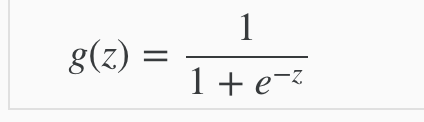
为什么需要知道这个呢?之前也说了,做classification类的问题的时候我们需要将我们的result的值放到0和1,而这个公式的图标画出来的话:

这个sigmoid function的output绝对不会超过1,也就是可以将我们之前学过的Linear Regression里面的公式套入里面:
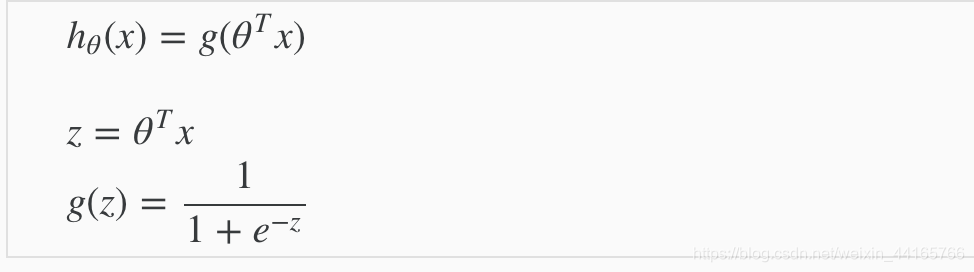
这样我们得出的结果,就会是得到“1”的概率。 (比如说如果我们套入这个预测公式后得到0.7,那就代表我们得到的预测就是“1”的几率有70%,“0”的几率有30%。)而我们要做的,就是给公式设定一个threshold(如:if h_x > 0.5 = 1)来决定它predict 1还是0.
Section 重点:将linear regression的预测公式plug到sigmoid function里面就可以得到“1”的概率。
Decision Boundary
我们需要决定一个threshold来预测我们最终的值。上一个section讲了我们的预测公式可以预测出得到“1”的概率,这个section讲的如何用threshold来更好地理解我们的logistic regression model是怎么predict value的
我们再来看一次sigmoid的function:

如图所示,x轴表示的就是我们的’z’ 也就是linear regression用的h_x(预测公式Theta’ * X) 那z>0 的时候就会超过50%也就会predict 1,我们就可以通过 这个信息有个更好的了解logistic regression是怎么运作的。 而且decision boundary出来了之后,是跟我们的training set没有关联的。所以theta学习完毕后,decision boundary不会根据data set而改变(就相当于我们week 2画出来的线)。
以下是一个example:

如果theta训练出这3个值,那我们就知道如果我们的x1 小于或等于5的话,就会预测出1。
section 重点:通过sigmoid function和我们定的threshold来更好地了解我们的logistic regression的运作。得出的decision boundary是我们train完了之后的h_x的一个property,跟training set是没有关系的。
Cost Function
week 2的时候忘记讲,但是linear regression model是永远都只有一个global minima的,所以我们不用担心gradient descent会跑到local minimum去。但是如果我们套用一样的公式给logistic regression,那将会制造很多的local minimum也就有可能不会达到最低点。
所以我们有另外一套公式:

用图表表示出来的话:
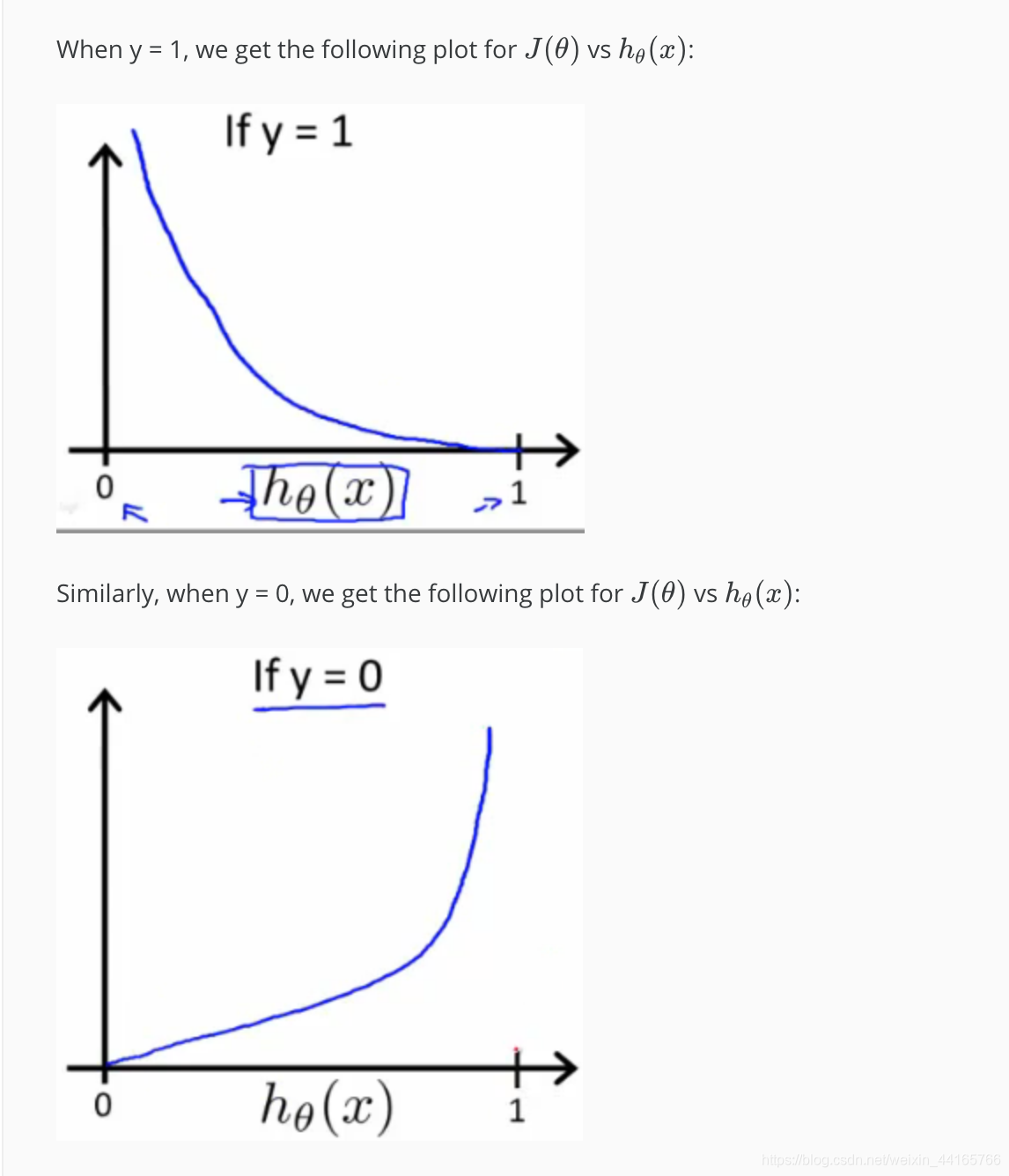
通过这样的公式就会让它只有一个global minima。后面会有将他们combine成一个公式的写法,这个section主要目的是为了解释我们新的cost function的思路。
section重点:如果直接套用linear regression 的cost function, 那将不止一个local minima。所以我们需要一套新的公式来表达我们的cost function for logistic regression.
Simplified Cost Function and Gradient Descent
上个section讲到的cost function这个section会把它简化到一个公式里,就不用分开implement了更方便!
公式为:

为什么能这样写呢?因为大佬们很聪明。如果y = 1的话,那后半部分的equation就为0,只剩下前半段。而前半段是不是刚好就是y = 0的时候的cost function? (详细参考上个section)。相反y=0的时候也一样,前半段会为0只剩下后半段。这样我们就不需要特地分开2部分来写我们的代码了。
这个section还讲了gradient descent的公式。
公式为:
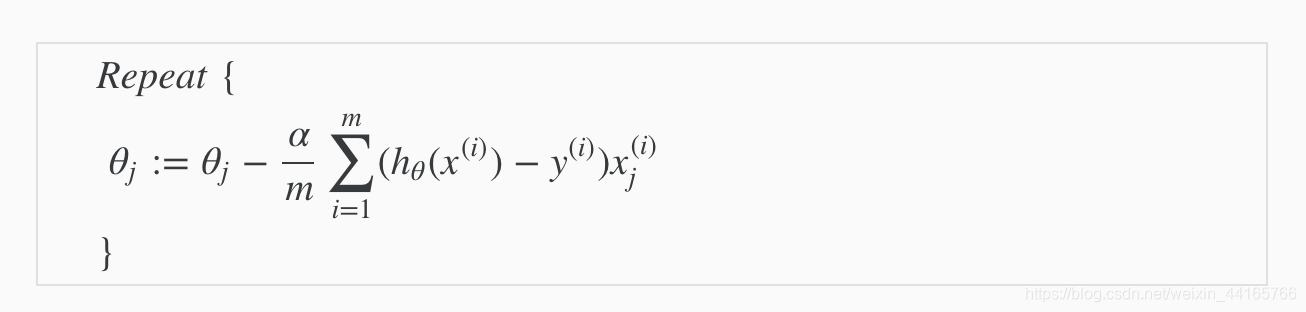
是不是跟linear regression的gradient descent一模一样?不一样!要注意这里的h(x)是代入sigmoid function之后得出的预测。
section重点:cost function可以写成一条公式了。gradient descent乍一看跟linear regression的一模一样,但是要小心这里的h_x是带入sigmoid 后的预测,跟linear regression的时候是不一样的!
Advanced Optimization Algorithms
这个section非常重要也有用。 它主要讲了除了gradient descent以外的一些找theta的算法:
- Gradient Descent
- Conjugate Gradient
- BFGS
- L-BFGS
这些算法跟gradient descent比的好处是:
- 不用自己选择alpha(learning rate) 算法会自动帮你选择最好的alpha
- 更快,更有效率
- 更复杂,比较难debug
Implement的准备条件:
- 计算J(theta),也就是我们的cost function
- 计算根据每一个theta的gradient(也就是partial derivative)做成一个跟theta一样大的矩阵。
- 可以写一个function计算这两样东西:
function [jVal, gradient] = costFunction(theta)
jVal = […code to compute J(theta)…];
gradient = […code to compute derivative of J(theta)…];
end
这里写的代码也就是做一个可以return jVal(我们的cost)和gradient(partial derivative)的function。作业里要求写的就是这个function。
Implementation:
options = optimset(‘GradObj’, ‘on’, ‘MaxIter’, 100);
initialTheta = zeros(2,1);
[optTheta, functionVal, exitFlag] = fminunc(@costFunction, initialTheta, options);
利用我们上面写的function,这个算法在MATLAB和OCTAVE上的写法如上。
注释:
- ‘GradObj’ 和‘on’就是说我们会提供gradient。
- ‘MatIter’ 和 ‘100’ 就是我们设定的循环多少次(算法自带loop)
- initialTheta就是我们设定theta的初始值,这里全部为0
- optTheta, functionVal, exitFlag分别为算法得出的结论,这里的optTheta就是我们想要的theta值,而exitFlag会return 一个integer来表示它认为converge了没。具体用’help fminunc’代码来了解。
至于这些算法具体是怎么运作的is well beyond the scope of this class。 但是Andrew说就是他也是在用了好一段时间了之后才真的了解他们的运行构造的。所以就算不知道他们具体是怎么运行的也完全可以拿来使用。要注意一点就是必须n>=2, 也就是必须得有2个或以上的theta值这个算法才能跑。
Section 重点:除了gradient descent外还有其他的advanced optimization algorithms。他们比gd要更有效率而且更省事情。后面的作业基本上都是用advanced opt algorithms来找theta,很少再implement gradient descent了。记得n>=2,也就是theta的数量要至少有2个。
Multiclass Classification One-vs-All
这个section讲了如何将我们上面讨论的binary class运用到multiclass里面,也就是说我们的y不只有0和1,而是可以有01234567…n。
看图 :
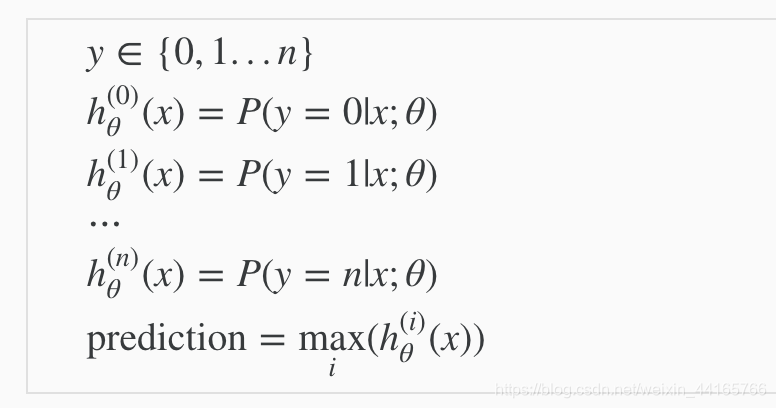
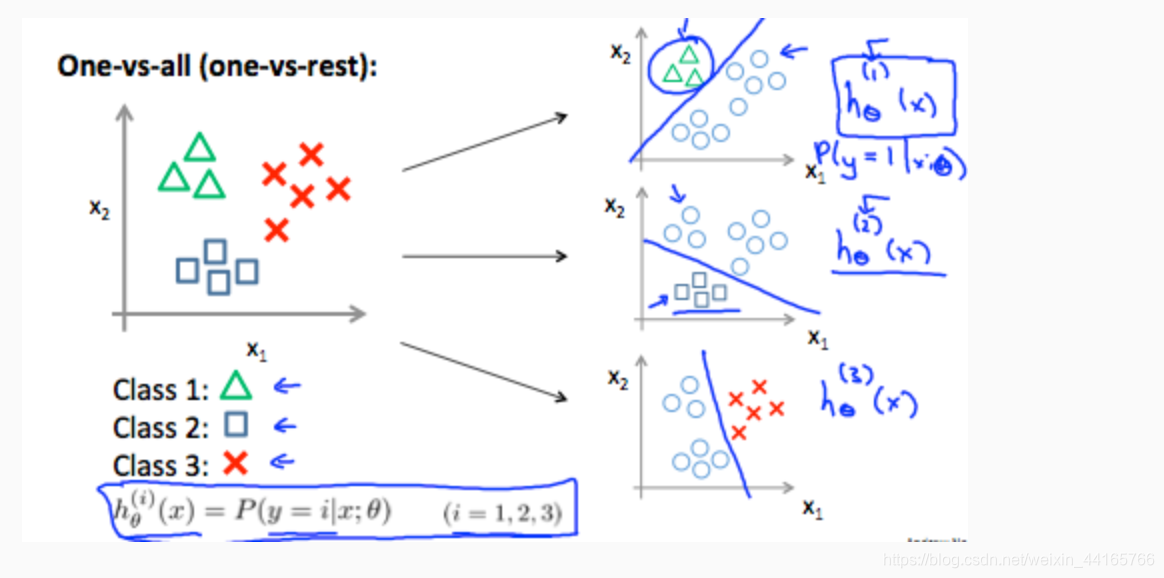
如图所示,现在的h_x预测出来的值就会代表得到i(也就是y)的几率。他会分成很多个binary class来预测。 这里有3个class,所以分成3次,每次都跟你剩下的class一起对比。我们会得到3个值,分别为3个class的几率,而写个max的代码找出哪一个几率最高就行了。简单地说就是分成i个binary class生成i个结果,从中挑选最好的。
Section 重点:从binary class(2个output 0和1)到multiclass的应用。
Week 3就到这里啦!(作业写在另一个文章里)
Thanks for reading!