简单介绍:
Azkaban是由Linkedin公司推出的一个批量工作流任务调度器,用于在一个工作流内以一个特定的顺序运行一组工作和流程。Azkaban使用job配置文件建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪你的工作流。 它有三个重要组件:
- 关系数据库(目前仅支持mysql)
- web管理服务器-AzkabanWebServer
- 执行服务器-AzkabanExecutorServer

Azkaban使用MySQL来存储它的状态信息,Azkaban Executor Server和Azkaban Web Server均使用到了MySQL数据库。
AzkabanExecutorServer在如下几个方面使用到了数据库:
- 获取project的信息
- 执行工作流
- 存储工作流运行日志
- 如果一个工作流在不同的执行器上运行,它将从DB中获取状态。
AzkabanWebServer在如下几个方面使用到了数据库:
- Project管理
- 跟踪工作流执行进度
- 访问历史工作流的运行信息
- 定时执行工作流任务
- 记录所有sla规则
AzkabanWebServer
AzkabanWebserver是整个Azkaban工作流系统的主要管理者,它负责project管理、用户登录认证、定时执行工作流、跟踪工作流执 行进度等一系列任务。同时,它还提供Web服务操作的接口,利用该接口,用户可以使用curl或其他ajax的方式,来执行azkaban的相关操作。操作包括:用户登录、创建project、上传workflow、执行workflow、查询workflow的执行进度、杀掉workflow等一系列操作,且这些操作的返回结果均是json的格式。
AzkabanExecutorServer
之所以将AzkabanWebServer和AzkabanExecutorServer分开,主要是因为在某个任务流失败后,可以更方便的将重新执行。而且也更有利于Azkaban系统的升级。
注意:安装sqoop的节点都要安装azkaban
环境配置:由于azkaban3.0以上没有相应的安装包,需要从源码进行编译。编译的环境需要安装jdk8。
分布式模式:集群内应当安装三个exec-server和一个web-server,相关组件分配如下:
bigdata243 azkaban-exec
bigdata244 azkaban-exec
bigdata245 azkaban-web-server azkaban-exec-server mysql
azkaban-web目录
bin 启动脚本存放目录
conf 配置文件存放目录(没有的话从solo-server的目录中拷贝过来)
lib 依赖jar包存放目录
extlib 附加jar包存放目录(没有的话手动创建)
plugins 插件安装目录
web web资源文件
logs 日志存储目录
sql sql资源
azkaban-exec目录
bin 启动脚本存放目录
conf 配置文件存放目录(没有的话从solo-server的目录中拷贝过来)
lib 依赖jar包存放目录
extlib 附加jar包存放目录(没有的话手动创建)
plugins 插件安装目录
编译,安装过程
官网下载:3.47版本
进入到azkaban下面编译:[hadoop@bigdata245 azkaban-3.47.0]$ ./gradlew distTar
编译结果为:
azkaban-common : 常用工具类。
azkaban-db : 对应的sql脚本
azkaban-hadoop-secutity-plugin : hadoop 有关kerberos插件
azkaban-solo-server: web和executor 一起的项目。
azkaban-web/executor-server:azkaban的 web和executor的server信息
azkaban-spi: azkaban存储接口以及exception类
编译完成后:db、web、exec、solo四个目录的build/distributions/下生成其压缩包
将压缩包拷贝到:新建文件夹:mkdir azkaban
cp azkaban-db-0.1.0-SNAPSHOT.tar.gz /home/hadoop/app/azkaban/
cp azkaban-exec-server-0.1.0-SNAPSHOT.tar.gz /home/hadoop/app/azkaban/
cp azkaban-web-server-0.1.0-SNAPSHOT.tar.gz /home/hadoop/app/azkaban/
cp azkaban-solo-server-0.1.0-SNAPSHOT.tar.gz /home/hadoop/app/azkaban/
解压重命名
tar -zxvf azkaban-web-server-0.1.0-SNAPSHOT.tar.gz
tar -zxvf azkaban-exec-server-0.1.0-SNAPSHOT.tar.gz
tar -zxvf azkaban-db-0.1.0-SNAPSHOT.tar.gz
tar -zxvf azkaban-solo-server-0.1.0-SNAPSHOT.tar.gz
mv azkaban-db-0.1.0-SNAPSHOT azkaban-db
mv azkaban-web-server-0.1.0-SNAPSHOT azkaban-web
mv azkaban-solo-server-0.1.0-SNAPSHOT azkaban-solo
mv azkaban-exec-server-0.1.0-SNAPSHOT azkaban-exec
创建Azkaban元数据库:登录mysql,执行如下语句
mysql> create database azkaban_matadata;
Query OK, 1 row affected (0.00 sec)
mysql> use azkaban_matadata;
Database changed
mysql> source /home/hadoop/app/azkaban/azkaban-db/create-all-sql-0.1.0-SNAPSHOT.sql (会创建所有表)

配置keystore
在azkaban-web/bin目录下执行这条命令,在执行完这条命令之后,会生成一个文件:keystore.使用keytool创建SSL配置,keytool是JDK提供的一个工具,输入如下命令,可以查看
[root@bigdata245 ~]# find / -name keytool
/home/hadoop/app/jdk1.8/bin/keytool
/home/hadoop/app/jdk1.8/jre/bin/keytool
执行命令创建SSL配置
[hadoop@bigdata245 bin]$ keytool -keystore keystore -alias jetty -genkey -keyalg RSA
输入密钥库口令: azkaban
再次输入新口令: azkaban
您的名字与姓氏是什么? [Unknown]: 略过
您的组织单位名称是什么? [Unknown]: 略过
您的组织名称是什么? [Unknown]: 略过
您所在的城市或区域名称是什么? [Unknown]: 略过
您所在的省/市/自治区名称是什么? [Unknown]: 略过
该单位的双字母国家/地区代码是什么? [Unknown]: CN
CN=Unknown, OU=Unknown, O=Unknown, L=Unknown, ST=Unknown, C=CN是否正确?
[否]: Y
输入 <jetty> 的密钥口令 (如果和密钥库口令相同, 按回车):

将azkaban-solo下的conf plugins 和sql文件夹拷贝到azkaban-web目录下
[hadoop@bigdata245 azkaban-solo]$ cp -a conf/ plugins/ sql/ /home/hadoop/app/azkaban/azkaban-web/
配置web-server
配置azkaban-web/conf/azkaban.properties
# Azkaban Personalization Settings
azkaban.name=bigdata245 # 服务器UI名称,用于服务器上方显示的名字
azkaban.label=Aliyun bigdata245 Azkaban # 描述信息
azkaban.color=#FF3601 # 颜色
azkaban.default.servlet.path=/index
web.resource.dir=/home/hadoop/app/azkaban/azkaban-web/web/ #默认跟web目录,设置为绝对路径
default.timezone.id=Asia/Shanghai # 时区,默认为美国America/Los_Angeles
# Azkaban UserManager class
user.manager.class=azkaban.user.XmlUserManager #用户权限管理默认类
user.manager.xml.file=/home/hadoop/app/azkaban/azkaban-web/conf/azkaban-users.xml #用户配置,具体配置参见下文
# Loader for projects
executor.global.properties=/home/hadoop/app/azkaban/azkaban-web/conf/global.properties #globa配置文件所在位置
azkaban.project.dir=projects
database.type=mysql # 数据库类型
mysql.port=3306 # 端口
mysql.host=245 # 数据库连接IP
mysql.database=azkaban_matadata # 数据库实例名
mysql.user=root # 数据库用户名
mysql.password=P@ssw0rd # 数据库密码
mysql.numconnections=100 # 最大连接数
h2.path=./h2
h2.create.tables=true
# Velocity dev mode
velocity.dev.mode=false
# Azkaban Jetty server properties.
jetty.use.ssl=false
jetty.maxThreads=25 #最大线程数
jetty.port=8081 #jetty端口
jetty.ssl.port=8443 #jetty ssl端口号
jetty.keystore=/home/hadoop/app/azkaban/azkaban-web/bin/keystore #ssl的文件名,绝对路径
jetty.password=azkaban #ssl文件密码
jetty.keypassword=azkaban #jetty主密码与keystore文件相同
jetty.truststore=keystore #SSL文件名
jetty.trustpassword=azkaban #SSL文件密码
# Azkaban Executor settings
executor.port=12321 #执行服务器端口
# mail settings
mail.sender= #发送邮箱
mail.host= #发送邮箱smtp地址
# User facing web server configurations used to construct the user facing server URLs. They are useful when there is a reverse proxy between Azkaban web servers and users.
# enduser -> myazkabanhost:443 -> proxy -> localhost:8081
# when this parameters set then these parameters are used to generate email links.
# if these parameters are not set then jetty.hostname, and jetty.port(if ssl configured jetty.ssl.port) are used.
# azkaban.webserver.external_hostname=myazkabanhost.com
# azkaban.webserver.external_ssl_port=443
# azkaban.webserver.external_port=8081
job.failure.email=
job.success.email=
lockdown.create.projects=false
cache.directory=cache #缓存目录
# JMX stats
jetty.connector.stats=true
executor.connector.stats=true
# Azkaban plugin settings
azkaban.jobtype.plugin.dir=/home/hadoop/app/azkaban/azkaban-web/plugins/jobtypes
端口号使用规则:jetty.ssl.port > jetty.port。但是使用jetty.ssl.port的前提是jetty.use.ssl=true。这个配置表示开启ssl【Secure Sockets Layer】安全套接层,否则使用jetty.port端口。在azkaban-web/conf目录下添加log4j.properties
[hadoop@bigdata245 conf]$ touch log4j.properties
log4j.rootLogger=INFO,C
log4j.appender.C=org.apache.log4j.ConsoleAppender
log4j.appender.C.Target=System.err
log4j.appender.C.layout=org.apache.log4j.PatternLayout
log4j.appender.C.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%n添加MySQL驱动在azkaban-web目录下创建文件夹:mkdir extlib
将lib目录下的mysql驱动复制到extlib目录下
[hadoop@bigdata245 azkaban-web]$ cp lib/mysql-connector-java-5.1.28.jar extlib/
添加管理员用户以及密码
进入azkaban-web/conf目录,修改azkaban-users.xml,这个文件存放用户登录信息以及权限信息。同时增加管理员用户admin
<user username="admin" password="admin" roles="admin"/>
azkaban-web目录下创建logs文件用于存放日志文件 # mkdir logs
注意:多个执行器模式也就是分布式执行模式下运行,需要在webserver配置中启用多个执行器模式。确认在azkaban.properties中具有以下属性。azkaban.use.multiple.executors和azkaban.executorselector.comparator。*是必需的属性。
注意:azkaban.use.multiple.executors 多重执行模式不予以尊重
配置多节点执行服务器在azkaban-web/conf/azkaban.properties里添加
azkaban.use.multiple.executors =true
azkaban.executorselector.filters = StaticRemainingFlowSize,MinimumFreeMemory,CpuStatus
azkaban.executorselector.comparator.NumberOfAssignedFlowComparator = 1
azkaban.executorselector.comparator.Memory = 1
azkaban.executorselector.comparator.LastDispatched = 1
azkaban.executorselector.comparator.CpuUsage = 1
以确认使用的是分布式方式,随后提交的job会根据情况自行选择执行服务器,否则默认只使用本地执行服务器。配置exec-server
拷贝azkaban-web目录下的conf和extlib到azkaban-web目录下
cp -a conf/ extlib/ /home/hadoop/app/azkaban/azkaban-exec/
配置azkaban-web/conf/azkaban.properties
default.timezone.id=Asia/Shanghai
# Loader for projects
executor.global.properties=/home/hadoop/app/azkaban/azkaban-exec/conf/global.properties
azkaban.project.dir=/home/hadoop/app/azkaban/azkaban-exec/bin/projects
# Azkaban plugin settings
azkaban.jobtype.plugin.dir=plugins/jobtypes
database.type=mysql
mysql.port=3306
mysql.host=245
mysql.database=azkaban_matadata
mysql.user=root
mysql.password=P@ssw0rd
mysql.numconnections=100
# Azkaban Executor settings
executor.maxThreads=50
executor.port=12321
executor.flow.threads=25
#分布式节点必配
azkaban.use.multiple.executors=true
azkaban.executorselector.filters=StaticRemainingFlowSize,MinimumFreeMemory,CpuStatus
azkaban.executorselector.comparator.NumberOfAssignedFlowComparator=1
azkaban.executorselector.comparator.Memory=1
azkaban.executorselector.comparator.LastDispatched=1
azkaban.executorselector.comparator.CpuUsage=1在azkaban-exec/conf目录下添加log4j.properties
[hadoop@bigdata245 conf]$ touch log4j.properties
log4j.rootLogger=INFO,C
log4j.appender.C=org.apache.log4j.ConsoleAppender
log4j.appender.C.Target=System.err
log4j.appender.C.layout=org.apache.log4j.PatternLayout
log4j.appender.C.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%n在mysql的azkaban库中添加各个执行服务器的ip/域名和端口:
配置多执行器模式的执行程序,目前没有执行程序管理UI。需要在数据库中配置执行程序。需要将所有执行程序插入mysql DB以进行执行程序设置。验证执行程序表中的正确执行程序是否处于活动状态。
>insert into executors(host,port) values("bigdata245",3306);
>insert into executors(host,port) values("bigdata244",3306);
>insert into executors(host,port) values("bigdata243",3306);启动,先启动exec-server(执行器),然后启动web-server(web服务)
cd azkaban-exec/bin:./start-exec.sh
cd azkaban-web/bin:./start-web.sh
注意:在bin目录下启动会生成一堆文件,如果用脚本启动注意修改配置路劲
启动完成后,三台节点下可以查看到对应的进程
AzkabanExecutorServer 3
AzkabanWebServer 1

问题1;
The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.)
Caused by: java.net.ConnectException: Connection refused (Connection refused)
如果出现这两个问题,去配置文件查看mysql链接是否出错,还有mysql配置执行服务器的语句是否有问题
访问Azkaban UI界面

输入用户名密码azkaban/azkaban登录
修改如下配置(azkaban默认启动规则是在哪里启动在哪里生成一堆文件)
exec/bin
[hadoop@bigdata243 bin]$ cat start-exec.sh
#!/bin/bash
script_dir=$(dirname $0)
# pass along command line arguments to the internal launch script.
${script_dir}/internal/internal-start-executor.sh "$@" >/home/hadoop/app/azkaban/azkaban-exec/bin/executorServerLog__`date +%F+%T`.out 2>&1 &
[hadoop@bigdata243 bin]$ pwd
/home/hadoop/app/azkaban/azkaban-exec/bin
web/bin
[hadoop@bigdata245 bin]$ pwd
/home/hadoop/app/azkaban/azkaban-web/bin
[hadoop@bigdata245 bin]$ cat start-web.sh
#!/bin/bash
script_dir=$(dirname $0)
${script_dir}/internal/internal-start-web.sh >/home/hadoop/app/azkaban/azkaban-web/bin/webServerLog_`date +%F+%T`.out 2>&1 &
配置azkaban-exec/conf/azkaban.properties
azkaban.project.dir=/home/hadoop/app/azkaban/azkaban-exec/bin/projects
配置azkaban-web/conf/azkaban.properties
azkaban.project.dir=/home/hadoop/app/azkaban/azkaban-web/bin/projects
Azkaban测试及使用

projects:最重要的部分,创建一个工程,所有flows将在工程中运行。
Scheduling:显示定时任务
Executing:显示当前运行的任务
History:显示历史运行任务
主要介绍Projects部分,在创建工程前,我们先了解下之间的关系,一个工程包含一个或多个flows,一个flow包含多个job。job是你想在azkaban中运行的一个进程,可以是简单的linux命令,可是java程序,也可以是复杂的shell脚本、或者python脚本,当然,如果你安装相关插件,也可以运行插件。一个job可以依赖于另一个job,这种多个job和它们的依赖组成的图表叫做flow。
web-server节点:负责项目作业管理(上传和分发)
exec-server节点:负责具体执行的executor会解析job文件
一、commond 类型单一Job
1.创建工程

Flows:工作流程,有多个job组成
Permissions:权限管理
Project Logs:工程日志
2.创建Job
job就是一个以.job结尾的文本文件,例如创建一个job,名为hello.job,用于打印hello azkaban
3.打包
将创建的job打包成.zip压缩文件,注意只能是.zip格式

4.使用Azkaban UI 界面创建project并上传压缩包
点击Execute执行
执行后,点击Detail,查看日志

azkaban-exec/plugins/jobtypes/commonprivate.properties配置文件,内容中添加:azkaban.native.lib=false
关闭重启服务
如果还不行,编译源码
源码路径:/home/hadoop/app/compile_azkaban3.47/azkaban-common/src/main/java/azkaban/jobExecutor/ProcessJob.java
修改如下:final boolean isExecuteAsUser = this.sysProps.getBoolean(EXECUTE_AS_USER, false);

重新编译之后将azkaban/azkaban-exec-server/build/distributions目录下的azkaban-exec-server-3.48.0-8-gdc851ec.tar.gz 解压重命名,然后再修改配置替换旧的azkaban-exec-server,最后重启exec和web服务即可
再次运行就好了
二、commond 类型多JOb 工作流 flow
1.创建项目
首先,创建一个项目,名为 Com_Job
2.job 创建
假设有这么一种场景:
(1).task1 依赖 task2
(2).task2 依赖 task3
(3).task3 依赖 task4
说明:假设task1是一个计算指标任务,task2 给 task1 提供执行需要的基础数据
task3 给 task2 提供数据,以此类推。
3.flow 创建
多个jobs和它们的依赖组成flow。怎么创建依赖,只要指定dependencies参数就行了
定义4个job:
(1).run_task1.job:计算业务指标数据
(2).run_task2.job:计算task1所需要的数据
(3).run_task3.job:计算task2所需要的数据
(4).run_task4.job:从 slaves 中抽取源数据
依赖关系:
task1 依赖 task2,task2 依赖 task3,task3 依赖 task4
4个job文件内容如下(这里以执行python为例)
# run_task1.job
type = command
command = python /home/hadoop/pyshell/run_task1.py
dependencies = run_task2
# run_task2.job
type = command
command = python /home/hadoop/pyshell/run_task2.py
dependencies = run_task3
# run_task3.job
type = command
command = python /home/hadoop/pyshell/run_task3.py
dependencies = run_task4
# run_task4.job
type = command
command = python /home/hadoop/pyshell/run_task4.py
创建python脚本
[hadoop@bigdata245 pyshell]$ touch run_task1.py
[hadoop@bigdata245 pyshell]$ touch run_task2.py
[hadoop@bigdata245 pyshell]$ touch run_task3.py
[hadoop@bigdata245 pyshell]$ touch run_task4.py
4个文件内容如下
run_task1.py
#!/usr/bin/python3
# -*- coding: utf-8 -*-
print("task1:计算业务指标数据...")
run_task2.py
#!/usr/bin/python3
# -*- coding: utf-8 -*-
print("task2:计算基础数据,为task1提供数据")
run_task3.py
#!/usr/bin/python3
# -*- coding: utf-8 -*-
print("task3:数据清洗,为task2提供数据")
run_task4.py
#!/usr/bin/python3
# -*- coding: utf-8 -*-
print("task4:从Slaves中抽取源数据")
3.将上述 job 打成zip包,上传至 azkaban
上传完成后,点击右侧Execute Flow按钮,查看流程视图

Flow view:流程视图。可以禁用,启用某些job
Notification:定义任务成功或者失败是否发送邮件
Failure Options:定义一个job失败,剩下的job怎么执行
Concurrent:并行任务执行设置
Flow Parametters:参数设置。
4.执行
(1).执行一次,点击右下角Execute
(2).定时执行,点击左下角Schedule


设置完成后,执行右下角schedule,即完成调度配置,azkaban这里的配置与linux下的crontab类似
想要查看job的调度列表,切换到Schedule菜单即可
5.查看项目flow中各个Job的执行情况

绿色代表成功,蓝色是运行,红色是失败。可以查看job运行时间,依赖和日志,点击details可以查看各个job运行情况
三、MapReduce 任务
Azkaban 执行 MapReduce 任务,我们以 WordCount 为例
1.准备数据
[hadoop@bigdata245 ~]$ hadoop fs -mkdir -p /azkaban/input
[hadoop@bigdata245 data]$ hadoop fs -put words.txt /azkaban/input
使用hadoop提供的jar统计单词数量
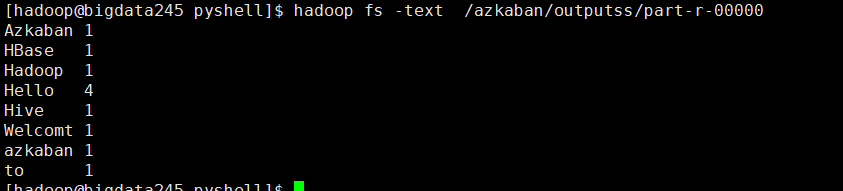
[hadoop@bigdata245 mapreduce]$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar wordcount /azkaban/input/* /azkaban/outputs/
运行结果

2.创建项目
3.job创建
job
# mapreduce_wordcount.job
type = command
command=sh /home/hadoop/pyshell/wordcount.sh

4.打包上传,执行
5.查看运行结果
azkaban上打印的日志显示已经成功

四、Hive 脚本任务
1.创建项目
hive_export_to_mysql
2.job创建
我们要完成,hive中创建表,加载数据,然后导出数据到mysql,分为两个job
hive_task1:将hive中的数据导出到mysql中
hive_task2:hive中创建表,加载数据
依赖关系:hive_task1 依赖 hive_task2
3.flow创建
job 文件内容如下
# hive_task1.job
type = command
command = sh /home/hadoop/pyshell/hive_task1.sh
dependencies = hive_task2
# hive_task2.job
type = command
command = sh /home/hadoop/pyshell/hive_task2.sh
脚本内容如下
[hadoop@bigdata245 pyshell]$ cat hive_task1.sh
#!/bin/bash
/home/hadoop/app/sqoop1/bin/sqoop export \
--connect jdbc:mysql://bigdata245:3306/sqoop \
--username root --password P@ssw0rd \
--table EMP \
--export-dir /user/hive/warehouse/test.db/emp \
--input-fields-terminated-by ',' \
--input-null-string 'null' --input-null-non-string 'null' \
-m 1
[hadoop@bigdata245 pyshell]$ cat hive_task2
#!/bin/bash
hive -f /home/hadoop/pyshell/test.sql
sql文件 test.sql内容如下
[hadoop@bigdata245 pyshell]$ cat test.sql
create database if not exists test;
use test;
drop table if exists emp;
create table emp(
empno int,
ename string,
job string
)
row format delimited fields terminated by ',';
load data local inpath '/home/hadoop/pyshell/emp.txt' overwrite into table emp;
emp.txt文件内容如下
[hadoop@bigdata245 pyshell]$ cat emp.txt
1001,Tom,Java
1002,Jack,PHP
1003,Harvey,BigData
1004,David,IOS
1005,Kett,DBA
4.打包上传
5.执行,查看运行结果
执行前记得先在mysql中创建表emp,sql语句如下
DROP TABLE IF EXISTS `EMP`;
CREATE TABLE `EMP` (
`empno` int(11) DEFAULT NULL,
`ename` varchar(255) DEFAULT NULL,
`job` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
SET FOREIGN_KEY_CHECKS=1;



