机器学习方法在医药研究中已经应用了几十年。与贝叶斯方法相结合的指纹类型分子描述符的相对易用性和可用性使得该方法广泛应用于与药物发现相关的各种端点阵列。深度学习是最新的机器学习算法,从对接到虚拟筛选等许多制药应用都受到关注。深
度学习是一种基于多层隐层的人工神经网络,在许多人工智能应用中得到了广泛的应用。我们之前已经提出,需要将不同的机器学习方法与适用于药物研究的不同数据集阵列中的深度学习进行比较。与药物研究相关的终点包括吸收、分布、代谢、排泄和毒性(ADME/Tox)特性,以及对病原体的活性和药物发现数据集。
在本研究中,我们使用了溶解度、似度、hERG、KCNQ1、黑死病、恰加斯病、肺结核、疟疾等数据集,比较了使用FCFP6指纹的不同机器学习方法。这些数据集表示整个细胞屏幕、单个蛋白质、物理化学特性以及具有复杂端点的数据集。我们的目的是评估在使用AUC、F1分数、Cohen’s kappa、Matthews相关系数等一系列指标进行评估时,深度学习是否对测试有任何改善。
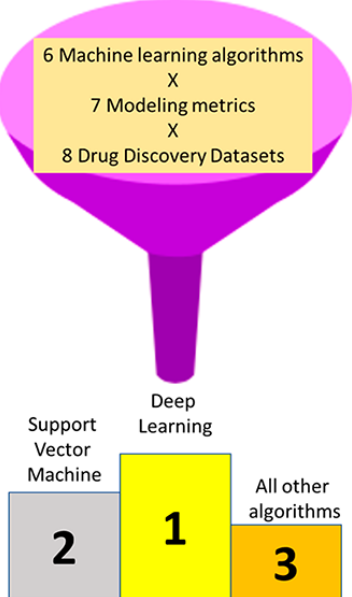
深度神经网络(Deep Neural Networks, DNN)对指标或数据集的归一化得分排序高于支持向量机(SVM),而SVM又高于其他所有机器学习方法。 使用雷达类型图可视化训练和测试集的这些属性,表明模型在什么时候是较差的或者可能是训练过度的。这些结果还表明,需要使用更大规模的比较、前瞻性测试以及不同指纹和DNN架构的评估等多个指标来进一步评估深度学习。
一、简介
药物发现目前正处于这样一个阶段:PubChem、ChEMBL以及越来越多由高通量筛选和高通量生物学(包括全细胞表型筛选、酶、受体等)创建的其他数据库的公共数据量不断增加,使其完全处于“大数据”领域。我们面临着重大的挑战。我们不再局限于少数分子及其性质,我们现在有成千上万的分子和几十个性质要考虑。我们如何挖掘、使用这些数据,并希望从中学习,从而使药物发现更有效、更成功?
一个方法是利用化学信息使用机器学习处理这些大数据的方法,如使用支持向量机(SVM), K近邻(KNN),朴素贝叶斯,决策树等已越来越多地使用。这些方法可以用于二进制分类、多类分类,或值的预测。
近年来,深度人工神经网络(包括卷积网络和递归网络)在模式识别和机器学习领域赢得了众多的竞争。深度学习通过引入以其他更简单的表示形式表示的表示来解决表示学习中的核心问题。n层神经网络如图1所示。
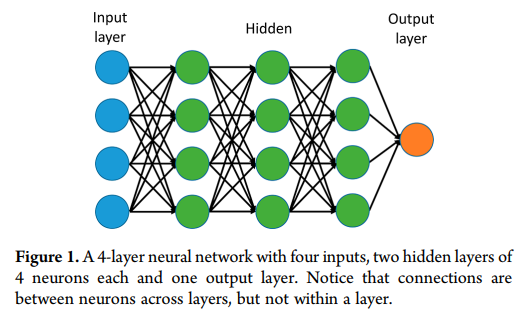
值得注意的是,单层神经网络描述的是一个没有隐含层的网络,其中输入直接映射到输出层。在这个意义上,逻辑回归或支持向量机只是单层神经网络的一个特例。在我们的工作中,为了简化深度神经网络(DNN)的表示,我们将只计算隐藏层。通常1−2隐藏层神经网络被称为浅神经网络和3或更多的隐藏层神经网络被称为深层神经网络。
最近的一篇综述讨论了深度学习在药物研究中的发展和应用,这种方法在其他地方的图像和语言学习中被证明是非常成功的。以前深度学习主要用于无监督学习和噪声数据。将深度学习用于药物应用的有限努力表明,与其他方法相比,需要进一步探索其在化学信息学方面的效用。
深度学习在生物信息学和计算生物学中得到了较为广泛的应用。深度学习也被用于预测性质,如水溶性,使用四个公布的数据集,并与其他机器学习方法比较显示出良好的10倍交叉验证(10-fold cross validation)结果。
到目前为止,Merck已经对深层神经网络进行了比较,并将其与随机森林进行了比较,以使用大型定量结构活动关系(QSAR)数据集。他们发现在15个数据集中的11个表现要好于随机森林,在第二次使用时间分割测试集的评估中,15个数据集中的13个表现优于随机森林。但是Merck没有研究其他的机器学习方法。与其他机器学习方法一样,深度学习模型得到验证的最大例子之一是Tox21挑战。在核受体和应激反应数据集上,多任务学习的深度学习略优于最接近共识的ANN方法。最近,有一个小组提出了一些分子机器学习的数据集,并将这些数据集与选定的机器学习方法进行了比较。第二组用7个ChEMBL数据集评价了若干机器学习方法,但只着重于评价性能的单一指标。深度学习常常单独应用于单个数据集,而不是与许多可用的替代方法进行比较。有可能有更多的数据集可以从深度学习中受益,尽管它们可能更小。
这些机器学习方法越来越多地用于化合物的虚拟筛选,通过用活性化合物丰富筛选的化合物集,可以更有效地利用高通量筛选(,HTS)资源。此外,这种机器学习方法还可以用于药物的吸收、分布、代谢、排泄和毒性(ADME/Tox)特性,因为这些因素可以影响药物发现过程的成功,并且它们的早期评估可以预防失败。过去的研究表明这些计算方法可以极大地影响药物发现效率。
在过去的十年中,我们和其他人越来越关注贝叶斯方法,因为它们的易用性和一般适用性,使用最大直径6的分子函数类指纹和其他几个简单的描述符。这项工作的大部分集中在考虑细胞毒性的结核分枝杆菌模型上,并对其进行前瞻性评估,以显示与随机筛查相比,结核分枝杆菌的高命中率。此后,我们利用查加斯病和埃博拉病毒的数据集,对批准的药物以及模型ADME特性(如水溶性、小鼠肝微粒体稳定性、Caco-2细胞通透性、62个毒理学数据集和转运体)进行了重新利用。通过制作指纹,以及贝叶斯模型构建算法的开源,有潜力进一步拓展这方面的工作。
本研究的主要目的是 评估在药物发现和ADME/Tox数据集的其他计算方法中,使用一系列指标进行评估时,深度学习是否对测试有任何改善。在此过程中,我们开发了一种方法,使深度学习模型更容易获取。
二、实验
2.1 实验环境
所有的计算都是在一个双核处理器,四核(英特尔E5640)服务器上完成的,运行CentOS 7, 96GB内存和两个特斯拉K20c GPU。
安装了以下软件模块:
nltk 3.2.2、scikit-learn 0.18.1、Python 3.5.2、Anaconda 4.2.0(64位)、Keras 1.2.1、Tensorflow 0.12.1、Jupyter Notebook 4.3.1。
2.2数据集和描述符
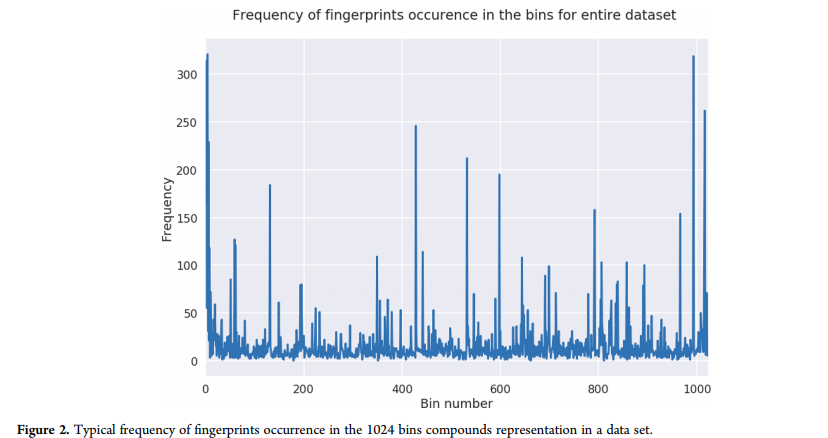
利用公开的用于不同类型活性预测的不同药物发现数据集开发预测管道(表1)。Clark等人使用相同的数据集,探索一系列贝叶斯模型在ADME/Tox等理化性质预测中的适用性。在目前的FCFP6指纹研究中,使用RDKit (http://www.rdkit.org/)从SDF文件中计算出1024个bin数据集。在图2所示的数据集中,指纹出现的典型频率出现在1024个容器的复合表示中。

2.3机器学习
开发了两个通用预测方法。
第一个方法仅使用经典机器学习(CML)方法构建,如伯努利朴素贝叶斯、线性逻辑回归、AdaBoost决策树、随机森林和支持向量机。开源的Scikit-learn (http://scikit-learn.org/stable/, CPU用于训练和预测)使用ML python库构建、调优和验证这个方法中包含的所有CML模型。
第二个方法使用不同复杂性的深度神经网络(DNN)学习模型构建,使用Keras (https://keras.io/)、一个深度学习库和Tensorflow (www.tensorflow.org, GPU training and CPU for prediction)作为后端。开发的方法包括将输入数据集随机分割为训练(80%)和测试(20%)数据集,同时在每次分割(分层分割)中保持活动类比与非活动类比的相等比例。因此,所有模型的调优和超参数搜索都是通过对训练数据进行4倍交叉验证来进行的,这样可以更好的进行模型泛化。提供了一个示例 Jupyter notebook。
【示例程序】
2.4 数据分析
使用到的评估方法:
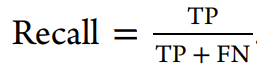
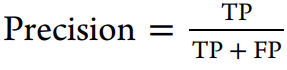
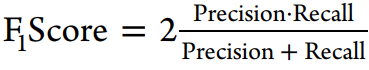
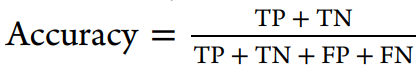
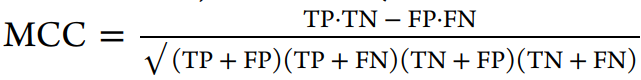
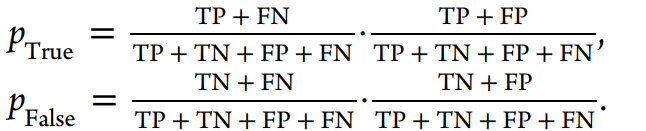
三、结果
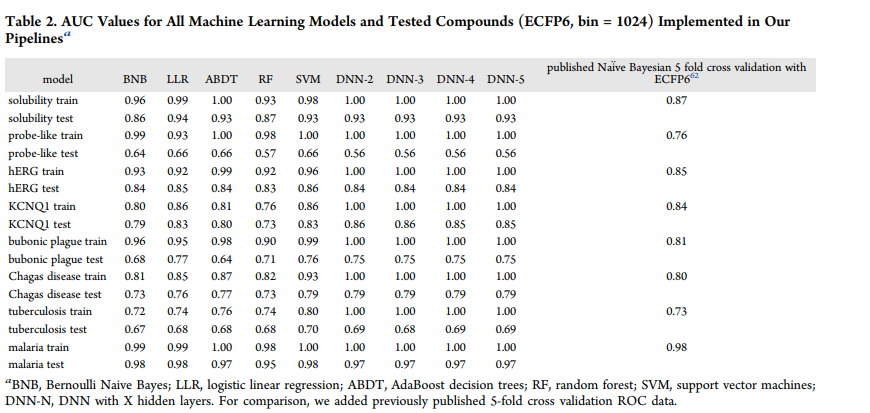
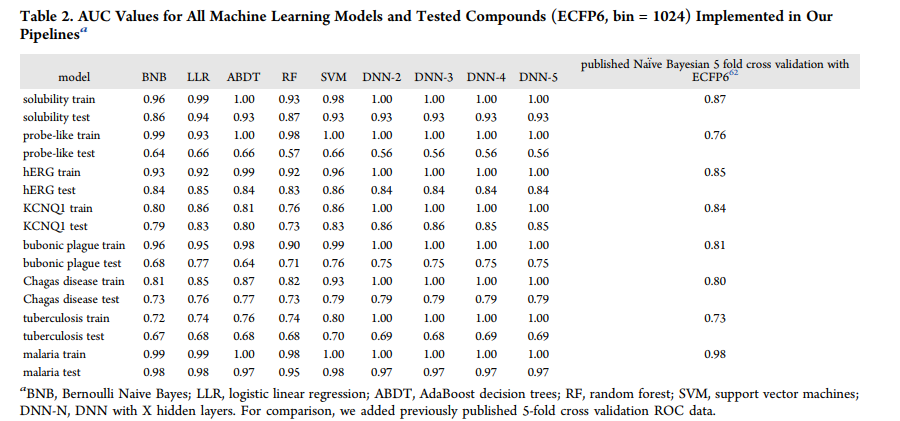
F1-score AUC,准确性,卡帕,马修斯相关性,精度和召回的所有训练值表示为模型化合物FCFP6指纹在1024箱总结(表2和表S1−16)虽然个别模型文件也提供(支持信息)。
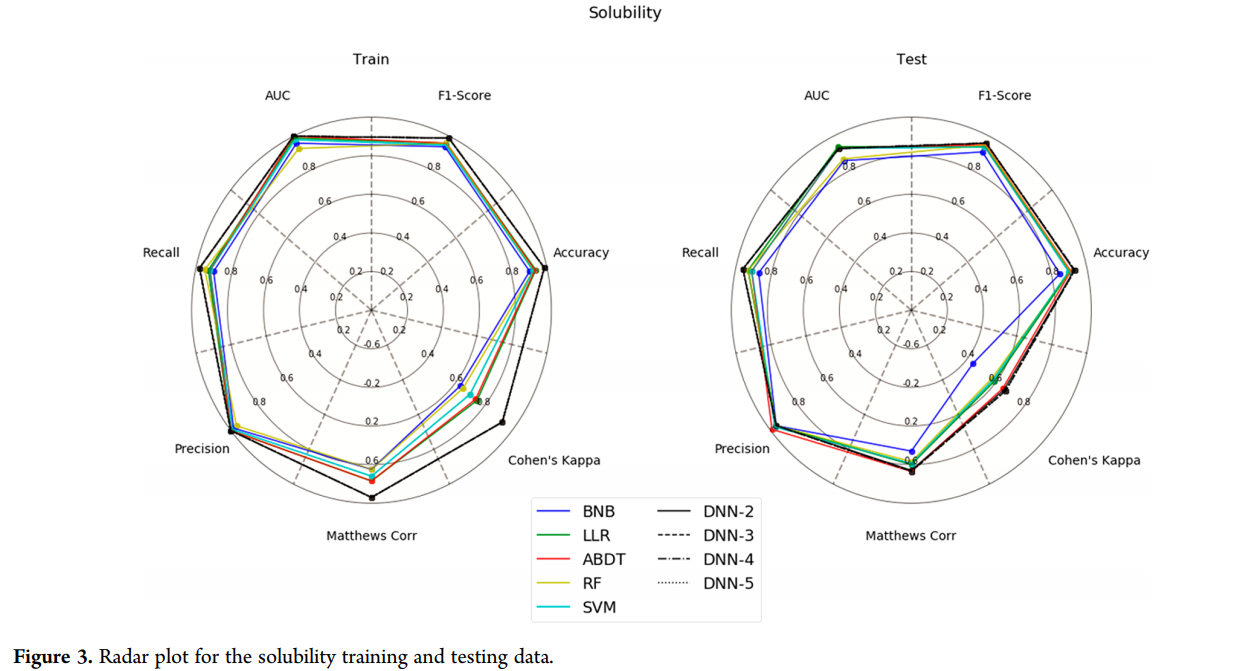
为了清晰起见,我们按照每个数据集、训练集和测试集对所有指标进行了分组,并将它们表示为雷达图。然而,在本例中,我们使用了不同的描述符和建模算法源FCFP6 vs ECFP6,以及RDKit vs CDK。在许多情况下,SVM模型的测试集通常比同一方法中的任何其他模型都要好。
当分析雷达图时,很容易看出哪些模型可能训练过度。在这种情况下,模型训练集的所有指标的得分都很高,而测试集的得分则低得多。图的形状也可以表示模型的质量。测试集的圆圈越大,模型就越好。
溶解度模型(图3)是一个很好的平衡模型的例子。训练集和测试集实际上都由相似的圆形图表示,很明显,BNB方法在大多数指标中表现最差。
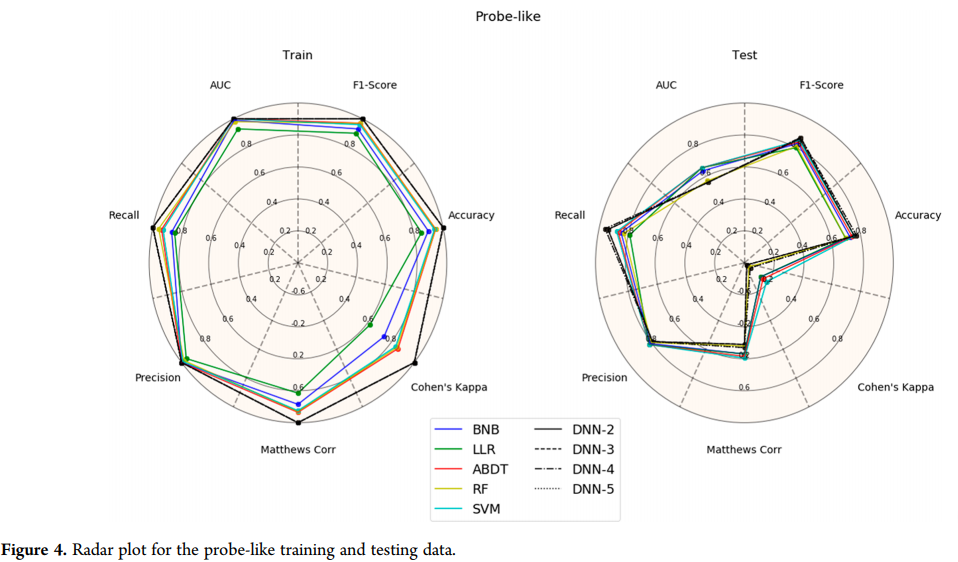
probe样模型(图4)对测试集的分数进行了不规则的排列,这表明它在所有方法中对Cohen 's Kappa的表现都很差。
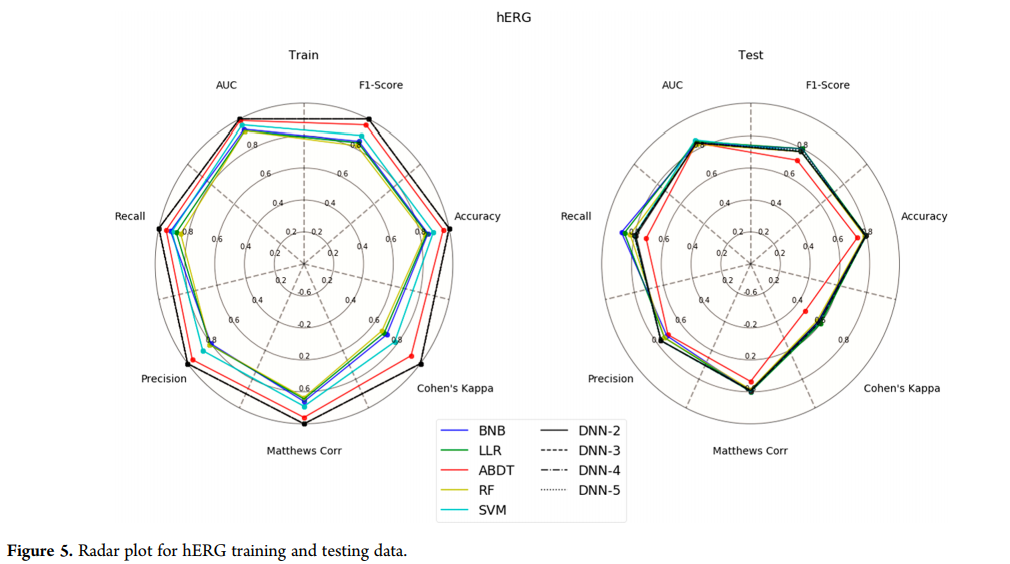
hERG模型的测试集(图5)显示,大多数方法在指标之间是可比较的,ABDT在测试集中表现最差
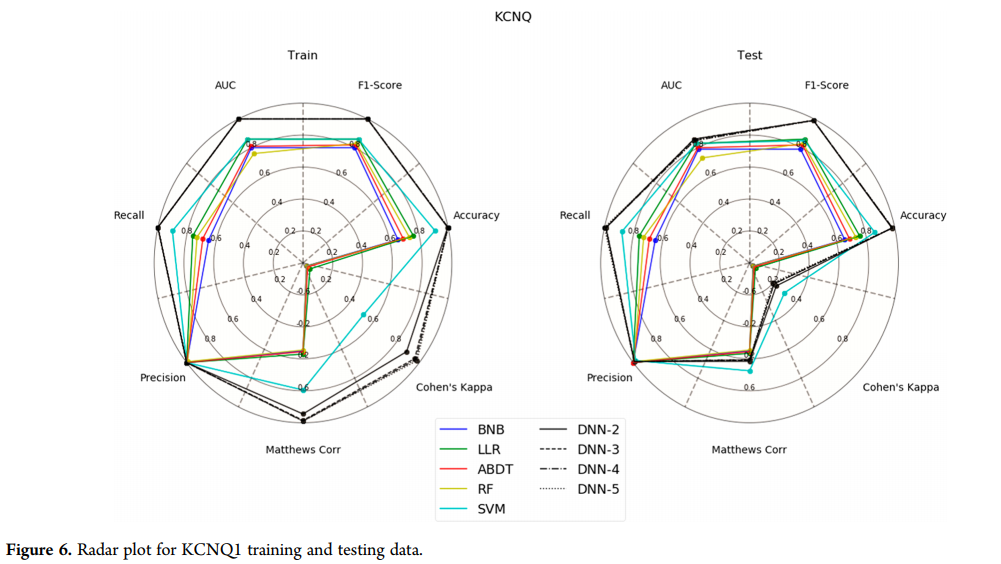
总体而言,Cohen’s Kappa是该数据集最敏感的度量标准。KCNQ1模型(图6)显示,DNN和SVM在训练和测试方面优于其他方法,Matthews相关性和Cohen’s Kappa评分显著低于所有其他指标
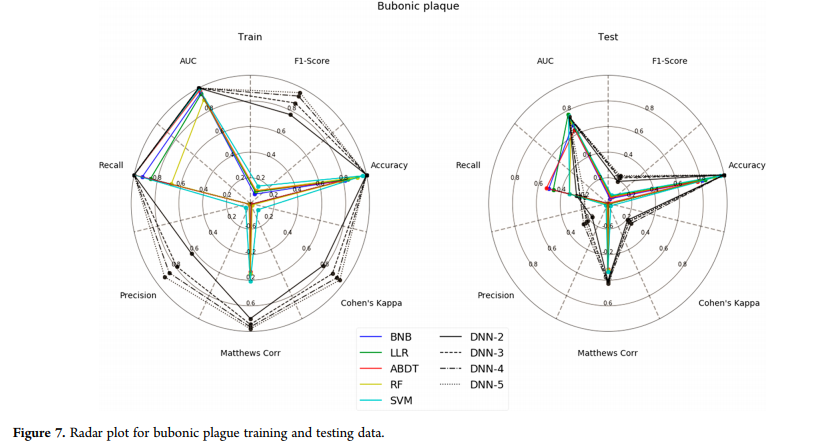
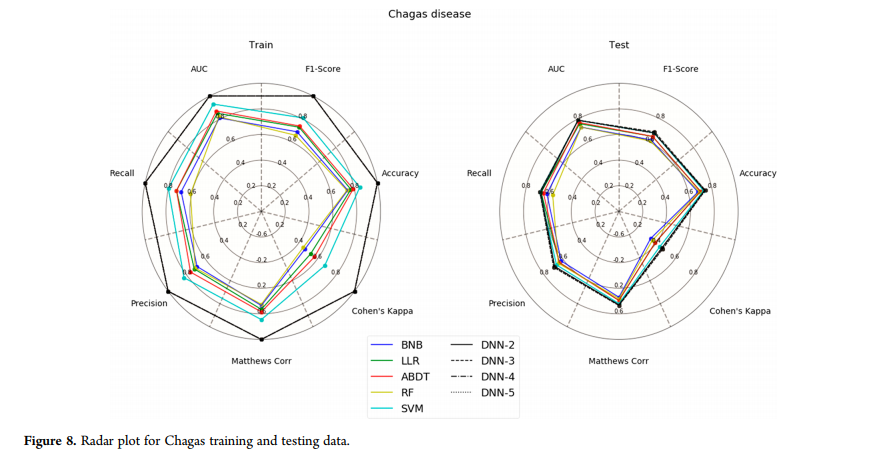
黑死病模型(图7)是一个困难的例子,DNN在训练和测试中很容易胜过所有方法(AUC, Matthews correlation and accuracy metric表现最好)。Chagas疾病数据集(图8)再次显示,以Cohen’s kappa为最敏感的指标,DNN具有较好的训练和测试性能。
Chagas疾病数据集(图8)再次显示,以Cohen’s kappa为最敏感的指标,DNN具有较好的训练和测试性能
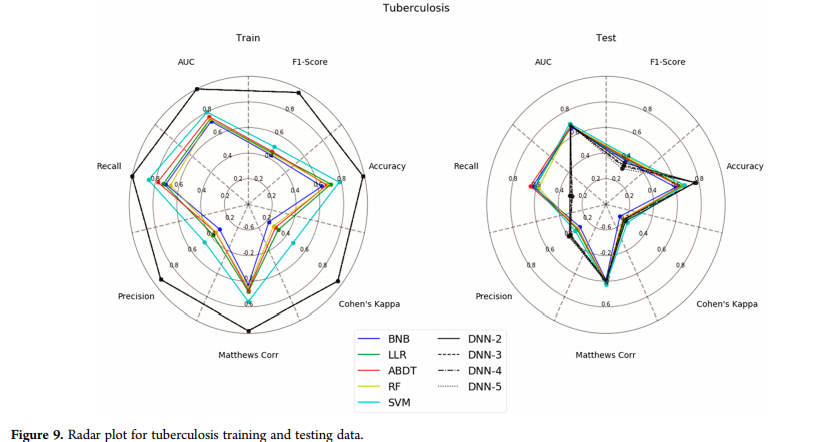
结核病数据集(图9)是另一个例子,除了召回统计数据外,DNN在培训方面比所有方法都要好得多,在测试集方面也比所有方法差得多。在测试集的所有方法中,精确度、f1评分和Cohen 's Kappa都很差。
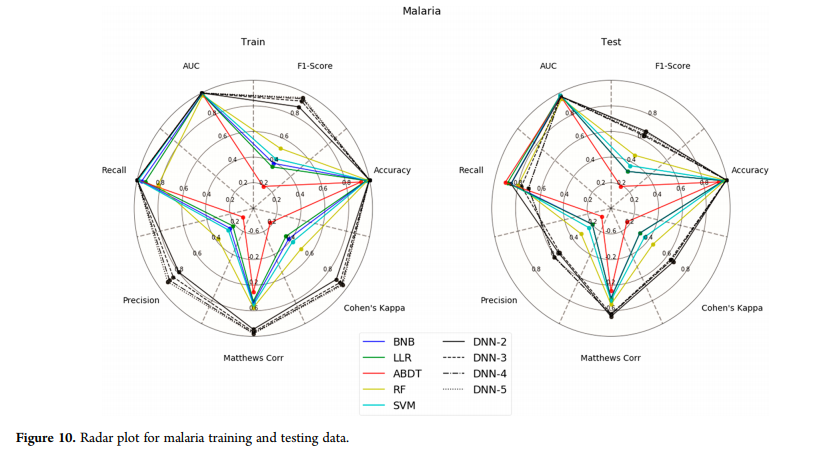
疟疾数据集(图10)显示了DNN对训练和测试集的影响,与其他机器学习方法相比,DNN在准确率、f1评分和Cohen’s Kappa方面都有很大提高
总的来说,除了probe样数据集的AUC性能外,DNN模型在外部测试集预测中表现良好。对于AUC, DNN-3在8个数据集中的6个上优于BNB(表2)。
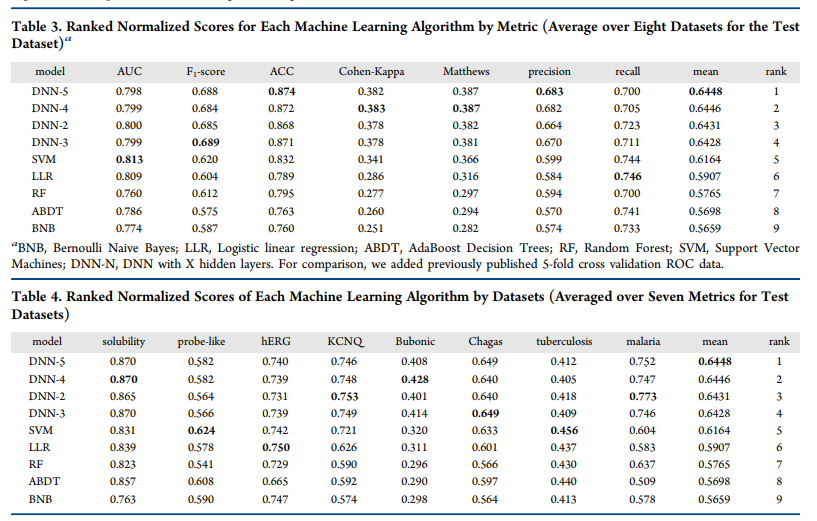
为了进一步了解哪种模型的性能最好,我们使用了按度量(表3)和数据集(表4)对每个机器学习算法进行排序的标准化得分。这种方法以前曾被其他人用于比较多种机器学习方法和性能标准。当模型以指标或数据集进行排序时,深度学习(DNN-5和DNN-4)的排名高于SVM,其他方法均低于此(表3和表4)。
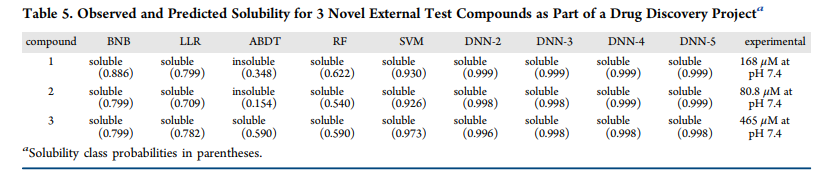
我们使用本研究中开发的所有不同的溶解度机器学习模型,对我们的一个药物发现项目中的3种化合物的溶解度进行了评估,如表5: