一、准备
为了更深入的理解logistic regression,笔者基本采用纯C++的手写方式实现,其中矩阵方面的运算则调用opencv,数据集则来自公开数据集a1a。
实验环境:
关于配置方面的操作,请参考一下链接:Win10下OpenCV环境搭建(VS2017+OpenCV3.2.0)
二、logistic regression理论基础
如果想系统的了解logistic regression,笔者推荐吴恩达的深度学习系列课程,尤其是其中的实践作业,需要认真做。
下面笔者简略的介绍下logistic regression。
如上图就是一个logistic regression的典型例子:
- 一张猫的图片根据rgb可以看成是0-255的之间的数字,所以图片就转换成为了一列向量X。
- 定义一个维度为(1,X0)维度的参数W行向量,其中X0指图片列向量的行数。
- 将W和X相乘(矩阵相乘),再加上偏置b(为实数),则得到Z。
- 再用sigmoid进行限制到(0,1)范围,输出A。
- 定义loss,并使用梯度下降算法,更新参数W和b,使A的输出越来越接近标签Y。
下面是一些基本公式:
For one example
:
The cost is then computed by summing over all training examples:
sigmoid是限制输出的结果在(0,1)内,它的图像如下:
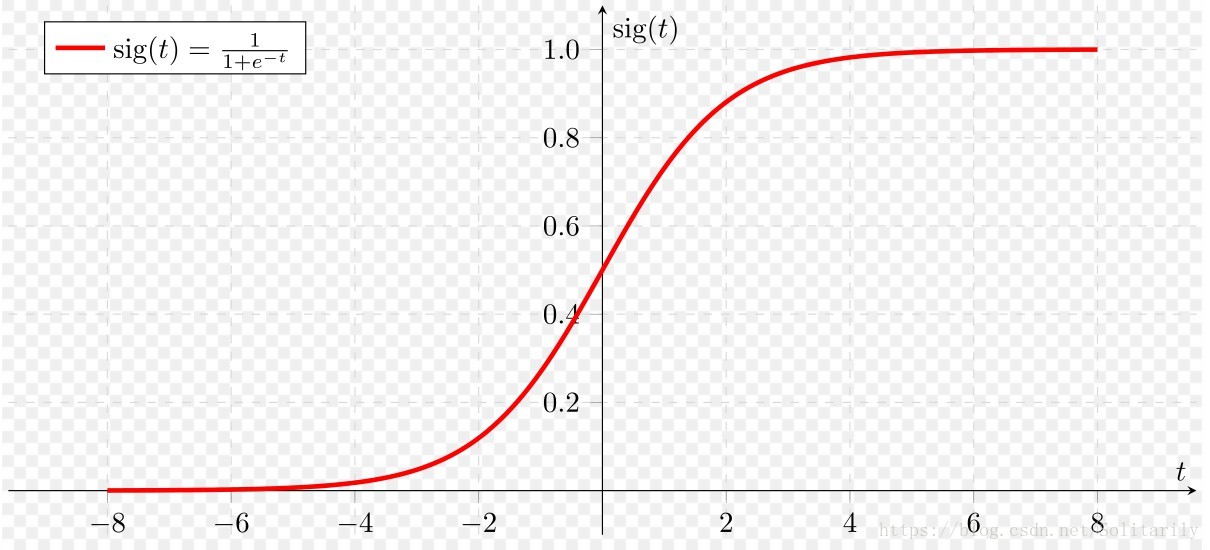
上面loss的公式采用交叉熵代价函数。
梯度下降算法:
梯度下降的一个最直观的解释:可以看成从山上走下山的过程。
参考链接:
三、实践
笔者采用的是a1a数据集,其原型为UCI的Adult Data Set ,其大概意思是根据人的特征来判断你是否每年的工资大于50k,所以这是一个二分分类问题。
a1a数据集对其进行了简化,其一共有123个特征,如下所示为其一行的数据-1 5:1 6:1 17:1 21:1 35:1 40:1 53:1 63:1 71:1 73:1 74:1 76:1 80:1 83:1,其中-1表示未能超过50k(即负类,实际编程可以置为0),接着我们可以初始化一个一行零向量(1,123),5:1表示第5个位置为1,以下类推……这样我们对其数据就有了个大概认识。
接着我们就开始编写处理数据的函数。这里需要一些基础知识,可以参考以下博客:
void creatMat(Mat &x,Mat &y,String fileName) {
int line_count = 0;//记录行数,在矩阵赋值时起到用处
char buffer[256];//缓存区
ifstream in(fileName);//定义读取文件数据流
if (!in.is_open()) {
cout << "Error opening file"; exit(1);
}
while (!in.eof())
{
in.getline(buffer, 100);//按行读取
//因为读取的是字符串,下面采用stringstream和atof()将字符串转为浮点数
stringstream stream;
stream << buffer;
string temp_s;//这里的目的主要是跳过空格
stream >> temp_s;
double num1 = atof(temp_s.c_str());//num1为类别标签即-1或+1
if (num1 == 1.0) {
y.at<double>( 0,line_count) = num1;//y矩阵即为标签矩阵,其已经被初始化为0,所以只要将1的标签赋值即可
}
while (stream >> temp_s) {
int index = temp_s.find(':');
string temp1_s = temp_s.substr(0, index);//这里模仿split()函数
double t1 = atof(temp1_s.c_str());
string temp2_s = temp_s.substr(index + 1, temp_s.length());
double t2 = atof(temp2_s.c_str());
x.at<double>(t1-1,line_count) = t2;//赋值
}
line_count++;
}
}然后我们开始编写sigmoid公式,因为C++和opencv都不带这个公式。公式为:
Mat sigmoid(const Mat &original) {
cv::Mat response = original.clone();//防止未初始化和维度不同
double temp;
for (int i = 0; i < original.rows; i++) {
for (int j = 0; j < original.cols; j++) {
temp = original.at<double>(i, j);
response.at<double>(i, j) = 1.0 / (1.0 + exp(-temp));
}
}
return response;
}我们继续开始编写cost,公式如下:
其中还需用到对矩阵的log,代码如下:
Mat change_log(const Mat &original) {
cv::Mat response = original.clone();//防止未初始化和维度不同
double temp;
for (int i = 0; i < original.rows; i++) {
for (int j = 0; j < original.cols; j++) {
temp = original.at<double>(i, j);
response.at<double>(i, j) = log(temp);//遍历矩阵进行log变换
}
}
return response;
}
double compute_cost(const Mat &y, const Mat &a) {
double cost = 0.0;
cv::Mat temp1 = cv::Mat::zeros(a.rows, a.cols, CV_64FC1);
cv::Mat temp2 = cv::Mat::zeros(a.rows, a.cols, CV_64FC1);
temp1 = change_log(a);
temp2 = change_log(1 - a);
cv::Mat loss;
loss = y.mul(temp1) + (1 - y).mul(temp2);
cost = (-1.0 / y.cols)*sum(loss)[0];
return cost;
}好了,我们终于可以编写,logistic regression的正向传播和反向传播了。反向传播的公式是求导得出,推导很简单,可以自己试试,这里直接给出。
正向传播:
反向传播:
代码:
double propagate(Mat &w,double &b,const Mat &x,const Mat &y,Mat &a,Mat &dw,double &db) {
cv::Mat z;
z = w.t()*x + b;
sigmoid(z, a);
double cost = compute_cost(y, a);
dw = (1.0 / y.cols)*(x*(a - y).t());
db = (1.0 / y.cols)*sum(a - y)[0];
return cost;
}最后写一个计算准确率的函数。
//计算分类精度
float calculateAccuracyPercent(const Mat &original, const Mat &predicted)
{
return 100 * (float)countNonZero(original == predicted) / predicted.cols;
}四、结果分析
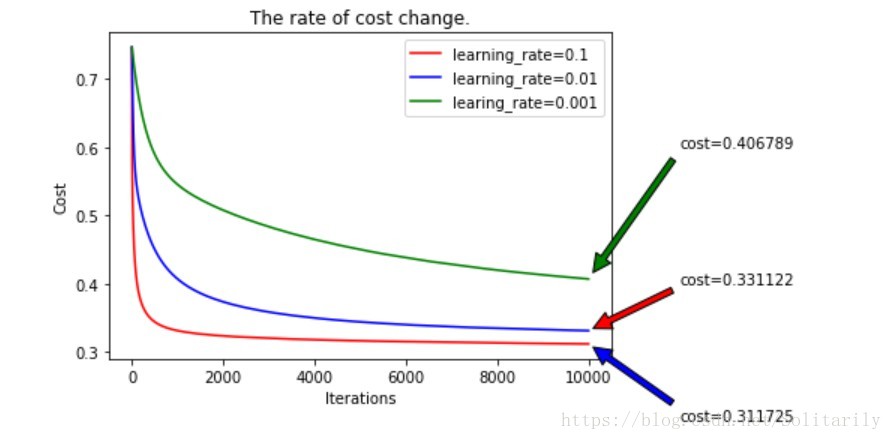
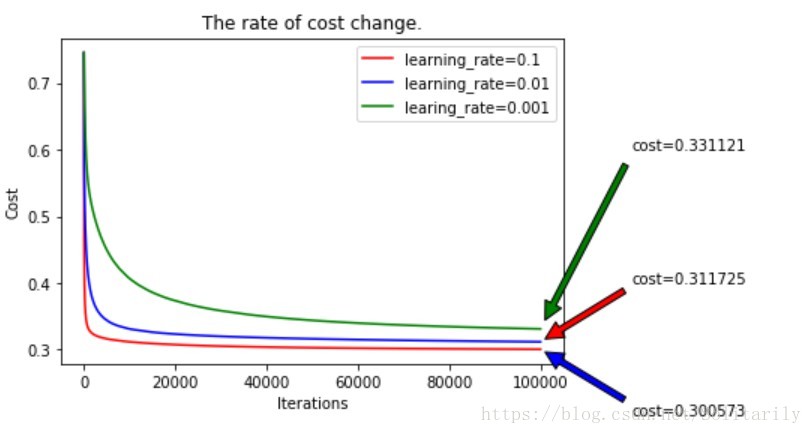
(1)学习率对cost的下降速度的影响
迭代1万次:
迭代10万次:
综上发现学习率在一定的范围内下降最快,且效果最好。
(2)学习率对准确率的影响
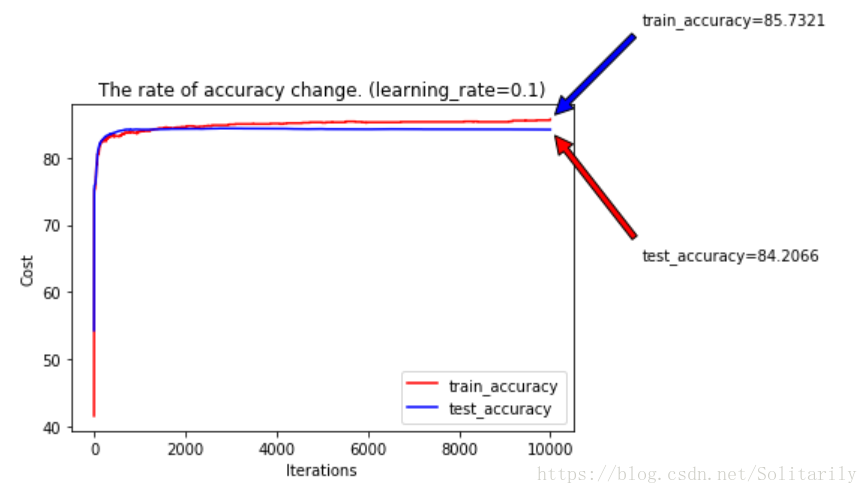
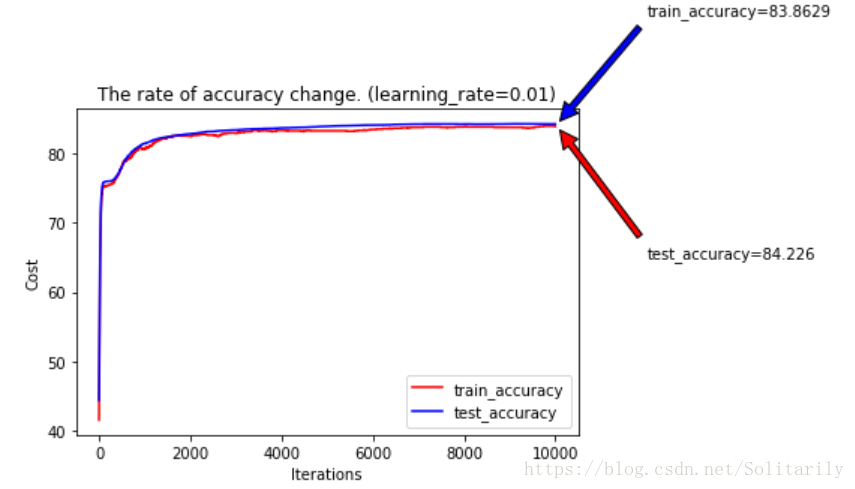
发现更小的学习率在有限的迭代里并不能求得很好的值,所以前期可以大胆使用较大的学习率。
五、结语
实验地址:https://gitee.com/shenchuang1997/logistic-regression.git