完全分布式搭建(1.x版)
一.环境的准备(详情参考Linux章)
- Linux 环境
- JDK
- 准备至少3台机器(通过克隆虚拟机;配置好网络JDK 时间 hosts,保证节点间能互ping通)
- 时间同步 (ntpdate time.nist.gov)
- ssh免秘钥登录 (两两互通免秘钥)
二.完全分布式搭建
-
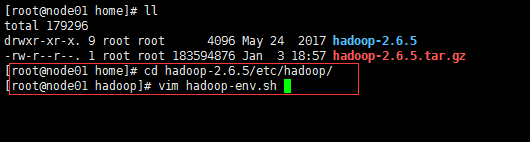
下载解压缩Hadoop


-
配置etc/hadoop/hadoop-env.sh

-
配置core-site.xml:
fs.defaultFS默认的服务端口NameNode URI
hadoop.tmp.dir是hadoop文件系统依赖的基础配置,很多路径都依赖它。
如果hdfs-site.xml中不配 置namenode和datanode的存放位置,默认就放在这个路径中<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://node01:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop-2.6.5</value> </property> </configuration> -
配置 hdfs-site.xml:
dfs.datanode.https.addresshttps服务的端口<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>node02:50090</value> </property> <property> <name>dfs.namenode.secondary.https-address</name> <value>node02:50091</value> </property> </configuration>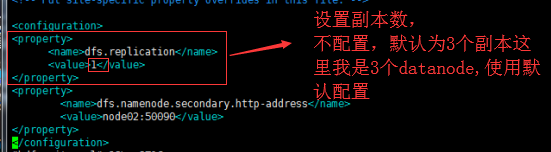
-
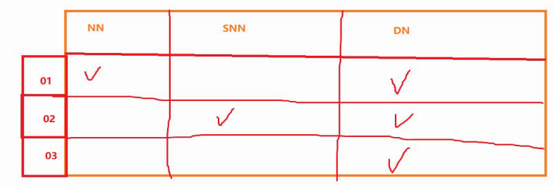
配置 masters: master 可以做主备的SNN
在/home/hadoop-2.6.5/etc/hadoop/新建masters文件 写上SNN节点名: node02


-
配置 slaves: slave 奴隶 苦干;拼命工作
在/home/hadoop-2.5.1/etc/hadoop/slaves文件中填写DN 节点名:node2 node3 node4 [注意:每行写一个 写成3行]

-
最后将配置好的Hadoop通过SCP命令发送都其他节点
配置Hadoop的环境变量


-
vi ~/.bash_profile (最好手敲输入 粘贴有时候会出错)
export HADOOP_HOME=/home/hadoop-2.6.5 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin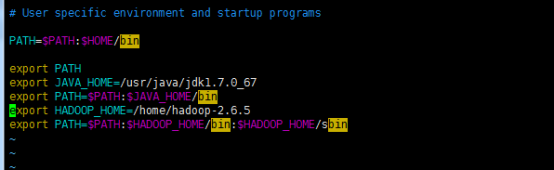


-
记得一定要
source ~/.bash_profile -
回到跟目录下对NN进行格式化 hdfs namenode -format
hdfs namenode -format

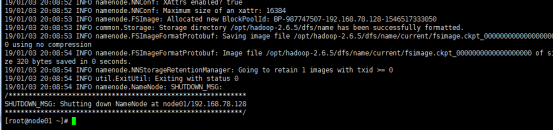
- 关闭防火墙:service iptables stop
- 启动HDFS: start-dfs.sh启动HDFS: start-dfs.sh
启动HDFS: start-dfs.sh

- 验证是否成功
- 在浏览器输入 node1:50070 出现以下界面成功
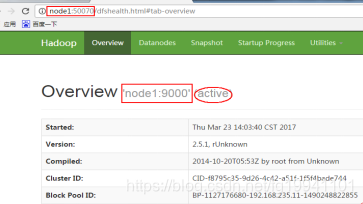
- 到datanode节点验证hadoop.tmp.dir目录
- 注意:HDFS集群有clusterID,datanode启动时会和namenode对比clusterID,如果相同,启动成功,如果不同,自杀进程
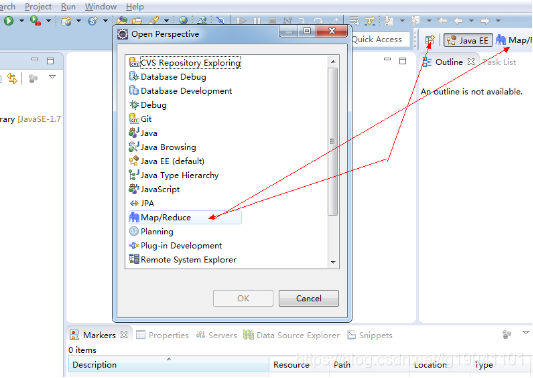
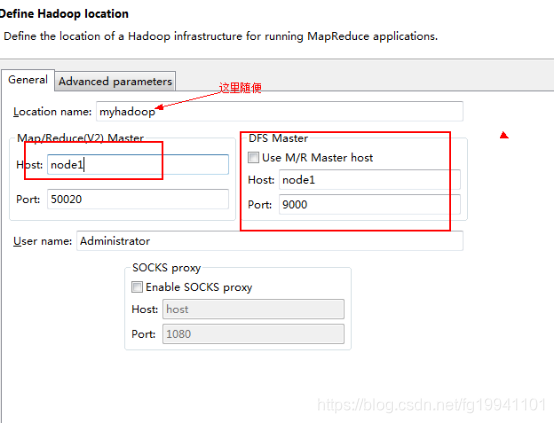
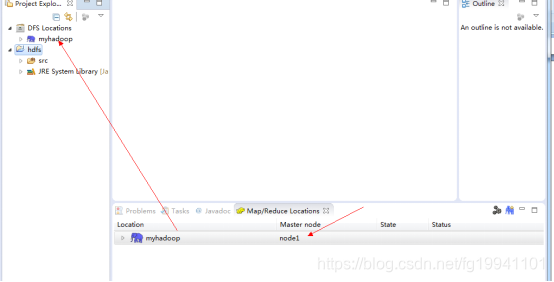
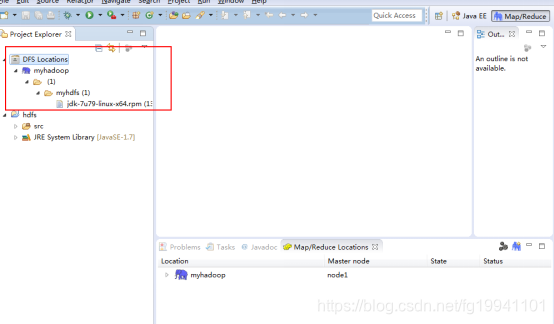
eclipse插件安装配置
将以下jar包放入eclipse的plugins文件夹中
hadoop-eclipse-plugin-2.6.0.jar
启动eclipse:出现界面如下:
新建Java项目:

Eclipse插件安装完后修改windows下的用户名,然后重启:
【注意:改成Windows下用户的用户名root(重启生效)或改Linux文件的用户】
或

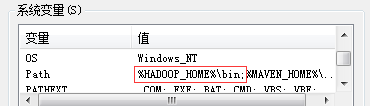
记得配置 path