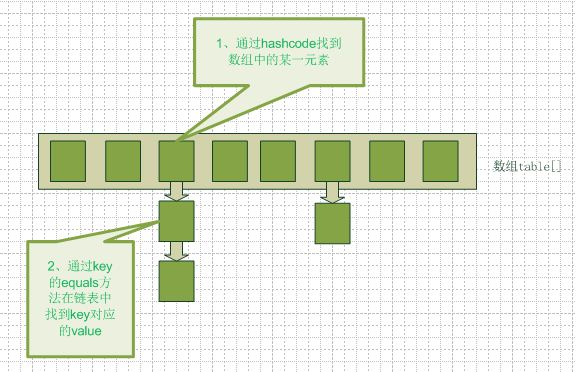
在java编程语言中,最基本的结构就是两种,一个是数组,另外一个是模拟指针(引用),所有的数据结构都可以用这两个基本结构来构造的,hashmap也不例外。 Hashmap 实际上是一个数组和链表的结合体(在数据结构中,一般称之为“链表散列“),请看下图(横排表示数组,纵排表示数组元素【实际上是一个链表】)。
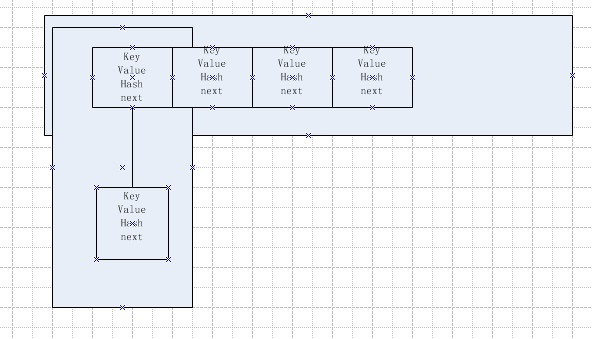
HashMap是一个 Entry 键值对:
static class Entry<K,V> implements Map.Entry<K,V> {
...
}
先看get() 方法:
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
// 首先 根据 key的 hashcode得到hash值(先不纠结算法),再在 table中 找到该hash地址 对应的值; 如果该地址存在多个值,且以链表的形式存在,那么根据for循环,直到取得对应的key的值。
---------------分割线 ---------------
put() 方法:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}
解析: 当我们将 新元素 往 map 中加的时候,首先 根据key值得到 hash值; 如果 在该hash值的位置上 已经有值了,那么将元素以链表的形式存放,且最先放进来的元素 放在链表的最末尾; 如果 在该hash值的位置上没有值,直接 将该位置留给 该 K-V键值对, table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
keySet():
if (keySet == null) {
keySet = new AbstractSet<K>() {
public Iterator<K> iterator() {
return new Iterator<K>() {
private Iterator<Entry<K,V>> i = entrySet().iterator();
public boolean hasNext() {
return i.hasNext();
}
public K next() {
return i.next().getKey();
}
public void remove() {
i.remove();
}
};
}
public int size() {
return AbstractMap.this.size();
}
public boolean contains(Object k) {
return AbstractMap.this.containsKey(k);
}
};
}
return keySet;
}