1:map提供了三种视图形式:key的set,key-value的set,value的Collection,
2:map中有有排序接口,如sortMap的实现类,实现了这个接口的有排序功能,如treeMap,而HashMap则没有。
3:具有破坏性的操作/不支持的操作会抛出UnsupportedOperationException
4:影响hashMap的两个因素是initial Capacity和Load factor;
5:the default load factor (.75)
6:Note that this implementation is not synchronized.这个实现类是不加锁的。
* If no such object exists, the map should be "wrapped" using the
* {@link Collections#synchronizedMap Collections.synchronizedMap}
* method. This is best done at creation time, to prevent accidental
* unsynchronized access to the map:<pre>
* Map m = Collections.synchronizedMap(new HashMap(...));</pre>
*
官方说其中一种加锁方式是上面的代码。打开这个方法会看到传入的是一个final的Map
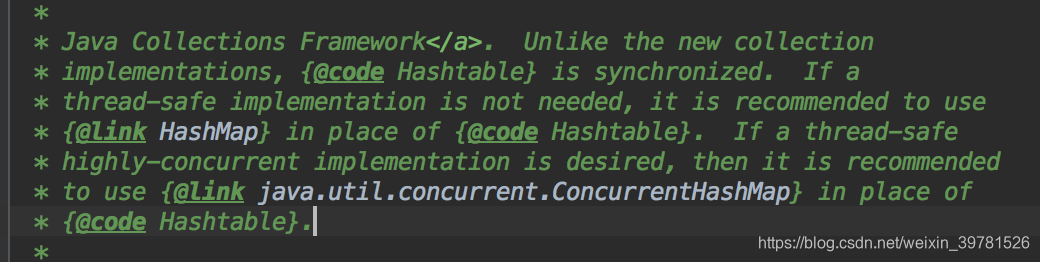
7:hashtable是公有方法上synchronised的,包括JDK1.8中map新增加的几个方法都有重写并加锁,如果你不涉及到线程安全使用HashMap,因为性能高,如果涉及到线程安全,使用concurrentHashMap;
8:hashmap中的hash(key)
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
获取了key的哈希码,进行了高位与低位的异或运算。
而hashtable中的hash(key)是直接获取了hashcode作为哈希码的。
9:动态扩容,当容量达到了load factor时,则进行扩容,这不会修改对象。
扩容是通过左移操作完成的。每当达到阈值时,判断capacity是否是Integer最大值,如果是则返回Oldvalue,如果不是,则左移一位,作为新的capacity。然后重新计算hash值。重新存储。
10:每一个键值对存放在Node<K,V>中,其中有一个hash值就是hash(key)获取的。
11:在HashMap中,当我们putval时会在最后调用afterNodeInsertion方法,而这个方法最典型的就是在LinkedHashmap中的重写,用来删除最早放入Map的对象
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
12:hashtable不接收null的key和null的value,而hashmap接收。
13:hashtable继承Dictionary,而hashMap继承AbstractMap,
14:hashtable的最小单元是一个Entry,而hashmap最小单元是一个Node