项目说明:
Python新手,第一个爬虫项目,网络爬虫算是一项能提升编程学习兴趣的活动了,让Python学习不再枯燥。
Python版本3.7.2
需要模块:requests,os,beautifulsoup
爬虫目标地址https://www.mzitu.com/xinggan/
项目实现:
首先导入模块,配置请求头,如果没有图片地址会是空链接
# -*- coding:utf-8 -*-
import requests,os from bs4 import BeautifulSoup Path = 'D:\\MeiZ\\' header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36', 'Referer': 'https://www.mzitu.com/163367'}
一、获取网页源代码
def getContent(url): ##requests.get返回一个response res = requests.get(url,headers = header) ##BeautifulSoup解释器使用lxml比html5lib要快 soup = BeautifulSoup(res.text,'lxml') return soup
二、获取图集地址
chrome图片右键“检查”,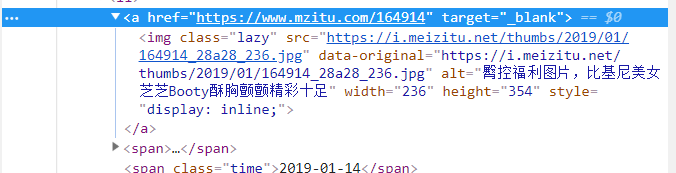
发现以a标签来查找全文太多,所以可以用img标签通过parent来取出父标签
def get_album_list(url): soup = getContent(url) ##找出所有img标签,返回一个list artical = soup.findAll('img',{'class':'lazy'}) ##设置一个空列表,保存图集地址 artical_list = [] for i in artical: ##parent方法取父标签内容 artical_list.append(i.parent['href']) return artical_list
三、获取图集标题和页码
扫描二维码关注公众号,回复:
4916246 查看本文章


进入图集,使用css选择器取出标题和页码,检查标题,类名为main-title

搜索页码,页码为span标签
def getPage_Title(url): soup = getContent(url) ##css选择器返回list ##取出list第一个 title = soup.select('.main-title')[0].text ##页码在list中为第11个 page = soup.select('span')[10].text return page,title
四、获取图片地址
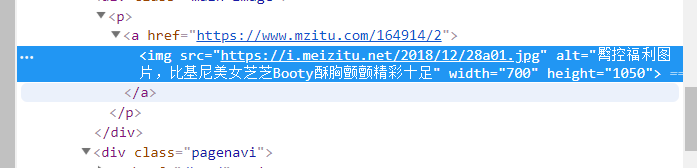
检查图片,图片链接在img标签中的src里
def getImg_url(url): soup = getContent(url) ##根据标签的属性查找 ##find(name, attrs, recursive, text, **wargs) Img_url = soup.find('img')['src'] return Img_url
五、下载图片
def down_Img(url,title,count): res = requests.get(url,headers = header) ##异常处理 try: ##count计数保存 with open(Path + title + '\\' + str(count) +'.jpg','wb') as file: file.write(res.content) ##文件写入后需要关闭,不然一直在内存中 file.close() except: print("ERROR")
六、主函数串联方法
##开始程序检查有无D:\\MeiZ\\目录 if not os.path.isdir(Path): os.mkdir(Path)
图集列表地址为https://www.mzitu.com/xinggan/page/加上页码数,查看总页码为135页
url = 'https://www.mzitu.com/xinggan/page/' ##循环每一页 for t in range(1,135): url = url + str(t)
##获取图集地址 album_list = get_album_list(url) for index in range(0,len(album_list)): ##循环取出标题和页码总数 Page_Title = getPage_Title(album_list[index]) page_num = Page_Title[0] title = Page_Title[1] print("正在下载:" + title)
##以标题创建子目录,存在则跳过下载 if not os.path.isdir(Path + title): os.mkdir(Path + title) for i in range(1,int(page_num)): ##以图集页码总数循环取出每张图片地址 Page_url = album_list[index] + "/" + str(i) Img_Info = getImg_url(Page_url) down_Img(Img_Info,title,i) print("正在下载" + str(i) + "/" + str(page_num)) else: print("已下载跳过")
七、全部代码
# -*- coding:utf-8 -*- #__author__ = 'vic' import requests,os from bs4 import BeautifulSoup Path = 'D:\\MeiZ\\' header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36', 'Referer': 'https://www.mzitu.com/163367'} ##网页html def getContent(url): res = requests.get(url,headers = header) soup = BeautifulSoup(res.text,'lxml') return soup ##获取图集地址 def get_album_list(url): soup = getContent(url) artical = soup.findAll('img',{'class':'lazy'}) artical_list = [] for i in artical: artical_list.append(i.parent['href']) return artical_list ##获取图集页码数 def getPage_Title(url): soup = getContent(url) page = soup.select('span')[10] title = soup.select('.main-title')[0].text return page.text,title ##获取图片地址 def getImg_url(url): soup = getContent(url) Img_url = soup.find('img')['src'] return Img_url ##下载 def down_Img(url,title,count): res = requests.get(url,headers = header) try: with open(Path + title + '\\' + str(count) +'.jpg','wb') as file: file.write(res.content) file.close() except: print("ERROR") if __name__ == '__main__': if not os.path.isdir(Path): os.mkdir(Path) url = 'https://www.mzitu.com/xinggan/page/' for t in range(1,135): url = url + str(t) album_list = get_album_list(url) for index in range(0,len(album_list)): Page_Title = getPage_Title(album_list[index]) page_num = Page_Title[0] title = Page_Title[1] print("正在下载:" + title) if not os.path.isdir(Path + title): os.mkdir(Path + title) for i in range(1,int(page_num)): Page_url = album_list[index] + "/" + str(i) Img_Info = getImg_url(Page_url) down_Img(Img_Info,title,i) print("正在下载" + str(i) + "/" + str(page_num)) else: print(title + "已下载跳过")
八、项目成果
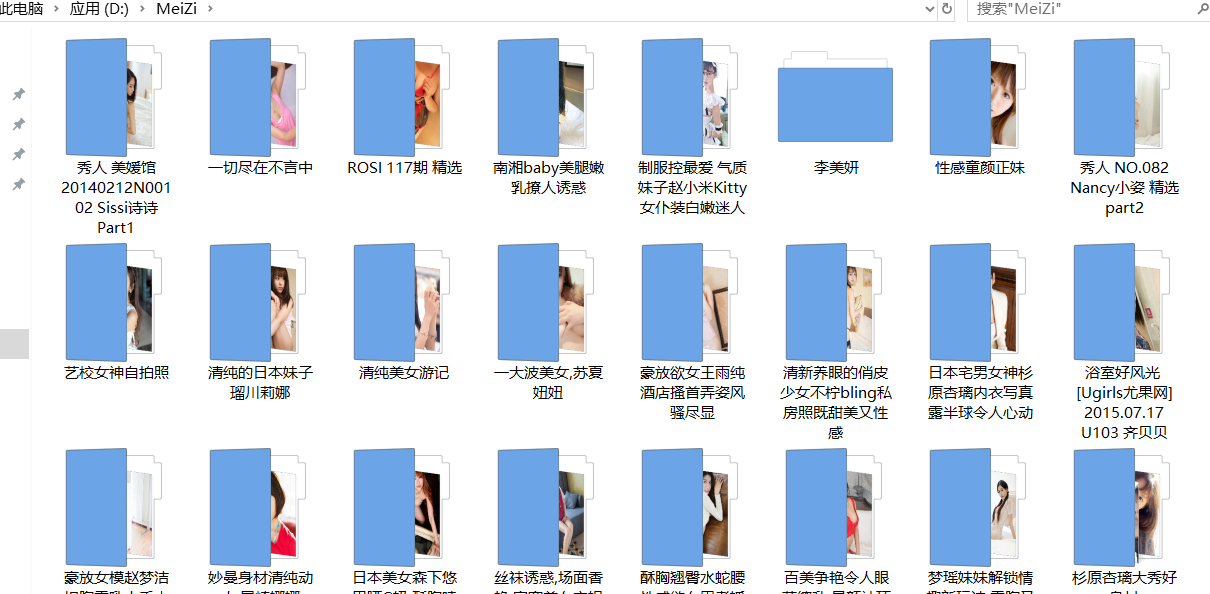
下一项目准备爬小草