[MXNet逐梦之旅]练习六·使用MXNetFashionMNIST数据集RNN分类
使用方式和PyTorch的RNN类似,首先我们看下MXNet的RNN函数原型
mxnet.gluon.rnn.RNN(hidden_size, num_layers=1, activation='relu', layout='TNC', dropout=0, bidirectional=False, i2h_weight_initializer=None, h2h_weight_initializer=None, i2h_bias_initializer='zeros', h2h_bias_initializer='zeros', input_size=0, **kwargs)| Parameters: |
|
|---|
我们需要注意的参数有hidden_size (int),num_layers (int, default 1)与layout (str, default 'TNC')
- hidden_size (int):即为隐层个数,也一般作为分类层输出的数目
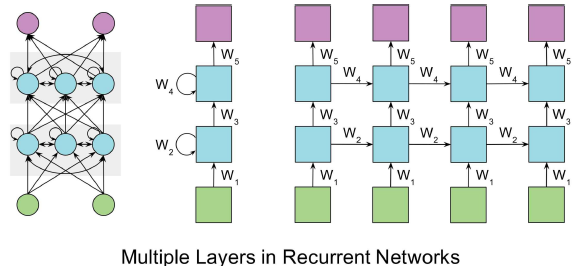
- num_layers (int, default 1):即为RNN的层数,注意不要和sequence length搞混淆,num_layers 大家可以理解为RNN的高度,sequence length为RNN的宽度。如下图所示,我们把绿色当做输入数据,紫色当做输出数据,中间的蓝色作为RNN网络。那么num_layers 为2,sequence length为4。(这时候我们可以发现,并没有让我们设置sequence length的参数,其实MXNet是通过你输入数据的形状来确定sequence length的)
- layout (str, default 'TNC'):先看官方描述**input tensor with shape (sequence_length, batch_size, input_size) when layout is “TNC”. For other layouts, dimensions are permuted accordingly using transpose() operator which adds performance overhead. Consider creating batches in TNC layout during data batching step.**简单解释一下,就是用layout 参数来确定输入与输出的数据组织形式。默认是TNC代表输入为(sequence_length, batch_size, input_size)输出为(sequence_length, batch_size, hidden_size),而我们常用的(batch_size, sequence_length, input_size),所以我们需要在改为NTC。
这也就是我们搭建网络的依据。
class Model(gl.nn.Block):
def __init__(self, **kwargs):
super(Model, self).__init__(**kwargs)
self.rnn = gl.rnn.RNN(128, 2,layout="NTC")
self.out = gl.nn.Dense(10)
def forward(self, x):
f1 = self.rnn(x)[:,-1,:]
#print(f1.shape)
return(self.out(f1))
def init(self):
self.initialize(mx.init.Normal(sigma=0.01), force_reinit=True, ctx=ctx)
self.loss = gl.loss.SoftmaxCrossEntropyLoss()
self.opt = gl.Trainer(self.collect_params(),"adam",{"learning_rate":0.01})
return(self.loss,self.opt)- 完整代码(我们把数据设置成(-1,14,56),分别对应(batch_size, sequence_length, input_size))
from mxnet import gluon as gl
import mxnet as mx
import numpy as np
import sys
from tqdm import tqdm
mnist_train = gl.data.vision.FashionMNIST(root="L3/fashion-mnist/",train=True)
mnist_test = gl.data.vision.FashionMNIST(root="L3/fashion-mnist/",train=False)
batch_size = 100
transformer = gl.data.vision.transforms.ToTensor()
if sys.platform.startswith('win'):
num_workers = 0 # 0表示不用额外的进程来加速读取数据
else:
num_workers = 4
train_iter = gl.data.DataLoader(mnist_train.transform_first(transformer),
batch_size, shuffle=True,
num_workers=num_workers)
test_iter = gl.data.DataLoader(mnist_test.transform_first(transformer),
1000, shuffle=False,
num_workers=num_workers)
def try_gpu():
try:
ctx = mx.gpu()
_ = mx.nd.zeros((1,), ctx=ctx)
except mx.base.MXNetError:
ctx = mx.cpu()
return ctx
ctx = mx.cpu()
def accuracy(y_hat, y):
return (y_hat.argmax(axis=1) == y.astype('float32')).mean().asscalar()
class Model(gl.nn.Block):
def __init__(self, **kwargs):
super(Model, self).__init__(**kwargs)
self.rnn = gl.rnn.RNN(128, 2,layout="NTC")
self.out = gl.nn.Dense(10)
def forward(self, x):
f1 = self.rnn(x)[:,-1,:]
#print(f1.shape)
return(self.out(f1))
def init(self):
self.initialize(mx.init.Normal(sigma=0.01), force_reinit=True, ctx=ctx)
self.loss = gl.loss.SoftmaxCrossEntropyLoss()
self.opt = gl.Trainer(self.collect_params(),"adam",{"learning_rate":0.01})
return(self.loss,self.opt)
model = Model()
loss, opt = model.init()
num = 5
for e in range(1,num+1):
losses = []
for x,y in (train_iter):
x=x.reshape((-1,14,56))
with mx.autograd.record():
l = loss(model(x),y)
losses.append(l.asnumpy())
l.backward()
opt.step(batch_size)
loss_val = np.mean(losses)
for Xt, yt in test_iter:
Xt = Xt.reshape((-1,14,56))
accy = accuracy(model(Xt),yt)
break
print('epoch %d, loss: %f, acc: %f' % (e,loss_val,accy))
print(model)
print(model.collect_params())- 输出结果
(MX_GPU) C:\Files\DATAs\prjs\python\mxnet\dl021>C:/Files/APPs/RuanJian/Miniconda3/envs/MX_GPU/python.exe c:/Files/DATAs/prjs/python/mxnet/dl021/L3/l031.py
epoch 1, loss: 1.012638, acc: 0.754000
epoch 2, loss: 0.597370, acc: 0.808000
epoch 3, loss: 0.509288, acc: 0.820000
epoch 4, loss: 0.489378, acc: 0.827000
epoch 5, loss: 0.466955, acc: 0.850000
Model(
(rnn): RNN(56 -> 128, NTC, num_layers=2)
(out): Dense(128 -> 10, linear)
(loss): SoftmaxCrossEntropyLoss(batch_axis=0, w=None)
)
model0_ (
Parameter rnn0_l0_i2h_weight (shape=(128, 56), dtype=<class 'numpy.float32'>)
Parameter rnn0_l0_h2h_weight (shape=(128, 128), dtype=<class 'numpy.float32'>)
Parameter rnn0_l0_i2h_bias (shape=(128,), dtype=<class 'numpy.float32'>)
Parameter rnn0_l0_h2h_bias (shape=(128,), dtype=<class 'numpy.float32'>)
Parameter rnn0_l1_i2h_weight (shape=(128, 128), dtype=<class 'numpy.float32'>)
Parameter rnn0_l1_h2h_weight (shape=(128, 128), dtype=<class 'numpy.float32'>)
Parameter rnn0_l1_i2h_bias (shape=(128,), dtype=<class 'numpy.float32'>)
Parameter rnn0_l1_h2h_bias (shape=(128,), dtype=<class 'numpy.float32'>)
Parameter dense0_weight (shape=(10, 128), dtype=float32)
Parameter dense0_bias (shape=(10,), dtype=float32)
)