前言
本文对各类排序算法的实现、优化、复杂度、稳定性、适用场景作以全面总结,为了突出算法的简洁、易懂,去除了一些冗余操作,默认为升序进行模拟。
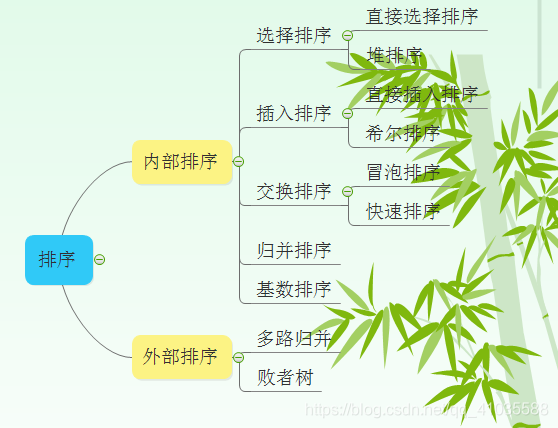
一、插入排序
插入排序基本思想:每一步将一个待排序的元素,按其排序码的大小,插入到前面已经排好序的一组元素的合适位置上去,直到元素插完。
☞ 直接插入排序
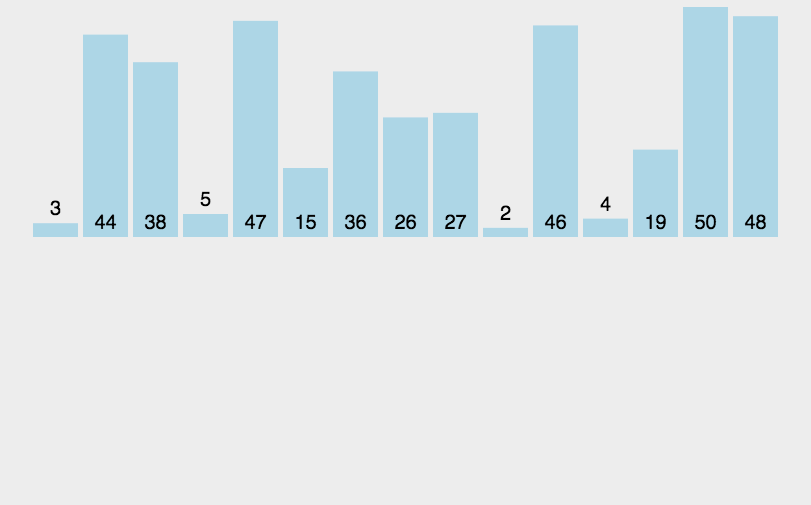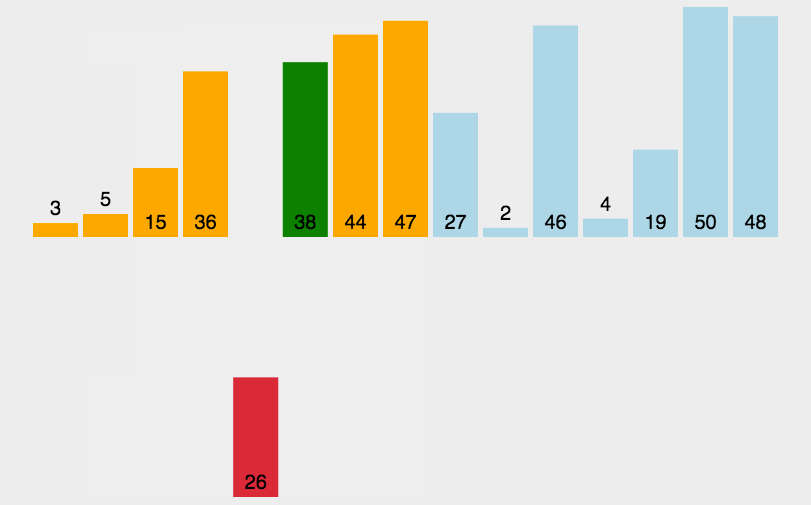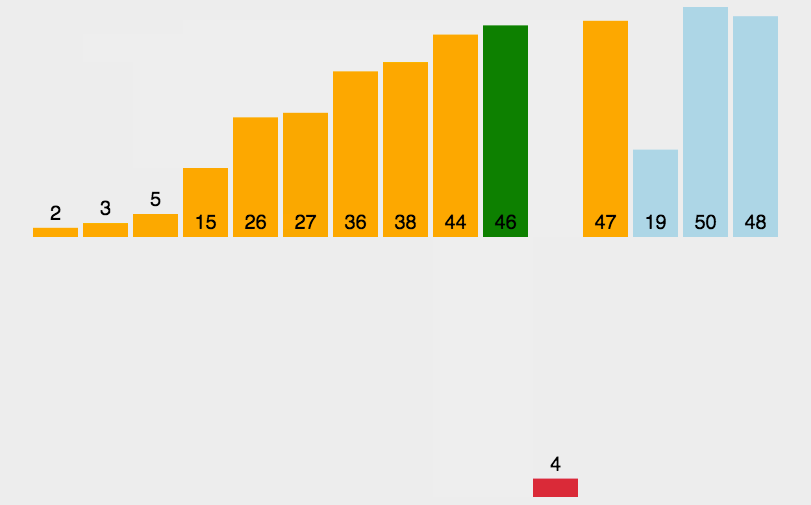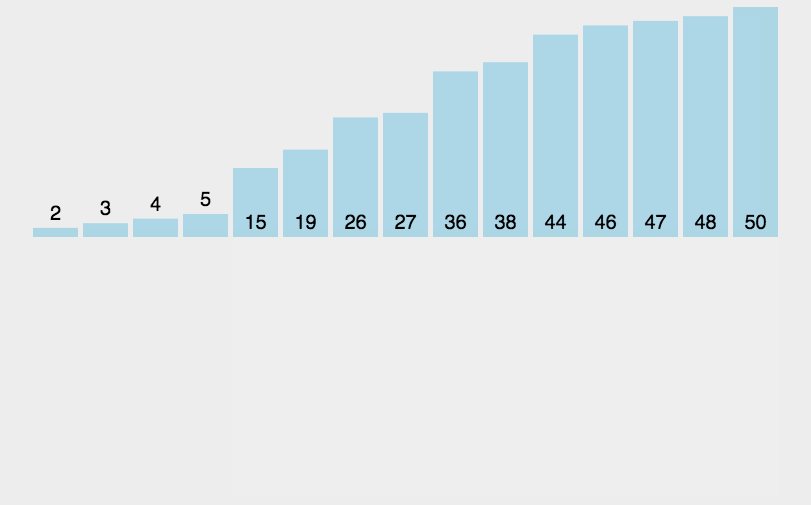
基本思想:当我们插入第i(i>=1)个元素时,前面的所有元素已经排好序,此时我们使用当前元素从后向前比较,直到找到一个小于array[i]的节点(若没有,则插在数组下标为0的地方),从下一个节点顺序后移,将array[i]插入进来。
时间复杂度: O(n^2)
空间复杂度: O(1)
稳定性:稳定
适用场景:1.数据量较小 2.基本接近有序
//直接插入排序
int InsertSort(int *num,int len)
{
assert(num);
int i = 0;
//第一个元素已经为有序序列,所以要进行len-1次排序
for (; i < len - 1; i++)
{
int end = i;
int tmp = num[i + 1];//保存非有序区间第一个元素,否则在后边的移动中会改变
//比较后移
while (end >= 0 && num[end]>tmp)
{
num[end+1] = num[end];
--end;
}
//插入到适当位置
num[end + 1] = tmp;
}
}
☞ 二分插入排序(优化)
基本思想:在直接插入排序的基础上进行优化,因为待插入元素之前的元素已经有序,我们没必要每个都遍历,借助而二分法的思想可以有效降低查找的时间。
void BinaryInsertSort(int *arr, int size)
{
if (arr == NULL || size <= 0)
return ;
int index = 0;
for (int idx = 1; idx < size; ++idx)
{
int tmp = arr[idx];//保存待插入元素
int left = 0;
int right = idx - 1;
int mid = (left&right) + ((left^right) >> 1);
//二分法查找插入位置
while (left <= right)
{
if (tmp < arr[mid])
{
right = mid - 1;
index = mid;//更新插入位置
}
else if (tmp >= arr[mid])
{
left = mid + 1;
index = mid + 1;//更新插入位置
}
mid = (left&right) + ((left^right) >> 1);//缩小空间
}
//后移元素
for (int j = idx; j > index; j--)
{
arr[j] = arr[j - 1];
}
//插入新元素
arr[index] = tmp;
}
}
☞ 希尔排序
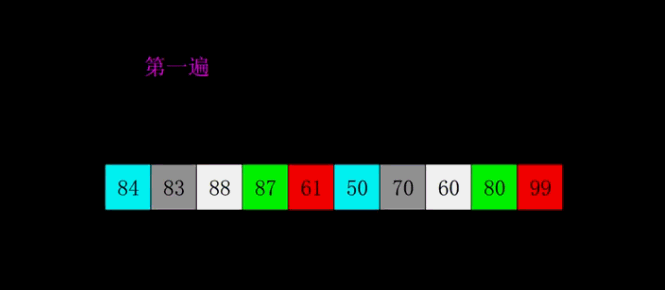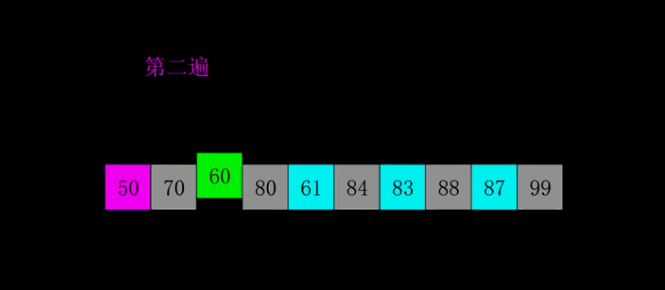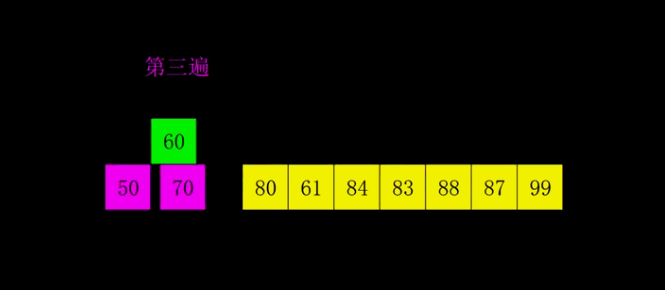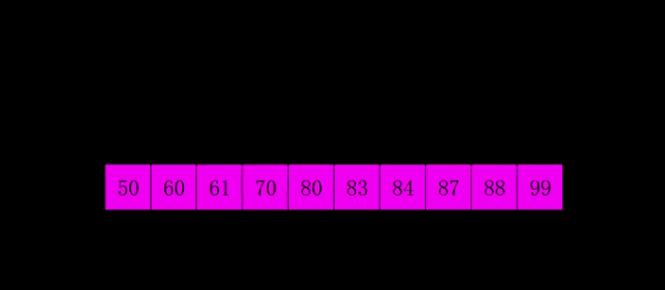
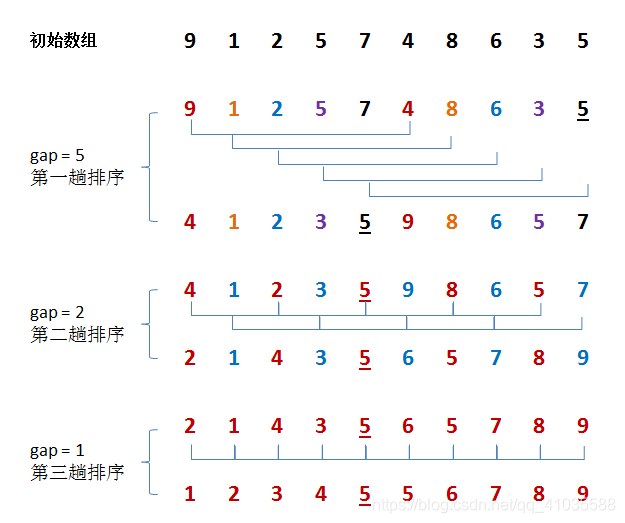
基本思想:希尔排序是插入排序的一个变种。不同之处在于我们按步长gap分组,对每组的记录采用直接插入排序,随着步长的逐渐减少,分组包含的记录越来越多,直到gap=1时,构成了一个有序记录。
时间复杂度: O(n^1.25) ~ 1.6*O(n^1.25)
空间复杂度: O(1)
稳定性:不稳定
适用场景:数据量较大,有序
下图中为了方便,对gap以gap/2来计算,但最优的算法是gap/3+1。
void ShellSort(int* arr, int size)
{
if (arr == NULL || size <= 0)
return;
int gap = size;//gap为增量
while (gap > 1)
{
gap = gap / 3 + 1;//这样给是最优的
for (int idx = gap; idx < size; ++idx)
{
int end = idx - gap;//分组后,当前元素的前一个元素
int key = arr[idx];//保存当前元素
//按升序排序
while (end >= 0 && arr[end] > key)
{
arr[end + gap] = arr[end];
end -= gap;
}
arr[end + gap] = key;
}
}
}
二、选择排序
基本思想:每一趟(例如第i趟,i=0,1,…,n-2)在后面n-i个待排序的数据元素集合中选出关键码最小的数据元素,作为有序元素序列的第i个元素,待到第n-2趟做完,待排序元素集合中只剩 下1个元素,排序结束。
时间复杂度: O(n^2)
空间复杂度: O(1)
稳定性:不稳定
适用场景:数据量较小,交换次数比较少
☞ 选择排序(单边缩小空间)
基本思想:我们定义一个maxIndex来标记区间内最大值的下标,第一次遍历完数组后,更新maxIndex的指向,与下标为end(最后一个元素)的元素交换,end–缩小空间,继续遍历更新maxIndex。
void SelectSort(int* arr, int size)
{
if (arr == NULL || size <= 0)
return;
for (int end = size - 1; end > 0; --end)
{
int maxIndex = end;//最大下标
for (int idx = 0; idx < end; ++idx)
{
//比最大的元素还大,更新最大下标
if (arr[idx] > arr[maxIndex])
maxIndex = idx;
}
//交换end与最大元素的值
std::swap(arr[maxIndex], arr[end]);
}
}
☞ 选择排序(双边缩小空间1.0)
基本思想:每一趟遍历我们需要找出最大元素的下标与最小元素的下标,然后用处于最小下标的元素与begin(首元素下标)交换,用最大下标的元素与end(尾元素下标),最后begin++,end–同时缩短区间,直到begin与end相等。
注意:如果begin与maxIndex相同,begin与minPos交换之后,maxPos也应该指向minPos。
void SelectSort(int* arr, int size)
{
if (arr == NULL || size <= 0)
return;
int begin = 0;
int end = size - 1;
while (begin < end)
{
int maxPos = begin;//最大元素下标
int minPos = begin;//最小元素下标
for (int idx = begin + 1; idx <= end; ++idx)
{
//比最大的元素还大,更新最大下标
if (arr[idx] > arr[maxPos])
maxPos = idx;
//比最小的元素还小,更新最大下标
if (arr[idx] < arr[minPos])
minPos = idx;
}
//交换begin与最小元素的值
std::swap(arr[begin], arr[minPos]);
//如果最大元素下标与begin相同,上面begin与minPos已经交换,因此maxPos也应该指向minPos
if (maxPos == begin)
maxPos = minPos;
//交换end与最大元素的值
std::swap(arr[end], arr[maxPos]);
//缩小区间
++begin;
--end;
}
}
☞ 选择排序(双边缩小空间2.0)
基本思想:1.0版本中,我们需要考虑最大下标与begin的重合问题,为了避免这样的问题出现,我们将不再使用maxPos和minPos,而改用直接交换数据,然后缩小空间,直到左右空间重合。
void SelectSort(int* arr, int size)
{
if (arr == NULL || size <= 0)
return;
int left = 0;
int right = size - 1;
while (left < right)
{
for (int idx = left; idx <= right; ++idx)
{
//比left小的交换
if (arr[idx] < arr[left])
std::swap(arr[idx], arr[left]);
//比right大的交换
if (arr[idx] > arr[right])
std::swap(arr[idx], arr[right]);
}
//缩小左右区间
++left;
--right;
}
}
☞ 堆排序

基本思想:堆排序本质上是一种树形选择排序。它也是对直接选择排序的一种优化,堆结构在物理存储上也是一种数组,但是它在逻辑上是一棵完全二叉树,在进行堆排序(升序)时,我们可以先建一个大堆,最大的元素在堆顶上,我们可以以O(1)的时间找到最大的元素,然后和最后一个元素交换。此时,这个堆的左右子树仍然是一个堆,我们只要把[n-1]个数向下调整一次重新建个大堆即可,直到堆中剩下一个元素,既排序完成。
排升序–>建大堆 && 排降序–>建小堆
我们从最后一个非叶子结点建堆,步骤如下:
⑴ 将堆顶元素与当前最大堆的最后一个节点交换
⑵ 最大堆节点-1,即调整剩下的n-1个节点
⑶ 从堆顶继续向下调整,试之满足最大堆,循环⑴ ⑵ ,直至剩下一个节点。
时间复杂度: 0(NlogN)
稳定性:不稳定
适用场景:topK问题等
void AdjustDown(int *arr, int root, int size)//建大堆
{
int parent = root;
int child = parent * 2 + 1;
while (child < size)
{
//保证child指向较大节点
if (child + 1 < size && arr[child + 1] > arr[child])
child += 1;
if (arr[child] > arr[parent])
{
std::swap(arr[child], arr[parent]);
parent = child;//下滤
child = parent * 2 + 1;
}
else
break;
}
}
//堆排序递归
void HeapSort(int *arr, int size)
{
assert(arr && size > 1);
//从最后一个非叶子节点建堆
for (int idx = (size - 2) / 2; idx >= 0; --idx)
{
AdjustDown(arr, idx, size);//下滤调整
}
int end = size - 1;
while (end > 0)
{
//堆顶与最后一个节点交换,升序
std::swap(arr[0], arr[end]);
AdjustDown(arr, 0, end);//下滤调整
--end;
}
}
四、交换排序
☞ 冒泡排序
基本思想:一次确定一个最大值或者最小值,两两比较,将最大值或者最小交换到最右边或者最左边,N个元素需要N-1趟排序。
代码实现:
//冒泡排序
void BubbleSort(int* num, int len)
{
int flag = 0;
if (num == NULL || len <= 0)
return;
//确定循环躺数
for (int i = 0; i < len - 1; i++)
{
//确定比较次数
for (int j = 0; j < len - 1 - i; j++)
{
if (num[j]>num[j + 1])
{
Swap(&num[j], &num[j + 1]);
}
flag=1;
}
if(0 == flag)
break;
}
}
☞ 快速排序
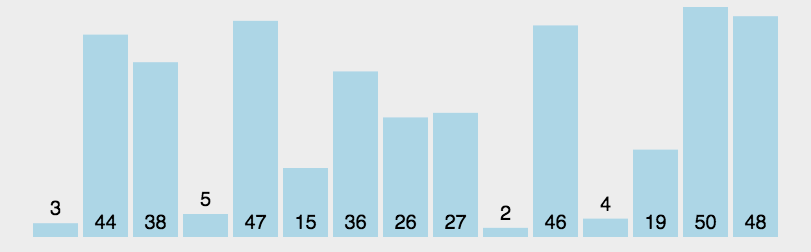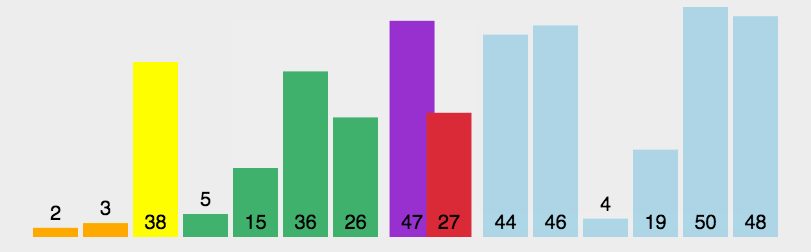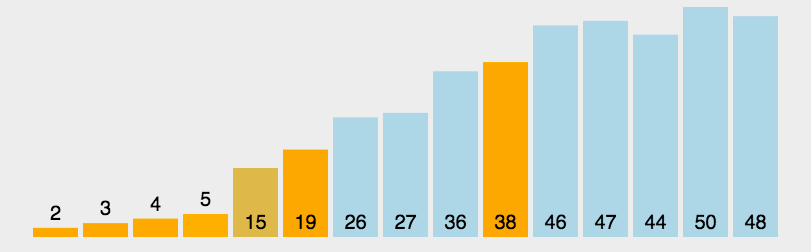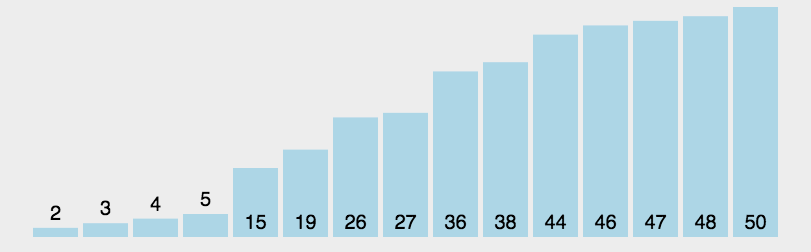
基本思想:在待排序序列中任意取一个元素作为基准元素,按照该基准元素将待排序序列分为两个子序列,左边子序列的值都小于基准值,右边子序列的值都大于基准值。然后把左右子序列当做一个子问题,以同样的方法处理左右子序列,直到所有的元素都排列在相对应的位置上为止。快排是一个递归问题,它是按照二叉递归树的前序路线去划分的。
关于快速排序,我详细将快排的细节总结于我的另一篇博客:快排总结
参考博客:快排总结
五、归并排序
☞ 归并排序
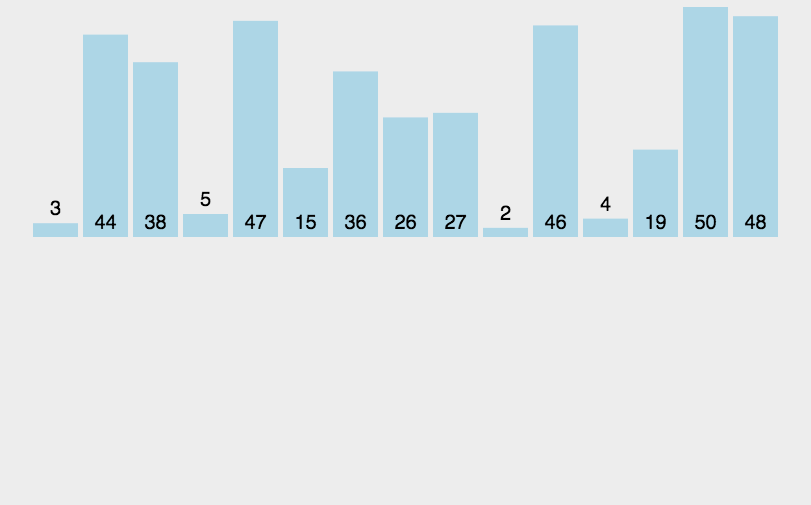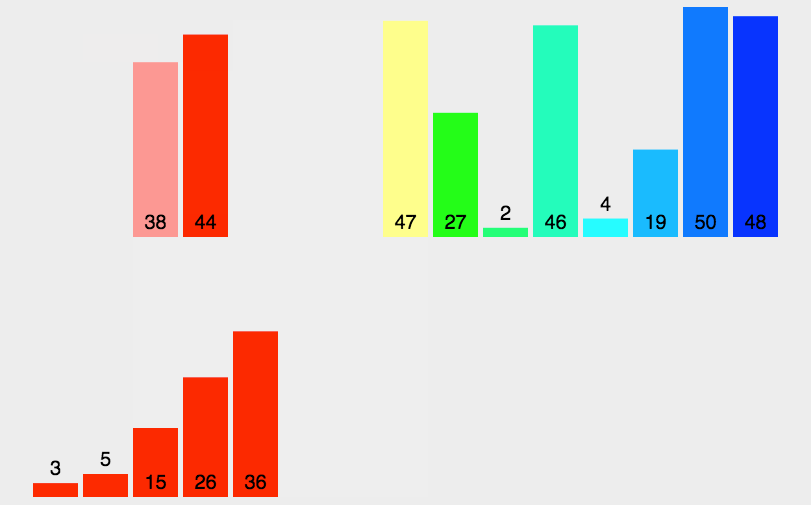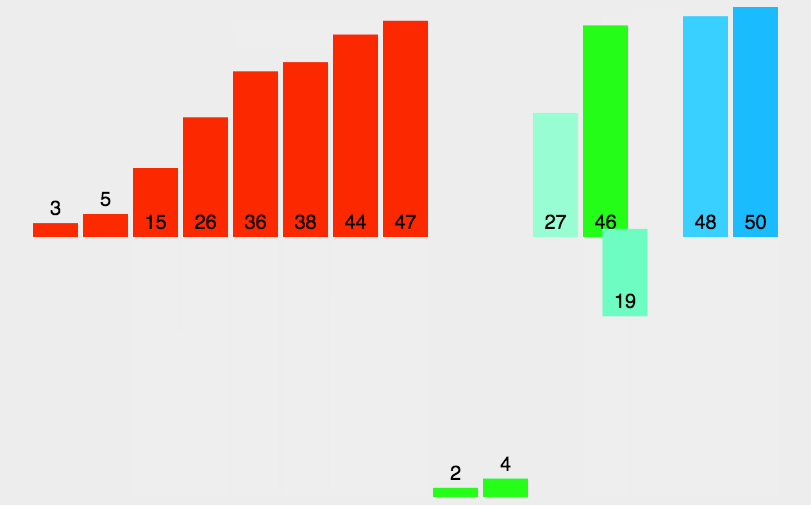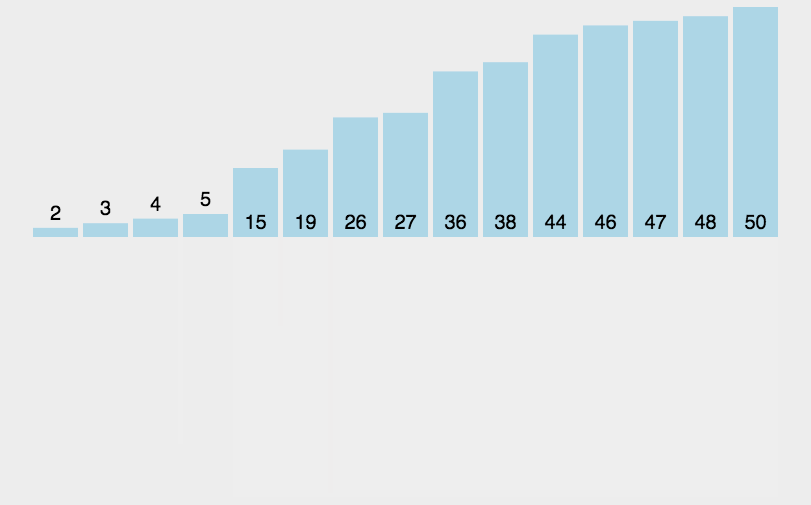
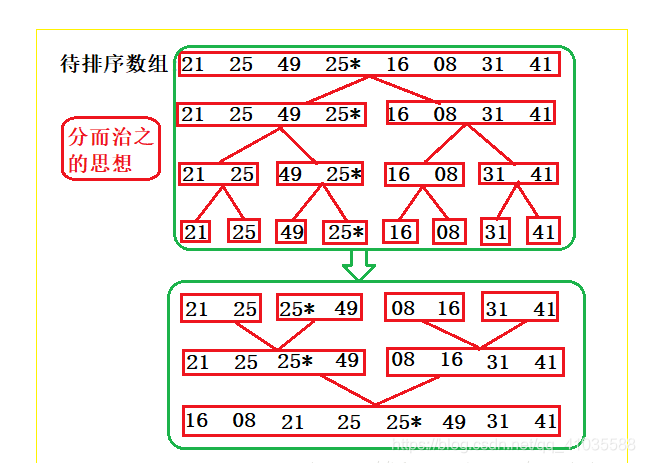
基本思想:归并排序是一个外排序,它可以对磁盘的文件进行排序。它将待排序的元素序列分成两个长度相等的子序列,对每一个子序列排序,然后在将他们合并为一个序列。合并两个子序列的过程称为二路归并。归并排序主要分为两步分组和归并。
void MergeSort(int* num, int len)
{
if (num == NULL || len <= 0)
return;
//开辟临时空间,用来存放每次合并后的子序列
int* tmp = (int*)malloc(sizeof(int)*len);
_MergeSort(num, 0, len - 1, tmp);
//释放空间
free(tmp);
tmp = NULL;
}
//归并排序分开过程(递归树按照前序路线展开)
void _MergeSort(int* num, int begin, int end,int* tmp)
{
assert(num&&tmp);
int mid = begin + (end - begin) / 2;
//只有一个元素,说明这个序列已经有序
if (begin == end)
return;
//子问题划分左子序列
_MergeSort(num, begin, mid, tmp);
//子问题划分右子序列
_MergeSort(num, mid + 1, end, tmp);
//合并两个有序数组
Merge(num, begin, mid, mid + 1, end, tmp);
}
//归并排序合并过程
void Merge(int* num, int start1, int end1, int start2, int end2, int* tmp)
{
assert(num&&tmp);
int begin = start1;
int index = start1;//从start1的地方合并
//和两条有序单链表的合并的过程类似
while ((start1 <= end1) && (start2 <= end2))
{
if (num[start1] < num[start2])
{
tmp[index++] = num[start1++];
}
else
{
tmp[index++] = num[start2++];
}
}
//把剩余的合并到tmp上
while (start1 <= end1)
tmp[index++] = num[start1++];
while (start2 <= end2)
tmp[index++] = num[start2++];
//tmp是个临时空间,最后到把合并的内容拷贝到num上
memcpy(num + begin, tmp + begin, sizeof(int)*(end2 - begin + 1));
}
参考博客 归并递归与非递归
六、计数排序
☞ 计数排序
计数排序又称为鸽巢原理,它是对哈希直接定址法的变形应用。计数排序是一种非比较的排序算法,其核心在于将输入的数据值转化为键存储在额外开辟的数组空间中。这说明计数排序只适合用于比较数据较为集中的数据,如果数据太过分散是非常浪费空间的。
实现步骤
- 统计所有相同数据出现的次数
- 根据统计的次数将序列放回到原来的数组返回
效率分析
计数排序是一个稳定的排序算法。当输入的元素是 n 个 0到 k 之间的整数时,时间复杂度是O(n+k)。
空间复杂度也是(n+k),其排序速度快于任何比较排序算法。当k不是很大并且序列比较集中时,计数排序是一个很有效的排序算法
void CountSort(int* num,int len)
{
if(num==NULL||len<=0)
return;
int min=num[0],max=num[0];
int i=0;
for(;i<len;i++)
{
if(num[i]<min)
min=num[i];
if(num[i]>max)
max=num[i];
}
int range=max-min+1;
int* tmp=(int*)malloc(sizeof(int)*range);
if(tmp==NULL)
{
perror("use malloc");
exit(1);
}
memset(tmp,0,sizeof(int)*range);
for(i=0;i<len;i++)
{
tmp[num[i]-min]++;
}
int index=0;
for(i=0;i<range;i++)
{
while((tmp[i]--)!=0)
{
num[index]=i+min;
index++;
}
}
}
七、总结
术语说明
稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面;
不稳定:如果a原本在b的前面,而a=b,排序之后a可能会出现在b的后面;
内排序:所有排序操作都在内存中完成;
外排序:由于数据太大,因此把数据放在磁盘中,而排序通过磁盘和内存的数据传输才能进行;
时间复杂度: 一个算法执行所耗费的时间。
空间复杂度:运行完一个程序所需内存的大小。
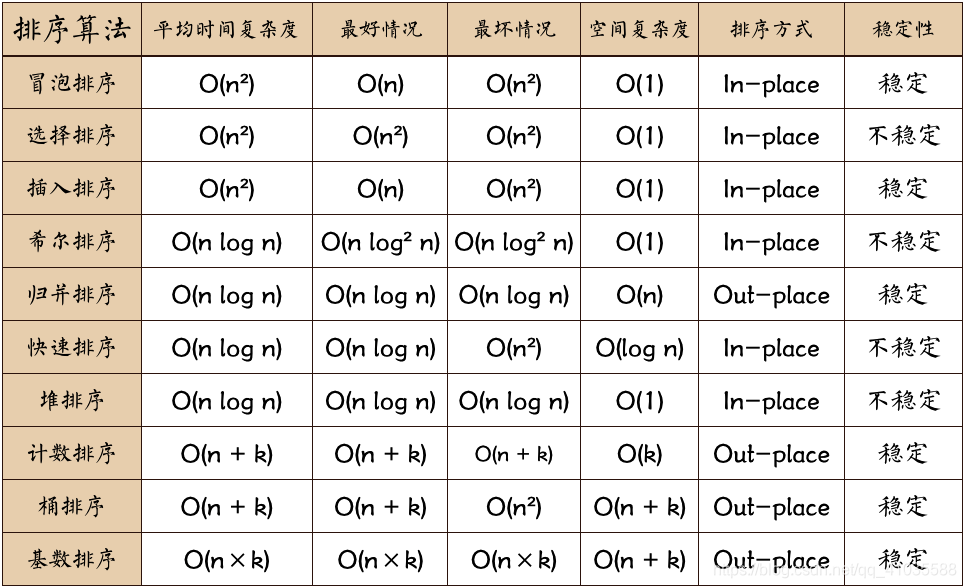 图片名词解释:
图片名词解释:
n: 数据规模
k: “桶”的个数
In-place: 占用常数内存,不占用额外内存
Out-place: 占用额外内存
八、附加
参考博客:
GIF演示排序算法
史上最容易理解的《十大经典算法(动态图展示)》
几种排序方法动态图显示
八大排序,各显神通–动图版