Fast R-CNN算法及其具体训练步骤
Fast R-CNN算法是R-CNN算法的进一步衍生算法,它通过引入ROI pooling层,避免了R-CNN算法对同一区域多次提取特征的情况从而提高了算法的运行速度,总体流程上虽然仍然无法实现端到端的训练,但是也在R-CNN算法的基础上有了很大的改进。
Fast R-CNN算法在训练时依然无法做到端到端的训练,故训练时依旧需要一些繁琐的步骤,网上很少有详细介绍的,作为初学者一开始很难理解具体应该怎么做。还有对于多目标图片数据集例如VOC数据集,该如何处理不同训练图片不同目标个数的情况,本文稍作介绍。
算法流程:
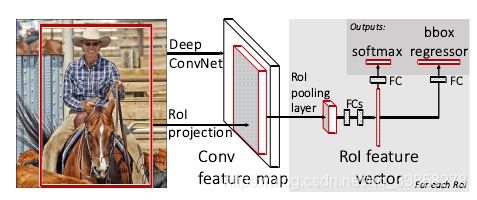
Fast R-CNN算法示意图如下图1所示,检测步骤如下:
- 输入图像;
- 通过深度网络中的卷积层(VGG、Alexnet、Resnet等中的卷积层)对图像进行特征提取,得到图片的特征图;
- 通过选择性搜索算法得到图像的感兴趣区域(通常取2000个);
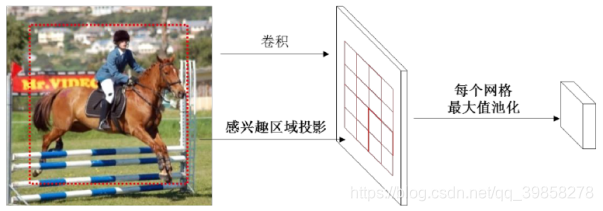
- 对得到的感兴趣区域进行ROI pooling(感兴趣区域池化):即通过坐标投影的方法,在特征图上得到输入图像中的感兴趣区域对应的特征区域,并对该区域进行最大值池化,这样就得到了感兴趣区域的特征,并且统一了特征大小,如图2所示;
- 对ROI pooling层的输出(及感兴趣区域对应的特征图最大值池化后的特征)作为每个感兴趣区域的特征向量;
- 将感兴趣区域的特征向量与全连接层相连,并定义了多任务损失函数,分别与softmax分类器和boxbounding回归器相连,分别得到当前感兴趣区域的类别及坐标包围框;
- 对所有得到的包围框进行非极大值抑制(NMS),得到最终的检测结果。
具体训练步骤:
Fast R-CNN算法在训练时依然无法做到端到端的训练,故训练时依旧需要一些繁琐的步骤,网上很少有详细介绍的,作为初学者一开始很难理解具体应该怎么做。还有对于多目标图片数据集例如VOC数据集,该如何处理不同训练图片不同目标个数的情况。
训练数据处理步骤如下:
- 对于每张训练图片进行选择性搜索算法提取感兴趣区域;
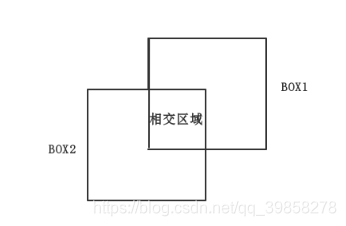
- 将这些感兴趣区域与训练图片的ground truth进行IoU计算(计算公式如下所示,示意图如图3所示),大于0.5(或其他阈值)的作为正样本,小于阈值的设为负样本:
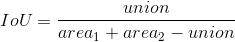
- 对所有正样本根据IOU值进行排序,每张图片取前64个区域,将这些区域的坐标保存下来,作为该图片的训练样本;
- 对于多目标图片的处理方法,我们将感兴趣区域与每一个ground truth进行IOU计算,取最高的记为其IOU值;
- 经过上方步骤,我们每个图片得到了64个区域坐标,即固定了每张图片感兴趣区域的数量,即可用于后续训练中。
- 针对我使用的TensorFlow框架,我们的网络训练数据输入即为:
图片:[batch_size, img_h, img_w, 3]
感兴趣区域坐标:[batch_size, 64, 5](5表示4个坐标以及1个类别标签)
- 原文中采用batch_size=2进行训练,即每次输入2张图片以及128个感兴趣区域坐标,最终网络输出为大小为[128, classes]的softmax向量,以及大小为[128, 4*classes]的坐标向量。对softmax向量与128个区域的独热码类标进行交叉熵的计算得到分类损失,128个区域的坐标复制classes次后与输出的坐标进行smoothL1loss计算得到回归损失,到此网络训练步骤就告一段落。

扫描二维码关注公众号,回复:
5004914 查看本文章
