版权声明:转载请注明来源及作者,谢谢! https://blog.csdn.net/qq_42442369/article/details/86577805
权重更新
因此,在随机梯度下降中,我们就可以这样进行权重的调整:
而对于批量梯度下降,只需将样本数量相加即可:
经过不断反复迭代,最终求得合适的w值,使得损失函数的值最小。
使用逻辑回归算法实现二分类
import numpy as np
# 用来生成分类的数据集。
from sklearn.datasets import make_classification
# sklearn中提供的逻辑回归类,可以用来实现分类任务。
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rcParams["font.family"] = "SimHei"
mpl.rcParams["axes.unicode_minus"] = False
# n_samples 生成样本的数量
# n_features 特征的数量
# n_informative 含有有用信息的特征
# n_redundant 含有冗余信息的特征。
# n_classes 分类的数量。
# random_state 随机种子。
# 返回X,y :生成的样本与对应的标签(所属的类别)
X, y = make_classification(n_samples=200, n_features=2, n_informative=2, n_redundant=0,
n_classes=2, random_state=0)
# 查看生成的数据。
# print(X[:5])
# print(y[:5])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=0)
# 创建逻辑回归类的对象。
# penalty 惩罚项。
# C 正则化强度,是alpha的倒数。
# C越小,惩罚力度越大,C越大,惩罚力度越小。
lr = LogisticRegression(penalty="l2", C=2)
lr.fit(X_train, y_train)
y_hat = lr.predict(X_test)
print(f"权重:{lr.coef_}")
print(f"偏置:{lr.intercept_}")
print(f"预测值:{y_test[:25]}")
print(f"实际值:{y_hat[:25]}")

现在,我们对分类的结果进行可视化显示。首先,我们来绘制数据分布的散点图。
# 获取类别为0的样本。
c1 = X[y == 0]
# 获取类别为1的样本。
c2 = X[y == 1]
# 可以看出整体的样本分布,但是,无法观察出样本属于哪个类别。
# plt.scatter(x=X[:, 0], y=X[:, 1])
# 分开来绘制两个不同类别的样本,便于观察。
plt.scatter(x=c1[:, 0], y=c1[:, 1], c="g", label="类别0")
plt.scatter(x=c2[:, 0], y=c2[:, 1], c="r", label="类别1")
plt.legend()

接下来,我们来绘制在测试集中,样本的真实类别与预测类别。
plt.figure(figsize=(15, 5))
# 绘制真实的样本类别。
plt.plot(y_test, "o", ms=15, c="g", label="真实类别")
# 绘制预测的样本类别。
plt.plot(y_hat, "x", ms=15, c="r", label="预测类别")
plt.legend()
plt.xlabel("样本序号")
plt.ylabel("类别")
plt.title("逻辑回归分类预测结果")
plt.show()

之前我们讲过,逻辑回归的优势在于,不仅能够预测样本所属的类别,而且,还可以预测属于各个类别的概率。这在实践中是非常有意义的。接下来,我们就来求解逻辑回归预测的概率值。
# 针对参数指定的样本,返回样本属于每一个类别的概率值(信心指数)。
probability = lr.predict_proba(X_test)
print(probability[:10])
# 将概率转换成真实的类别。axis=1,表示按行进行统计。
print(np.argmax(probability, axis=1))
# 此处,也可以这样做:
# index = np.arange(X_test.shape[0])
index = np.arange(len(X_test))
# 获取属于第0个类别的概率。
pro_0 = probability[:, 0]
# 获取属于第1个类别的概率。
pro_1 = probability[:, 1]
# 根据预测值是否等于真实值(预测结果是否正确),来计算不同的符号,用来稍后图形的显示。
tick_label = np.where(y_test == y_hat, "O", "X")
plt.figure(figsize=(15, 5))
# 以概率值作为柱形图的高度。
plt.bar(index, height=pro_0, color="g", label="类别0概率值")
# bottom 指定柱形图底边(柱形图的底面)基于多少值开始绘制。通过指定bottom为开始绘制的柱形的高度,
# 这样就可以绘制堆叠图。
# tick_label 在每个柱形图下面显示标签的内容。
# 正确显示O,错误显示X。
plt.bar(index, height=pro_1, color='r', bottom=pro_0, label="类别1概率值", tick_label=tick_label)
# bbox_to_anchor 指定图例的位置。
plt.legend(loc="best", bbox_to_anchor=(1, 1))
plt.xlabel("样本序号")
plt.ylabel("各个类别的概率")
plt.title("逻辑回归分类概率")
plt.show()


绘制决策边界
我们可以绘制决策边界,将分类效果进行可视化显示。
# 颜色图类型,可以指定不同的颜色。
from matplotlib.colors import ListedColormap
# 定义颜色图对象,自定义颜色列表。
cmap = ListedColormap(["r", "g"])
# 定义标记,用来区分不同的类别。
marker = ["o", "v"]
# 获取两个特征x1与x2的最小值与最大值。
x1_min, x2_min = np.min(X_test, axis=0)
x1_max, x2_max = np.max(X_test, axis=0)
x1 = np.linspace(x1_min - 1, x1_max + 1, 100)
x2 = np.linspace(x2_min - 1, x2_max + 1, 100)
# 进行网格交叉,获取x1与x2中每一个值的组合。
X1, X2 = np.meshgrid(x1, x2)
Z = lr.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape)
# 使用填充的等高线图绘制决策边界。
plt.contourf(X1, X2, Z, cmap=cmap, alpha=0.5)
for i, class_ in enumerate(np.unique(y)):
plt.scatter(x=X_test[y_test == class_, 0], y=X_test[y_test == class_, 1],
c=cmap(i), label=class_, marker=marker[i])
plt.legend()
plt.show()

分类模型评估
混淆矩阵
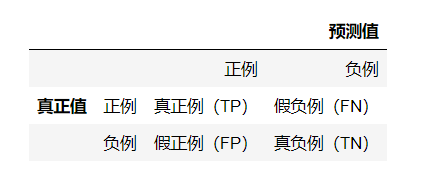
混淆矩阵,是用来表示误差,衡量模型分类效果的一种形式。该矩阵是一个方阵,矩阵的数值用来表示分类器预测的结果,包括真正例(True Positive),假正例(False Positive),真负例(True Negtive),假负例(False Negtive)。
import numpy as np
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
# 混淆矩阵,可以获取评估结果。
from sklearn.metrics import confusion_matrix
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rcParams["font.family"] = "SimHei"
mpl.rcParams["axes.unicode_minus"] = False
X, y = make_classification(n_samples=200, n_features=2, n_informative=2, n_redundant=0,
n_classes=2, random_state=0)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=0)
lr = LogisticRegression(penalty="l2", C=2)
lr.fit(X_train, y_train)
train_predict = lr.predict(X_train)
test_predict = lr.predict(X_test)
# 输出混淆矩阵的值。labels指定预测的标签,前面的为正例,后面的为负例。
print(confusion_matrix(y_true=y_test, y_pred=test_predict, labels=[1, 0]))
# matrix就是二维ndarray数组类型。
matrix = confusion_matrix(y_true=y_test, y_pred=test_predict, labels=[1, 0])
# 混淆矩阵图。
plt.matshow(matrix, cmap=plt.cm.Blues, alpha=0.5)
# 依次遍历矩阵的行与列。
for i in range(matrix.shape[0]):
for j in range(matrix.shape[1]):
# va:指定垂直对齐方式。
# ha:指定水平对齐方式。
plt.text(x=j, y=i, s=matrix[i, j], va='center', ha='center')
plt.xlabel('预测值')
plt.ylabel('实际值')
plt.show()

评估指标
从混淆矩阵中,我们可以提取如下的评估指标:
- 正确率(accuracy)
- 精准率(precision)
- 召回率(recall)
- F1(调和平均值)
各指标的定义如下:

# accuracy_score 获取正确率
# precision_score 获取精准率
# recall_score 获取召回率
# f1_score 获取精准率与召回率的调和平均值
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
# 返回一个字符串(str)类型,内容就是分类的报告,包括正例与负例的精准率,召回率与调和平均值。
from sklearn.metrics import classification_report
train_accuracy = np.sum(y_train == train_predict) / y_train.shape[0]
test_accuracy = np.sum(y_test == test_predict) / y_test.shape[0]
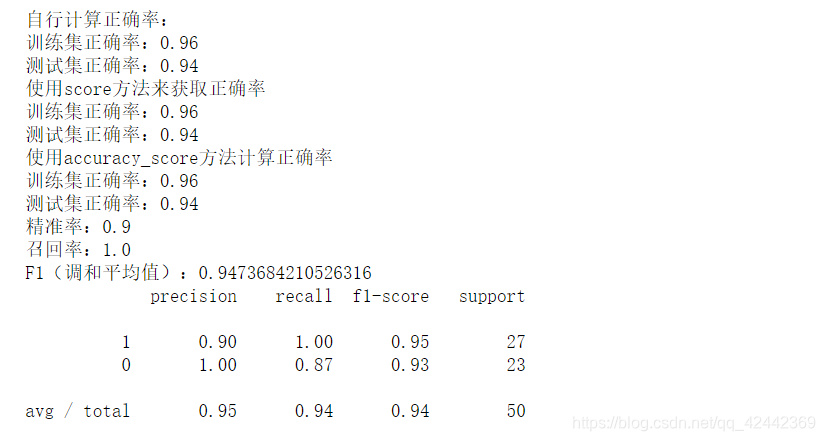
print("自行计算正确率:")
print(f"训练集正确率:{train_accuracy}")
print(f"测试集正确率:{test_accuracy}")
# 分类模型也提供了score方法,获取的就是正确率(accuracy_score)。
# 但是,注意:score方法与accuracy_score方法参数的内容不同。
print("使用score方法来获取正确率")
print(f"训练集正确率:{lr.score(X_train, y_train)}")
print(f"测试集正确率:{lr.score(X_test, y_test)}")
print("使用accuracy_score方法计算正确率")
print(f"训练集正确率:{accuracy_score(y_train, train_predict)}")
print(f"测试集正确率:{accuracy_score(y_test, test_predict)}")
print(f"精准率:{precision_score(y_test, test_predict)}")
print(f"召回率:{recall_score(y_test, test_predict)}")
print(f"F1(调和平均值):{f1_score(y_test, test_predict)}")
print(classification_report(y_true=y_test, y_pred=test_predict, labels=[1, 0]))
# accuracy_score 获取正确率
# precision_score 获取精准率
# recall_score 获取召回率
# f1_score 获取精准率与召回率的调和平均值
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
# 返回一个字符串(str)类型,内容就是分类的报告,包括正例与负例的精准率,召回率与调和平均值。
from sklearn.metrics import classification_report
train_accuracy = np.sum(y_train == train_predict) / y_train.shape[0]
test_accuracy = np.sum(y_test == test_predict) / y_test.shape[0]
print("自行计算正确率:")
print(f"训练集正确率:{train_accuracy}")
print(f"测试集正确率:{test_accuracy}")
# 分类模型也提供了score方法,获取的就是正确率(accuracy_score)。
# 但是,注意:score方法与accuracy_score方法参数的内容不同。
print("使用score方法来获取正确率")
print(f"训练集正确率:{lr.score(X_train, y_train)}")
print(f"测试集正确率:{lr.score(X_test, y_test)}")
print("使用accuracy_score方法计算正确率")
print(f"训练集正确率:{accuracy_score(y_train, train_predict)}")
print(f"测试集正确率:{accuracy_score(y_test, test_predict)}")
print(f"精准率:{precision_score(y_test, test_predict)}")
print(f"召回率:{recall_score(y_test, test_predict)}")
print(f"F1(调和平均值):{f1_score(y_test, test_predict)}")
print(classification_report(y_true=y_test, y_pred=test_predict, labels=[1, 0]))