版权声明:本文为博主原创文章,转载请附上博文链接。 https://blog.csdn.net/qq_41080850/article/details/86294173
对已有数据表进行一维和二维之间的转化:
import pandas as pd
# 读入数据:
df = pd.read_excel('2dims.xls','Sheet1')
dfdf的结构为:
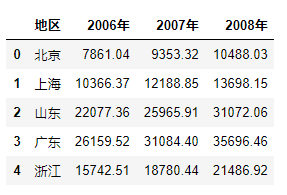
如上图所示df是一个二维表。
# 将二维数据表转化为一维数据表:
new_data = df.set_index('地区') # 将df中的地区一列设置为索引列
df1 = new_data.stack() # stack的返回对象df1是一个二级索引Series对象
df2 = df1.reset_index() # 通过reset_index函数将Series对象的二级索引均转化为DataFrame对象的列值
df2.columns = ['地区','时间','金额']
df2df2的结构为:
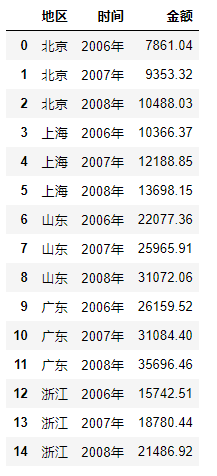
# 将一维数据表转化为二维数据表:
s = pd.Series(list(df2['金额']),index=[df2['地区'],df2['时间']]) # 利用一维数据表df2构造一个二级索引Series对象
df3 = s.unstack() # 对s执行stack的逆操作unstack
df3df3的结构为:

将SQL语句一维表形式的查询结果转化成二维表形式:
说明:在数据库sql50中有一张学生成绩表grade(sid,cid,score),其中sid表示学生编号,cid表示课程编号,score表示课程成绩。
grade表结构如下图所示:
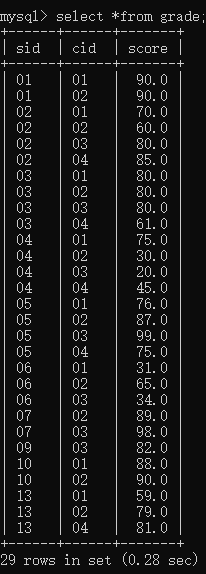
import pandas as pd
import pymysql
# 定义一个上下文管理器:
class DataBase(object):
def __init__(self,name,password):
# 创建数据库连接
self.conn = pymysql.connect('localhost','root',str(password),str(name),charset='utf8')
# 创建cursor对象
self.cursor = self.conn.cursor()
def __enter__(self):
return self.cursor # 返回cursor对象,且这个cursor对象会被赋给with语句中as后面的变量
def __exit__(self,exc_type,exc_value,traceback):
self.cursor.close() # 关闭游标对象
self.conn.close() # 断开数据库连接
def main():
with DataBase('sql50',883721) as db:
db.execute('select * from grade') # 执行sql语句
content = db.fetchall() # 获取数据(db中保存着查询结果集)
df = pd.DataFrame(list(content)) # 将从数据库中查询出的数据放入DataFrame对象中
return df
if __name__ == '__main__':
df = main()
new_cols = ['sid','cid','score']
df.columns = new_cols
df.head()df部分数据如下图所示:
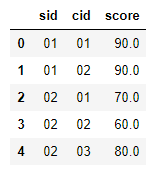
将一维表形式的查询结果转化成二维表形式:
# 将一维数据表转化为二维数据表:
s = pd.Series(list(df['score']),index=[df['sid'],df['cid']]) # 利用一维数据表df2构造一个二级索引Series对象
new_df = s.unstack() # 对s执行stack的逆操作unstack
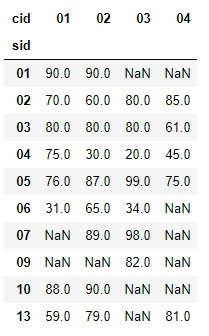
new_dfnew_df的结构为:
参考:
《Python for Data Analysis》2nd Edition
https://blog.csdn.net/qq_41080850/article/details/85100641
PS:本文为博主原创文章,转载请注明出处。