『写在前面』
最近在研究点云数据处理与应用,将学习论文中的一些值得记录和思考的点记录于此,方便自己后续回忆要点。建议参照原版paper使用,刚开始学写blog,欢迎各位指正纰漏。
- 论文出处:CVPR 2018
- 作者机构:Yangyan Li等,山东大学
Abstract
-
传统CNNs成功之处在于利用了空间局部相关性
-
而点云数据往往不规则且无序,如果直接应用传统的卷积运算,不但会丢失形状信息,还会受到点集顺序变化的影响
-
为了解决上述问题,本文提出了X-transformation,并且结合传统的卷积运算,构成X-conv模块,也就是PointCNN的building block。
1 Introduction
- 在某些情况下,使用point cloud表示数据比使用dense grid更为有效:比如三维空间中的平面,二维空间中的直线等。
以三维空间的平面为例:
如使用point cloud表示, 其中, 表示点的数量, 表示各点坐标,那么 的数据量为 .
如使用dense grid表示,假设空间大小为 ,则数据量大小为
一般情况下, ,所以Point Cloud效率更高?
-
,但二者形状不同,故CNNs会丢失形状信息;
,但其实二者代表的是统一形状,只是顺序不同,说明CNNs无法适应不同点集顺序。
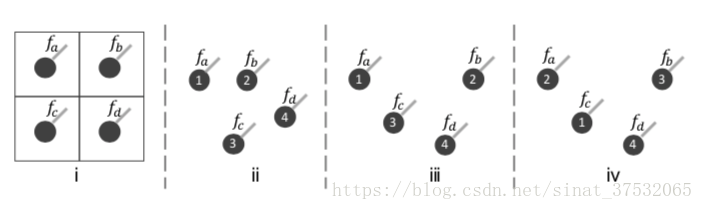
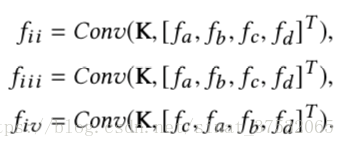
- X-transformation.
从K个输入点中学习一个K×K的矩阵:
使用X对输入特征同步进行加权和排列,最后对变换后的特征进行卷积,称这一系列操作为X-Conv,这也是PointCNN的基本模块。
关于这一段的理解:
- 和 从不同形状的点集中学习得到,故可以使得 与 不同;
- 通过学习得到的 可能等于 ,且 ,所以使得 .
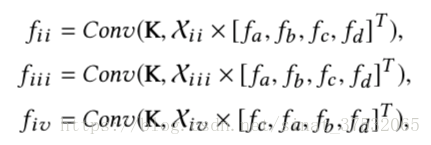
理想情况下,X-transformation可以做到考察点集形状的同时不受点集顺序的影响。但实际中,作者发现其效果并不理想,尤其是点集顺序重排。
2 Related Work
-
PointCNN做到了输入特征表示和卷积核的稀疏性。
-
PointNet和Deep Sets使用对称函数(symmetric function)来克服输入点集的无序性。尽管对称函数有理论支撑,但它带来丢失信息的代价。
-
作者认为,PointCNN中的X-Conv结构在提取局部特征时,比PointNet中使用的最大池化表现更好。
-
STNs中使用了对称矩阵作为kernel。而在PointCNN中,X-transformation需要同时服务于权值和排序,所以使用了普通矩阵建模。意思是,如果只用来做排序,就可以用其他加以限制的矩阵实现?比如文中举了个例子doubly stochastic matrix(还没有具体看这块)。
3 PointCNN
3.1 Hierarchical Convolution
-
CNNs的分层结构会使得分辨率越来越小,通道数越来越多,feature map编码更高层的信息。
-
X-Conv参考CNNs分层结构的思想,将输入点集映射或聚合到下一层,“less and less points, richer and richer features”.
-
需要注意的是, 基于的点集( )并不一定要求是 基于的点集的子集( ).但在本文实现中,使用的都是采样的方法(所以都是子集):分类任务,使用随机下采样方法获得 ;而分割任务中,使用FPS(最远点采样法)。
作者提到,他们认为一些代表点生成算法可能更加有效,如Deep Points。
3.2 X-Conv Operator
- X-Conv使用 在 中的邻近点集作为输入
是 在 中的邻近点集。从 中采样 个点,得到X-Conv的输入 。 是一个无序点集,可以表示为 进而,可以得到,X-Conv中的trainable kernel是一个tensor ,其大小为 .
-
X-Conv算法描述
输入: - trainable kernel
- 映射/聚合标点
- 输入点集
- 输入点的特征集输出: - 映射/聚合到 的特征
步骤:
- 将输入点集 中各点坐标迁移到以点 为原点的相对坐标系,得到点集合 ;
- 通过MLP将 中每个点映射到高维空间 中,得到特征矩阵 ;
- 将输入点的特征集 和上一步得到的特征矩阵 直接拼接,得到新的特征矩阵 ;
- 使用MLP从点集合 中学习到一个K×K大小的变换矩阵 ;
- 使用变换矩阵 对特征矩阵 进行矩阵变换(加权&排序),得到特征矩阵 ;
- 对 和 进行卷积,得到输出特征矩阵 .
因为上述算法中所涉及到的卷积、MLP和矩阵乘法都是可微分的,故整个X-Conv模块可微,可以很方便地使用BP算法训练。
上文中提到,X-Conv的kernel size为 ,其参数量主要受 影响,与CNNs中的平方和3D-CNNs中的立方相比,具有稀疏性。可以节省内存和算力。Sparse kernel的一个好处是可以在不显著增加参数数量的情况下耦合较远距离信息。
-
关于局部坐标系的几点讨论
1. X-Conv被设计用来刻画局部点集信息,所以应转换到中心点的相对坐标系。
2. 注意一个点可能会是多个代表性点的邻近点,所以这样的点可能以不同的相对坐标作用在不同的代表性点上(Figure.3 主要就是在解释这个)。
3. 局部坐标应作为部分特征输入到X-Conv中,但由于坐标特征与其他额外的特征相比,维度一般较低(不一致),故作者通过MLP来进行高维映射,以得到更加抽象的特征表示(该做法与PointNet类似)。 -
关于X-Conv的几点讨论
1. X-Conv的一个优点是它可以以一种统一的形式作用在有或没有额外特征的点云数据上,如XYZ点云、XYZI点云等。例如对XYZ点云而言,X-Conv层的输入只有 ,没有 。
2. 理论上,X-变换既可以用在feature上,也可以用在kernel上。但为了便于运行标准的卷积运算(一般建模成kernel被训练,而不是被X-变换“孵化”出来的kernel再训练),作者用在了变换feature上。
3.3 PointCNN Architecture
-
CNNs中的卷积层 VS PointCNN中的X-Conv结构
1. 局部区域提取:卷积层使用K×K的窗口,X-Conv使用K-近邻;
2. 学习特征的方法不同。 -
感知野
定义每个代表性点的感知野为 ,其中 代表近邻点数, 代表上一层的总点数。 意味着本层的代表点get到了上一层的全局信息。
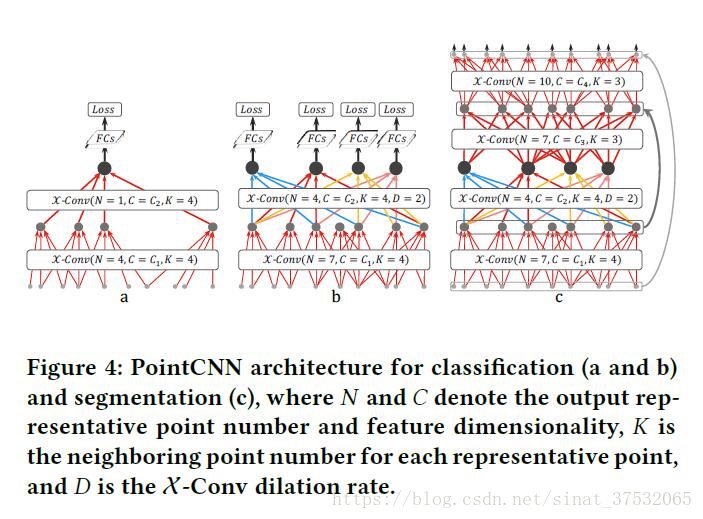
-
分类网络结构
论文中,作者给出了两款用于完成分类任务的网络结构,Figure 4(a) 和 Figure 4(b).(a)中给出的网络结构采样数下降过快,导致X-Conv层不能被充分训练。作者为了改进此问题,提出了(b)结构,旨在控制网络深度的同时兼顾感知野的增长速度,使模型具有"see larger and larger"的能力。
借鉴CNNs中膨胀卷积的思想,作者也引入了膨胀因子 。具体做法是从 个近邻点中均匀采样得到最后的K个近邻点。这样使得在不增加近邻点数量,也就是没有增大kernel size的情况下,将感知野从 增大到 。如图(b)所示,在fc层之前的4个代表点都可以看到整个形状,所以它们都具有进行预测的能力。 -
分割网络结构
采用类似Conv&DeConv的结构,并且在Conv阶段和DeConv采用的均是X-Conv结构。不同之处在于在DeConv处,输出比输入含有更多的点数和更少的特征数 -
其他Trick的使用
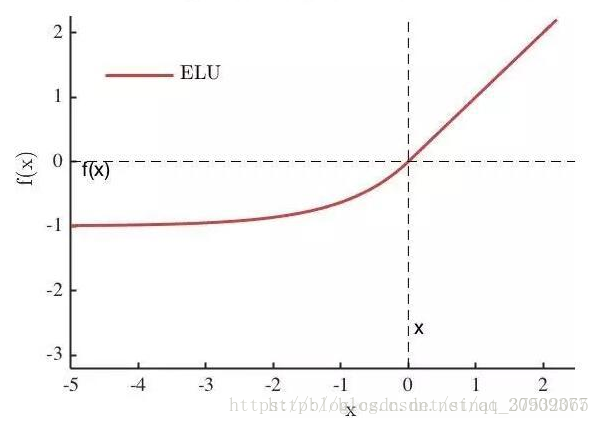
1. 激活函数选择使用ELU(Exponential Linear Unit),数学表达如下所示。
摘自:https://blog.csdn.net/qq_20909377/article/details/79133981
其中 是一个可调整的参数,它控制着ELU负值部分在何时饱和。右侧线性部分使得ELU能够缓解梯度消失,而左侧软饱能够让ELU对输入变化或噪声更鲁棒。ELU的输出均值接近于零,所以收敛速度更快。
tensorflow中:tf.nn.elu(features, name=None)
2. BN层的使用。在 、 和全连接层(最后一层除外)上采用了批归一化。但没有用在MLP 和MLP上,因为 和 ,尤其是 ,旨在实现对特殊代表点的特定表示。
3. 卷积运算使用了分离卷积(separable convolution)以降低参数数量和计算消耗。
4. 在最后一个全连接层之前加了Dropout,还使用了"subvolume supervision"来缓解过拟合。
5. 最后一个X-Conv层中,感知野被设置为小于1的值,这样做的目的是使得该层的输出仅能涵盖原始数据中的部分信息,迫使模型在训练过程中更多地去学习如何捕捉有价值的局部信息。
6. 关于数据增强。随机采样和打乱顺序。作者建议,如果想要训练一个以N个点作为输入的PointCNN模型,各训练样本点数的的选择应服从高斯分布 ,这点至关重要。