版权声明:未经允许,禁止转载 https://blog.csdn.net/weixin_43216017/article/details/87179623
在进行分类和聚类问题时,我们需要使用数据来测试算法的效果,此时采用生成两类不同的二维点(如下图)的方式的最直观的。

此时,我们可以很清晰的看到,蓝色的点为一类,红色的点为一类。我们可以使用这样的数据来测试我们算法的效果。
本文将阐述如何生成这样的二维点,并加上标签,最后整理成dataframe的格式。(如果时聚类问题,那么就不需要添加标签。)
python代码
import numpy as np
import pandas as pd
from pandas.core.frame import DataFrame
import matplotlib.pyplot as plt
#生成两个二维随机点,并转化为dataframe格式
#A的横纵坐标都在(9,10)之间
A = [[np.random.uniform(9,10) for i in range(100)],[np.random.uniform(9,10) for i in range(100)]]
#B的横纵坐标都在(8,9)之间
B = [[np.random.uniform(8,9) for i in range(100)],[np.random.uniform(8,9) for i in range(100)]]
#将其转化成dataframe格式
data_1 = DataFrame(A).T
data_2 = DataFrame(B).T
data_1.head()结果如下:
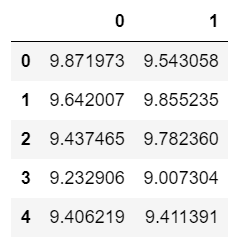
#将两个dataframe合并到一起
frames=[data_1,data_2]
data=pd.concat(frames)
#将列名改成x1和x2
data.columns = ['x1','x2']
print(data)到此为止,我们已经将两个dataframe合并,并且修改了列名。但是,合并之后的dataframe其index还是和原来合并之前的index相同。(即此时的index不是从0-199,而是从0-99、0-99)
我们查看最后5行即可
data.tail()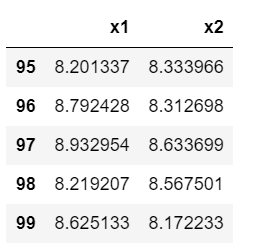
我们发现最后5行的index是95-99,而非195-199
为了方便数据的使用,我们需要将这个index重新排列
data = data.reset_index(drop = True)如果不加"drop = True",则原来的index将作为新的一列填入数据中。
最后,我们为数据添加标签
data['y'] = ''
for i in range(len(data)):
if 9 < data['x1'][i] < 10:
data['y'][i] = 0
else :
data['y'][i] = 1在数据生成了之后,我们进行一下可视化的工作,所绘制的图形正如开篇的图形所示:
plt.scatter(A[0],A[1],c='b',marker = 'o')
plt.scatter(B[0],B[1],c='r',marker = 'o')
plt.axis([8,10,8,10])
plt.show()所生成的二维数据点带有标签时,可以用作分类使用;不带标签时,可以做聚类使用。