Deep Convolutional Generative Adversarial Networks
Generative Adversarial Networks最有趣的部分之一是生成器网络的设计。 生成器网络能够获取随机噪声并将其映射到图像中,使得鉴别器无法分辨哪些图像来自数据集以及哪些图像来自发生器。
这是神经网络的一个非常有趣的应用。 通常,神经网络将输入映射到二进制输出(1或0),可能是回归输出(某些实数值),或甚至是多个分类输出(例如MNIST或CIFAR-10/100)。
在本文中,我们将看到神经网络如何从随机噪声映射到图像矩阵,以及如何在生成器网络中使用卷积层产生更好的结果。
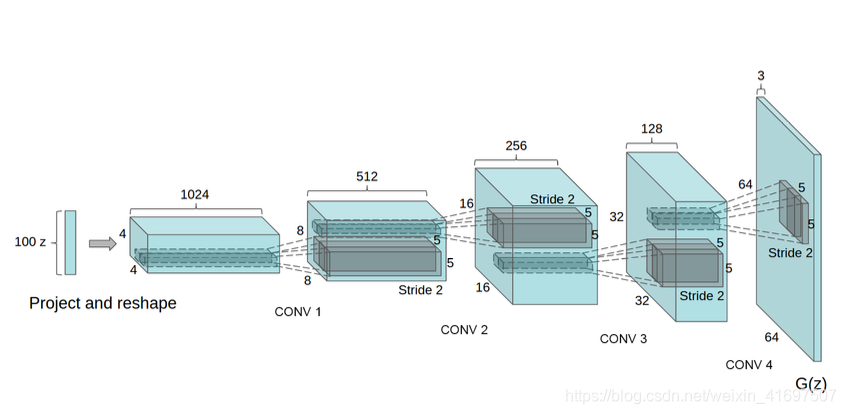
这是LSUN场景建模论文中提出的DCGAN生成器。 该网络采用100x1噪声向量,表示为z,并将其映射到G(Z)输出,即64x64x3。
这种架构特别有趣的是第一层扩展随机噪声的方式。 网络从100x1到1024x4x4! 该层表示为“项目和重塑”。
我们看到,在这一层之后,应用了经典的卷积层,它使用卷积层经典地教导的(N + P - F)/ S + 1方程重塑网络。 在上图中我们可以看到N参数(高度/宽度)从4到8到16到32,看起来没有任何填充,内核过滤器参数F是5x5,并且步幅 是2.您可能会发现此公式对于设计自己的卷积层以用于自定义输出大小非常有用。
100x1 → 1024x4x4 → 512x8x8 → 256x16x16 → 128x32x32 → 64x64x3

以上是本文提出的网络输出,并指出这是在经过5个时期的训练之后。 相当令人印象深刻
现在,让我们看一些python代码:
此代码取自Jakub Langr和Vladimir Bok创建的gans-in-action存储库,我发现这是在Keras中实现GAN的最佳入门代码。 我不认为这本书已经发布,但我想它会非常好。
- 下面的代码是我如何运行我的第一个GAN网络(不实现DCGAN):
def generator(img_shape, z_dim):
model = Sequential()
# Hidden layer
model.add(Dense(128, input_dim = z_dim))
# Leaky ReLU
model.add(LeakyReLU(alpha=0.01))
# Output layer with tanh activation
model.add(Dense(28*28*1, activation='tanh'))
model.add(Reshape(img_shape)
z = Input(shape=(z_dim,))
img = model(z)
return Model(z, img)
下面的架构并不太复杂,实际上在MNIST数据集示例中确实产生了相当不错的结果。 该模型接收噪声向量并将其映射到密集连接的层,该层映射到输出层,该输出层是平坦的784x1向量,其被重新整形为28x28 MNIST数字矩阵。
现在让我们将其与gans-in-action存储库中提供的DCGAN代码进行对比:
def generator(img_shape, z_dim):
model = Sequential()
# Reshape input into 7x7x256 tensor via a fully connected layer
model.add(Dense(256*7*7, input_dim = z_dim))
model.add(Reshape((7,7,256))
# Transposed convolution layer, from 7x7x256 into 14x14x128 tensor
model.add(Conv2DTranspose(
128, kernel_size = 3, strides = 2, padding='same'))
#Batch normalization
model.add(BatchNormalization())
#Leaky ReLU
model.add(LeakyReLU(alpha=0.01))
# Transposed convolution layer, from 14x14x128 to 14x14x64 tensor
model.add(Conv2DTranspose(
64, kernel_size=3, strides=1, padding='same'))
# Batch normalization
model.add(BatchNormalization())
# Leaky ReLU
model.add(LeakyReLU(alpha=0.01))
# Transposed convolution layer, from 14x14x64 to 28x28x1 tensor
model.add(Conv2DTranspose(
1, kernel_size = 3, strides = 2, padding='same'))
# Tanh activation
model.add(Activation('tanh'))
z = Input(shape=(z_dim,))
img = model(z)
return Model(z, img)
我们看到上面的架构非常类似于ICLR,LSUN场景生成器文件中提出的DCGAN。 输入从100x1噪声投射到7x7x256张量,然后进行卷积,直到达到28x28x1 MNIST数字输出。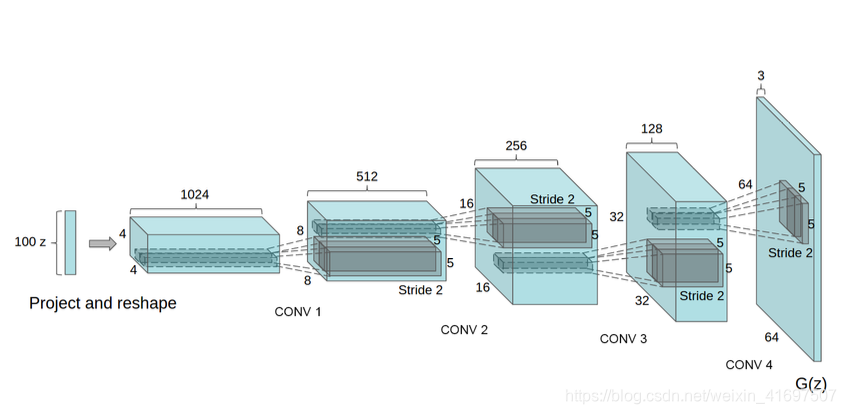
同样,我们看到同一个项目并重新整形,然后将卷积层插入到起始代码中的图表输出中。
- Conclusion
我希望这篇文章能帮助您开始构建自己的DCGAN。 我认为它至少可以很好地解释高级架构应该如何工作。 剩下的挑战在于为卷积层以及项目和重塑层找到正确的参数。
我真的找到了这个开源代码库和ICLR文件的组合来帮助我理解这个概念。 我非常高兴能够建立GAN并了解他们能做些什么,请对您认为真正有用的任何其他资源发表评论。 如果您希望通过使用这些DCGAN进行数据扩充的进一步研究,请关注。