前面我们已经尝试了Hadoop的单机部署测试,下面在单节点上进行伪分布式的部署测试
一、单节点部署参考我的博文:
https://blog.csdn.net/qq_15903671/article/details/84950117
二、伪分布式部署
所谓伪分布式是因为只有一个节点,但是完整的启动hadoop的HDFS deamon和YARN deamon。其中,
HDFS deamon包含:NameNode、DataNode、SecondaryNameNode
YARN deamon包含:ResourceManeger、NodeManager
2.1 配置基本信息
etc/hadoop/hadoop-evn.sh文件,修改java_home

etc/hadoop/core-site.xml文件,设置全局配置
<property>
<name>fs.default.name</name>
<value>hdfs://localhost</value>
<description>HDFS的URI,文件系统://namenode标识:端口号</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>

etc/hadoop/hdfs-site.xml文件,设置节点数为1
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/hadoop/hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/hadoop/hdfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>副本个数,应小于datanode机器数量</description>
</property>

etc/hadoop/mapred-site.xml.template 复制后更名为etc/hadoop/mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>

etc/hadoop/yarn-site.xml 文件(注意:节点内存配置成4G才能跑起来!虚拟机分配内存的时候也要超过4G!!这个内存配置不能太小,hadoop执行时候一上来就取1.5G内存使用,配置太小直接溢出)
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value><!--total memory -->
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>2</value><!--num of cpu -->
</property>

2.2 启动HADOOP
2.2.1 指令:hdfs namenode -format 格式化文件系统

下面截图的地方会提示namenode的地址,输入大写的Y即可。留意,每次format namenode节点都将产生新的clusterID,这个编码在下面截图这个提示的地址下面name/current/VERSION文件里,相应的,datanode节点也有对应的VERSION文件和clusterID属性,而这个clusterID是不会在format的时候被更新的。

上面截图中的地址已定要记住,这是dfs的配置地址。如果在开发测试时多次format dfs的namenode,会导致namenode的clusterID和datanode的clusterID不一致,需要到这个地址下找到name/current/VERSION中的clusterID复制粘贴到data/current/VERSION文件中才能正常启动datanode。否则下面start-dfs.sh的时候会发现,datanode无法启动。
2.2.2 启动hadoop守护进程
在hadoop安装路径下输入指令 sbin/start-all.sh 启动HADOOP相关守护进程,ssh免密登录配置好的话就不用反复输密码,否则。。。呵呵。。

启动后输入 jps -l 命令查看jvm后台进程的执行情况,看到NameNode和DataNode已经启动了。
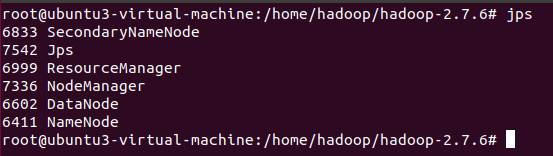
留意:
有时候NameNode起不来,优先检查一下hdfs-site.xml文件中name和node节点的配置信息,然后比对name节点上current/VERSION文件中的clusterID 跟 data节点上的current/VERSION文件中的clusterID信息是否一致。
有时候NodeManager节点启动的时候是在的,执行hadoop jar执行测试程序之后就宕掉了(当然测试程序也不会成功),优先看logs中的nodemanager日志是否为内存溢出,yarn-site.xml 中如果不配置内存和cpu的话默认是8G内存8个内核。。。本地虚拟机的话很少会给这么大内存,内存溢出可能性极大。这时候只要给定适当的内存和cpu配置并增加虚拟机分配的内存就可以了。
2.3 创建HDFS目录做测试准备:
指令:hdfs dfs -mkdir /user
指令:hdfs dfs -mkdir /user/test
拷贝一些文件输入文件到新创建的HDFS目录下
指令:hdfs dfs -put etc/hadoop /user/test/input
查看拷贝情况
指令:hadoop fs -ls /user/test/input

放了这么多文件进去,当然是为了测试一下了。
2.4 执行hadoop测试程序看看效果
执行指令: hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar grep /user/test/input /user/test/output '<name>[a-z.]+'
查看结果
hadoop fs -ls /user/test/output
hadoop fs -cat /user/test/output/part-r-00000

三、集群部署测试