一、假设检验与方差检验
①假设检验
1.建立原假设Ho(包含等号),Ho的反命题为H1备择假设
2.选择检验统计量
假设检验量:
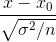
3.根据显著水平,确定拒绝域(一般为0.05)与之相反的是接受域
4.计算P值或样本值做出判断
根据检验量,查【标准正态分布表】得到P值 ,得到的P值跟拒绝域做比较,判断假设条件是否成立。
②卡方检验
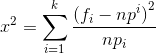
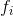
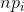
根据公式计算出卡方值。
然后根据拒绝域P值通过查表【分布临界值表】查出卡方值,对比求出的卡方值进行判断条件是否成立。
③方差检验
判断两组以上的样本均值是否有显著性差异
总平方和SST(total sum of squares)
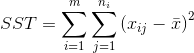
解释平方和SSE(explained sum of squares),也成模型平方和
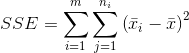
残差平方和SSR(residual sum of squares),也称剩余平方和
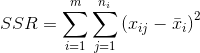
检验统计量F,做假设检验【F满足自由度(m-1,n-m)的F分布】
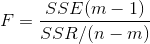
根据检验统计量查表得到P值,与拒绝域值进行比较,得到样本的差异性。
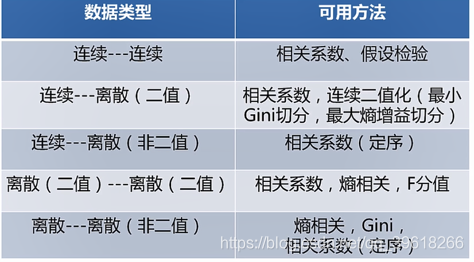
二、相关系数
①皮尔逊相关系数
两个变量之间的皮尔逊相关系数定义为两个变量之间的协方差和标准差的商:
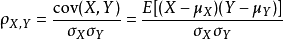
样本的简单相关系数一般用r表示,其中n为样本量, 分别为两个变量的观测值和均值。r描述的是两个变量间线性相关强弱的程度。r的取值在-1与+1之间,若r>0,表明两个变量是正相关,即一个变量的值越大,另一个变量的值也会越大;若r<0,表明两个变量是负相关,即一个变量的值越大另一个变量的值反而会越小。r 的绝对值越大表明相关性越强,要注意的是这里并不存在因果关系。若r=0,表明两个变量间不是线性相关,但有可能是其他方式的相关(比如曲线方式)等
②斯皮尔曼相关系数
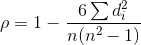
一种确定被观测数据的ρ值是否显著不为零(r总是有1≥r≥−1)的方法是计算它是否大于r的概率,作为原假设,并使用分层排列测试进行检验。这种方法的优势之处在于它考虑了样本中的数据个数和在使用样本计算等级相关系数的风险。
三.回归
线性回归
回归:确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法

决定系数
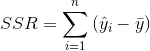
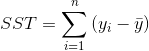
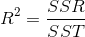
adjusted
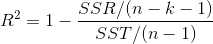
残差不相关(DW检验)
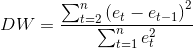
比如说有十组回归值就有十组残差,将这些残差值以自变量从小到大的顺序排序,然后套入以上公式得到DW值。
DW是0<D<4,统计学意义如下:
1.当残差与自变量互为独立时,D=2或DW越接近2,判断无自相关性把握越大
2.当相邻两点的残差为正相关时,D<2,DW越接近0,正自相关性越强
3.当相邻两点的残差为负相关时,D>2,DW越接近4,负自相关性越强
四.PCA与奇异值分解
①主成分分析
1.求特征协方差矩阵
2.求协方差的特征值和特征向量
3.将特征值按照从大到小的顺序排序,选择其中最大的k个
4.将样本点投影到选取的特征向量上
②奇异值分析(暂略)
五.复合分析
①交叉分析
交叉分析法又称立体分析法,是在纵向分析法和横向分析法的基础上,从交叉、立体的角度出发,由浅入深、由低级到高级的一种分析方法。这种方法虽然复杂,但它弥补了“各自为政”分析方法所带来的偏差。
②分组与钻取
钻取是改变纬的层次,变换分析的粒度
根据钻取方向的不同可以分为
向上钻取:汇总分组数据的过程
向下钻取:展开数据查看数据细节的过程。
连续属性的分组,在分组之前需要进行离散化。在连续属性离散化之前,我们需要看一下数据分布,是不是有明显的可以区分的标志。比如将数据从小到大排列后,有没有一个明显的分隔或者明显的拐点,如果有可以直接使用。
分隔就是相邻两个数据的差。我们可以认为他是一阶差分
拐点就是二阶差分。
连续属性的分组要尽可能的满足相同的分组比较聚拢,不同的分组比较分离的特点,所以我们可以用聚类的方法进行连续属性的分组。比如我们可以用kmeans方法来进行指定分组数目的连续属性分组,如果考虑标注,我们也可以结合不纯度的检验指标Gini系数来进行连续数据的离散化分组。
不纯度(Gini系数)
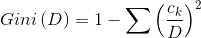
D:目标的标注(label)

连续值的
先将表按照连续值的大小进行排序,然后相邻两两之间划定界限,分别确定分组值。
根据不纯度使用分组使用最多的是分类模型中决策树算法中的CART算法
③相关分析
是衡量两组数据或者说两组样本,分布趋势或者变化趋势大小的分析方法。
最常见的分析方法是上面讲到的皮尔逊、斯皮尔曼分析方法
用相关系数直接衡量相关大小
1.熵
熵表示随机变量不确定性的度量,熵越大代表随机变量的不确定性就越大。
公式:
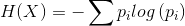
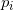
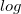
2.条件熵
条件熵表示在条件X下Y的信息熵,既在X条件下Y的熵即为X分布下对于Y分别计算熵,然后进行求和
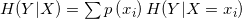
3.信息增益(熵增益)
熵增益=信息熵 - 条件熵
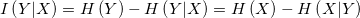
缺点:对于分类数目多的特征它有不正确的偏向,也就是说他不具有归一化的特点,他的不确定是上不封顶的
4.信息增益率
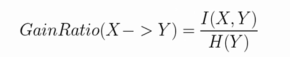
因为互信息是小于Y的,所以这个值一定是小于1的。
又由于熵本来就是大于0所以增益率介于0到1之间。
用熵的增量率去衡量相关性是不妥的,因为熵的增益率是不对称的。
也就是说X对Y的增益率或者是Y对X的增益率是不一致的。
5.相关性
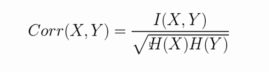
这个值还是0到1,同时也满足了X,Y的对称性。
④因子分析
从多个属性变量中分析共性相关因子的方法
1.探索性因子分析:
通过协方差矩阵、相关性矩阵等指标分析多元属性变量的本质结构,并可以进行转化,降维等操作
2.验证性因子分析:
是验证于因子与我们关注的属性之间是否有关联、有什么样的关联、是否符合我们的预期等等
⑤聚类分析(暂略)
⑥回归分析(暂略)