今天因为这个问题和大佬们交流了几句,颇有感悟,和大佬交流就是不一样,处处充满着上位者的气息,最终还是成功的解决了我的疑问,等我搞明白这个问题后,顿时感觉自己好low,这么简单的问题还请教人家!
大佬也给了我一些学习方法上的指教,对于一个学习者来说,一个方法的使用不能上来就看如何实现的,怎么用的,而是先深入的了解其原理,为什么要这样做,如何理解,这样当你遇到问题时,才不会停于表面,苦苦思索而不得结果。这也让我想起了一句话,之前只是感觉它是对的,现在终于领会它的深刻内涵了,“基础决定高度,而不是高度决定基础”。
当你达到一定的高度之后,回想起以前的自己,是不是感觉那个时候的自己就像一个白痴。好了,不多说了,发了点小感慨。还是言归正传吧。
CNN中非常有特点的地方就在于它的局部连接和权值共享,通过卷积操作实现局部连接,这个局部区域的大小就是滤波器filter,避免了全连接中参数过多造成无法计算的情况,再通过参数共享来缩减实际参数的数量,为实现多层网络提供了可能。
卷积操作
在CNN中是利用卷积层进行特征提取的,图像的三个通道R(red)、G(green)、B(blue),分别用不同的卷积核来进行卷积操作,说起卷积核这让我想起了我之前对图像进行的滤波处理,卷积运算本质上就是在滤波器和输入数据的局部区域间做点积,所以可以用矩阵乘法来实现,其实这是一个道理,卷积核对图像的操作可以用下图来表示:
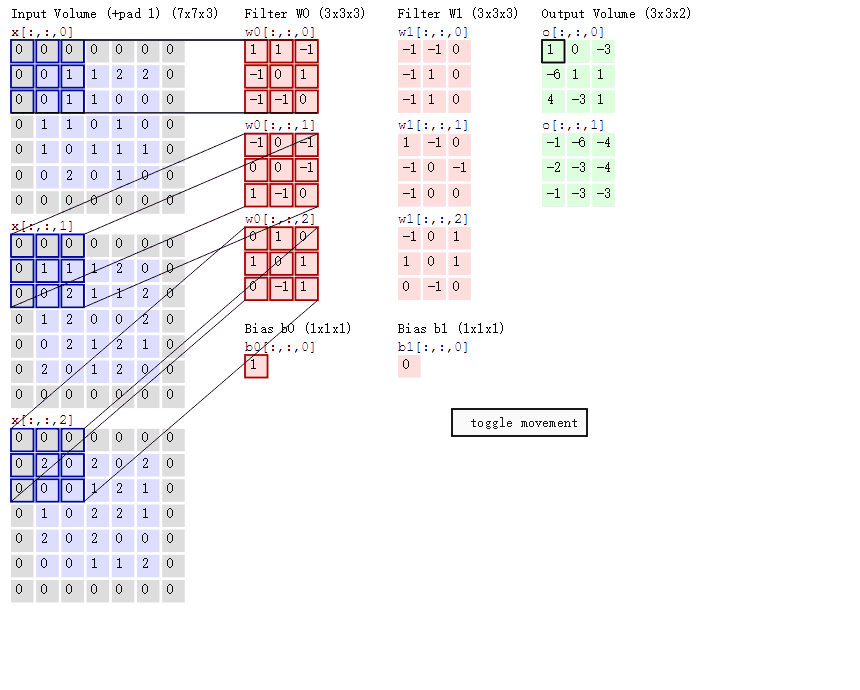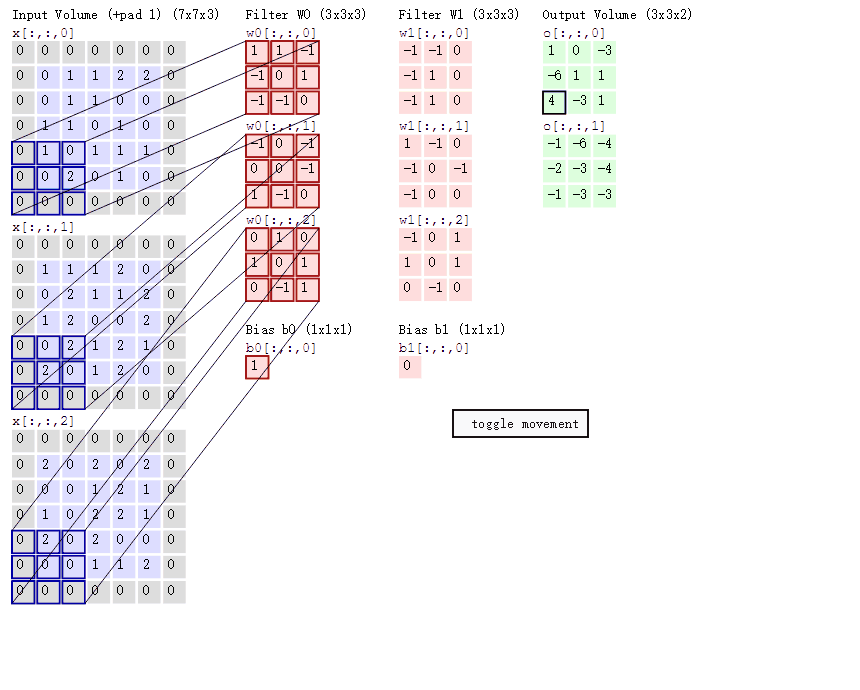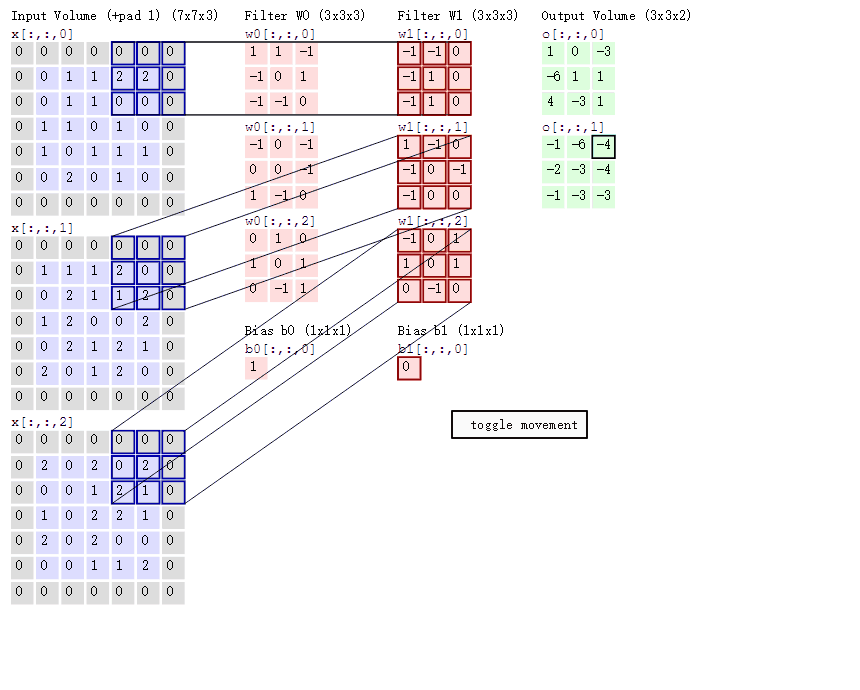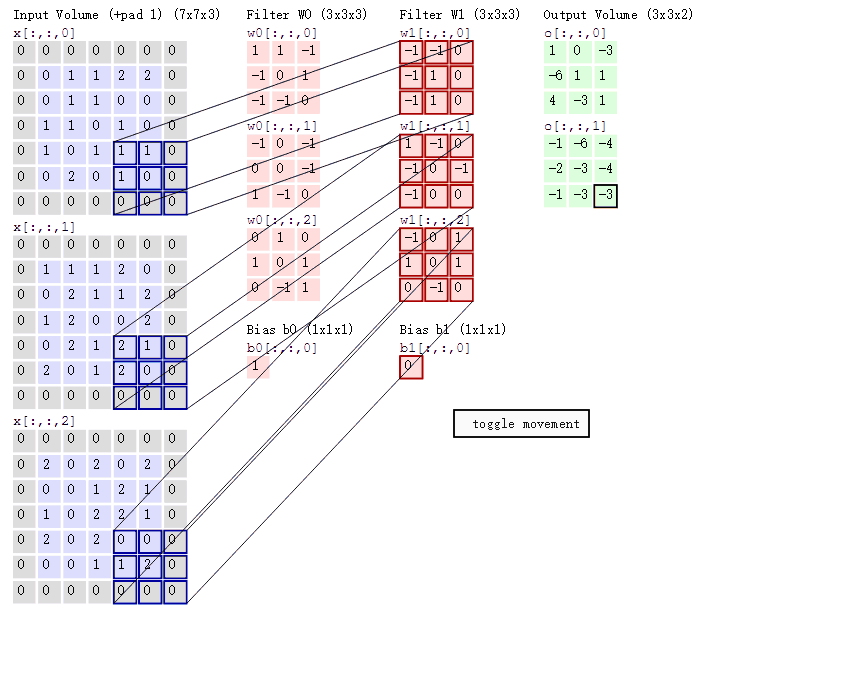

为什么会设置不同的filter呢,因为不同的滤波器filter会得到不同的输出数据,比如颜色深浅、轮廓。相当于如果想提取图像的不同特征,则用不同的滤波器filter,提取想要的关于图像的特定信息:颜色深浅或轮廓。如下图,左边是图像输入,中间部分就是滤波器filter(带着一组固定权重的神经元):

输入图像是32*32*3的,32表示的图像尺寸大小,3表示的它的深度(即RGB三个channel),卷积层是一个5*5*3的滤波器(filter),filter的深度必须和输入图像的深度相同,通过一个filter与输入图像的卷积可以得到一个28*28*1的特征图,下图是用了两个filter得到了两个特征图:


权值共享
在下图中,如果不使用权值共享,则特征图由10个32*32*1的特征图组成,每个特征图上有1024个神经元,每个神经元对应输入图像上的一块5*5*3的区域,所以一个神经元和输入图像的这块区域有75个连接,即75个权值参数,则共有75*1024*10=768000个权值参数,这对于参数的调整和传递非常不利,因此卷积神经网络引入权值共享原则,一个特征图上每个神经元对应的75个权值参数被每个神经元共享,这里的共享其实就是指的每个神经元中75个权值参数采用对应相同的权值,权值共享时,只是在每一个filter上的每一个channel中是共享的,这样便只需75*10=750个权值参数,而每个特征图的阈值也共享,即需要10个阈值,则总共需要750+10=760个参数。

神经元的偏置部分也是同一种滤波器共享的。