版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/LaineGates/article/details/79240232
关键词
Bi-GRU, Bi-LSTM, attention sum
来源
arXiv 2016.03.04 (published at ACL 2016)
问题
使用带attention的深度模型解决完型填空问题
技术细节
模型比attentive reader简单,分以下几步:
- 使用双向GRU/LSTM单元计算docment每个词的拼接词向量
doc_endcoer - 使用双向GRU/LSTM单元计算query正向尾词和反向首词的拼接词向量
query_endcoer - 计算
doc_endcoer和query_endcoer的乘积,获得attention_res,并softmax(以保证值为正) - 将
attention_res中备选词的attention分别累和(论文的关键所在,成为之后完型填空的深度模型的必备结构) - 计算交叉熵并更新梯度
如图:
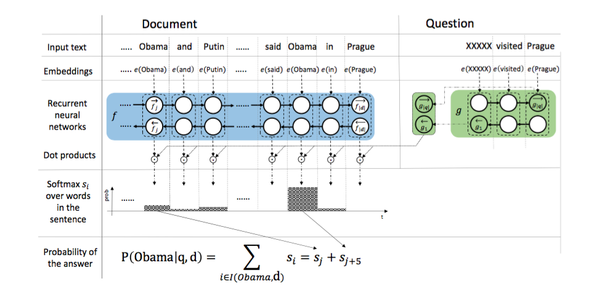
模型实现关键点
- 由于document长,大约600+/700+,有极个别更长的,这就导致之后训练时document的gradients很大,占用很多内存,笔者的11G显存经常报不够用。所以document长度700内就够了,batch_size设32基本就到极限了
- 计算准确率时,要计算本epoch内累积准确,而不能以batch为单位,否则会出现准确不断跳动的情况,让人以为训练有错
- 第5步计算交叉熵时,不能再计算第二次softmax,要计算normalize;即假设第4步输出为
,那么
因为第3步计算attention_res已经是softmax过的,其内所有值都属于 ,document长度为700左右,每个值大约都是千分之几到百分之几,这些数再softmax之后,基本成了平均数,比如 。