-**
sort(0)/sort(1)
**
出自第八章P140
sort是用于排序的,对于矩阵用sort(0),sort(1),对于矩阵用这两个函数效果是不一样的

sort(0)用于对矩阵的列元素进行从小到大排序,在每一列分别进行排序

sort(1)用于对矩阵的行元素进行从小到大排序,在每一行分别进行排序
所以文中这里用sort(0)得到的是:
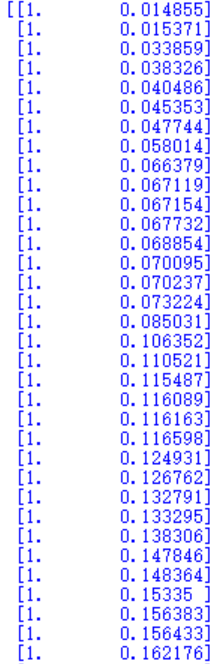
… …
np.mean()/np.var()
出自第八章P147
mean(Matrix,0):
对矩阵每列求均值,得到一个行向量
mean(Matrix,1):
对矩阵每行求均值,得到一个列向量
var(Matrix,0):
对矩阵每列求最大差值,得到一个行向量(都是正的)
var(Matrix,1):
对矩阵每行求最大差值,得到一个列向量(都是正的)
- **
map()
**
出自机器学习实战第九章P161
ls=[1,2,3]
rs=map(str,ls)
print(rs)
得到<map at 0x3fed1d0>
要想查看具体是啥:
ls=[1,2,3]
rs=map(str,ls)
print(list(rs))
- **
scatter()
scatter(x,y)中间的x,y填x坐标和y坐标,但是这里填的必须是array类型
**
一般dataMat得到的是一个矩阵,这个时候需要:
1.ax.scatter(array(datMat[:,0]),array(datMat[:,1]))强制转化成array
2.ax.scatter(datMat[:,0].flatten().A[0],datMat[:,1].flatten().A[0])
利用flatten().A[0]
**
.rand()、.randint()、.randn()、.random()
出自第十章P186
**
1、np.random.rand(d0, d1, …, dn)
根据给定维度生成[0,1)之间的数据,包含0,不包含1
dn表格每个维度
返回值为指定维度的array
np.random.rand(3,2)
np.random.rand(3,2,2)
2、randn(d0, d1, …, dn)返回一个样本,具有标准正态分布。
randn函数返回一个或一组样本,具有标准正态分布。
dn表格每个维度
返回值为指定维度的array
np.random.randn(3,2)
np.random.randn(3,2,2)
3、randint(low[, high, size])
返回随机整数,范围区间为[low,high),包含low,不包含high
参数:low为最小值,high为最大值,size为数组维度大小,dtype为数据类型,默认的数据类型是np.int
high没有填写时,默认生成随机数的范围是[0,low)
#high没有填写时,默认生产随机数的范围为[0,low)
In [6]: np.random.randint(3)
Out[6]: 2
#low为1,high为5,区间为[1,5)
In [10]: np.random.randint(1,5)
Out[10]: 2
In [7]: np.random.randint(3,size =10)
Out[7]: array([2, 2, 1, 1, 2, 2, 1, 2, 0, 2])
In [8]: np.random.randint(3,size =[2,2])
Out[8]:
array([[0, 0],
[1, 0]])
4、numpy.random.choice(a[, size, replace, p])生成一个随机样本,从一个给定的一维数组
从给定的一维数组中生成随机数
参数: a为一维数组类似数据或整数;size为数组维度;p为数组中的数据出现的概率
a为整数时,对应的一维数组为np.arange(a)
#a为整数时,对应的一维数组是np.arange(a)
#第一个参数值5对应的a,即传入的数据组
#第二个参数3就是数组的size,传入单值时,数据维度是一维的
#此处将生成一个一维数据包含3个小于5的整数的数组
In [18]: np.random.choice(5,3)
Out[18]: array([2, 0, 3])
#给数组中每个数据出现的概率赋值
In [19]: np.random.choice(5, 3, p=[0.1, 0, 0.3, 0.6, 0])
Out[19]: array([3, 3, 0], dtype=int64)
#repalce参数为是否可以重复,当设置为FALSE时,不能出现重复的数据
In [21]: np.random.choice(5, 4, replace=False)
Out[21]: array([3, 2, 1, 4])
In [22]: np.random.choice(5, 5, replace=False)
Out[22]: array([4, 0, 3, 1, 2])
In [23]: np.random.choice(5, 3, replace=False, p=[0.1, 0, 0.3, 0.6, 0])
Out[23]: array([3, 0, 2])
#也可以传入非数字、字符串的数组
In [24]: demo_list = ['lenovo', 'sansumg','moto','xiaomi', 'iphone']
In [25]: np.random.choice(demo_list,size=(3,3))
Out[25]:
array([['lenovo', 'sansumg', 'sansumg'],
['sansumg', 'iphone', 'iphone'],
['lenovo', 'lenovo', 'xiaomi']],
dtype='<U7')
5、numpy.random.seed()生成随机数的种子,使得每次生成随机数相同
np.random.seed()的作用:使得随机数据可预测。
当我们设置相同的seed,每次生成的随机数相同。如果不设置seed,则每次会生成不同的随机数
In [26]: np.random.seed(0)
...: np.random.rand(5)
...:
Out[26]: array([ 0.5488135 , 0.71518937, 0.60276338, 0.54488318, 0.4236548 ])
#不同的随机数种子下的rand生成的随机数组的值不等
In [27]: np.random.seed(1000)
...: np.random.rand(5)
...:
Out[27]: array([ 0.65358959, 0.11500694, 0.95028286, 0.4821914 , 0.87247454])
#继续输入随机种子为1000下生成的随机数组
In [29]: np.random.seed(1000)
...: np.random.rand(5)
...:
Out[29]: array([ 0.65358959, 0.11500694, 0.95028286, 0.4821914 , 0.87247454])
- **
ptsInClust = dataSet[nonzero(clusterAssment[:,0].A==cent)[0]]
出自第十章P188
**
>>> from numpy import *
>>> a = mat([[1,2,3],[4,5,6],[7,8,9]])
>>> a[:,0].A == 1
array([[ True],
[False],
[False]])
>>> a.A ==3
array([[False, False, True],
[False, False, False],
[False, False, False]])
clusterAssment[:,0].A==cent返回clusterAssment矩阵中等于cent的位置,记为Ture,其他为False
>>> nonzero(a[:,0].A == 1)
(array([0], dtype=int64), array([0], dtype=int64))
nonezero()返回满足括号内容的,即括号内容为Ture的位置信息,以两个array显示
第一个array表示行,第二个array表示列
这里就是a矩阵中为1的位置在(1,1)
ptsInClust = dataSet[nonzero(clusterAssment[:,0].A==cent)[0]]得到的就是clusterAssment矩阵中第一列为cent的位置所对应的dataSet矩阵中的数据点集合