从 机器学习面试必知:SVM和LR的关系 一文中,我们可以看到SVM相比于LR的优势在于能产生稀疏解。现在把SVM应用到回归问题中,同时保持它的稀疏性。在简单的线性回归模型中,我们最小化一个正则化的误差函数
21n=1∑N(yn−tn)2+2λ∣∣w∣∣2为了得到稀疏解,二次误差函数被替换成一个
ϵ不敏感误差函数。如果预测
y(x)与目标
t之间的差的绝对值小于
ϵ,那么这个误差函数给出的误差为0。
Eϵ(y(x)−t)={0,if ∣y(x)−t∣<ϵ∣y(x)−t∣<ϵ, otherwise于是我们最小正则化的误差函数
Cn=1∑NEϵ(y(xn)−tn)+21∣∣w∣∣2为了有更好的泛化能力,我们引入松弛变量
ξn≥0和
ξn
≥0分别代表上界和下界。
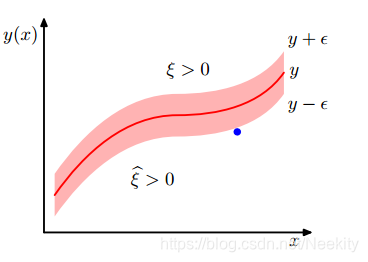
从图中可以看到,
ξn>0对应的是
tn>y(xn)+ϵ数据点,
ξn
>0对应的是
tn<y(xn)−ϵ数据点,所以
tn≤y(xn)+ϵ+ξn
tn≥y(xn)−ϵ−ξn
相应地支持向量回归的误差函数可以写成
Cn=1∑N(ξn+ξn
)+21∣∣w∣∣2我们引入拉格朗日乘数
an≥0,
an
≥0,
un≥0和
un
≥0,然后最优化拉格朗日函数
L=Cn=1∑N(ξn+ξn
)+21∣∣w∣∣2−n=1∑Nunξn−n=1∑Nun
ξn
−n=1∑Nan(y(xn)+ϵ+ξn−tn)−n=1∑Nan
(−y(xn)+ϵ+ξn
+tn)
∂w∂L=0⇒w=n=1∑N(an−an
)ϕ(xn)
∂b∂L=0⇒0=n=1∑N(an−an
)
∂ξn∂L=0⇒an+un=C
∂ξn
∂L=0⇒an
+un
=C把这些结果代入到L中得到
L
(a,a
)=−21n=1∑Nm=1∑N(an−an
)(am−am
)K(xn,xm)−ϵn=1∑N(an+an
)+n=1∑N(an−an
)tn同样地我们得到了限制条件
0≤an≤C
0≤an
≤C对应的KKT条件等于零的情况如下
an(y(xn)+ϵ+ξn−tn)=0
an
(−y(xn)+ϵ+ξn
+tn)=0
(C−an)ξn=0
(C−an
)ξn
=0分析上述的等式我们可以得到些有用的结果。如果
y(xn)+ϵ+ξn−tn=0,那么
an̸=0,进一步的,如果
an=C也就是
ξn>0此时数据点位于上边界的上方,如果
ξn=0那么数据点位于管道的上边界上。同理可以分析
−y(xn)+ϵ+ξn
+tn=0。
我们已经得到了
y(x)=n=1∑N(an−an
)K(xn,x)+b现在寻找支持向量也就是有贡献的数据点即
an̸=0或者
an
̸=0的点。这些数据点位于管道边界上或者管道外部,管道内部的点有
an=an
=0。更一般地,我们使用前文的分析用满足
0<an<C,此时
ξn=0,
y(xn)+b+ϵ+ξn−tn=0,那么
b=−wTϕ(xn)−ϵ+tn或者用
0<an
<C的数据点去求解b。当然更好的方法对所有符合条件的情况取平均。