Programming Exercise 7.1:K-means Clustering
Python版本3.6
编译环境:anaconda Jupyter Notebook
链接:实验数据和实验指导书
提取码:i7co
本章课程笔记部分见:13.聚类
在本练习中,我们将实现K-means聚类,并使用它来压缩图像。我们将实施和应用K-means到一个简单的二维数据集,以获得一些直观的工作原理。 K-means是一个迭代的,无监督的聚类算法,将类似的实例组合成簇。 该算法通过猜测每个簇的初始聚类中心开始,然后重复将实例分配给最近的簇,并重新计算该簇的聚类中心。 我们要实现的第一部分是找到数据中每个实例最接近的聚类中心的函数。
%matplotlib inline
#IPython的内置magic函数,可以省掉plt.show(),在其他IDE中是不会支持的
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
import scipy.io as sio
sns.set(style="whitegrid",color_codes=True)
2-2维kmeans
查看数据和可视化
mat = sio.loadmat('./data/ex7data2.mat')
data2 = pd.DataFrame(mat.get('X'), columns=['X1', 'X2'])
print(data2.head())
#sns.set(context="notebook", style="white")
sns.lmplot('X1', 'X2', data=data2, fit_reg=False)
X1 X2
0 1.842080 4.607572
1 5.658583 4.799964
2 6.352579 3.290854
3 2.904017 4.612204
4 3.231979 4.939894
<seaborn.axisgrid.FacetGrid at 0x31f5d26d68>

#找到聚类中心
def find_closest_centroids(X, centroids):
m = X.shape[0]
k = centroids.shape[0]
idx = np.zeros(m)
for i in range(m):
min_dist = 1000000
for j in range(k):
dist = np.sum((X[i,:] - centroids[j,:]) ** 2)
if dist < min_dist:
min_dist = dist
idx[i] = j
return idx
X = mat['X']
#让我们来测试这个函数,以确保它的工作正常。 我们将使用练习中提供的测试用例。
initial_centroids = initial_centroids = np.array([[3, 3], [6, 2], [8, 5]])
idx = find_closest_centroids(X, initial_centroids)
idx[0:3]
array([0., 2., 1.])
#初始化聚类中心
def init_centroids(X, k):
m, n = X.shape
centroids = np.zeros((k, n))
idx = np.random.randint(0, m, k)
for i in range(k):
centroids[i,:] = X[idx[i],:]
return centroids
initial_centroids = init_centroids(X, 3)
输出与文本中的预期值匹配(记住我们的数组是从零开始索引的,而不是从一开始索引的,所以值比练习中的值低一个)。 接下来,我们需要一个函数来计算簇的聚类中心。 聚类中心只是当前分配给簇的所有样本的平均值。
def compute_centroids(X, idx, k):
m, n = X.shape
centroids = np.zeros((k, n))
for i in range(k):
indices = np.where(idx == i)
centroids[i,:] = (np.sum(X[indices,:], axis=1) / len(indices[0])).ravel()
return centroids
compute_centroids(X, idx, 3)
array([[1.95399466, 5.02557006],
[3.04367119, 1.01541041],
[6.03366736, 3.00052511]])
此输出也符合练习中的预期值。
下一部分涉及实际运行该算法的一些迭代次数和可视化结果。
这个步骤是由于并不复杂,我将从头开始构建它。 为了运行算法,我们只需要在将样本分配给最近的簇并重新计算簇的聚类中心。
def run_k_means(X, initial_centroids, max_iters):
m, n = X.shape
k = initial_centroids.shape[0]
idx = np.zeros(m)
centroids = initial_centroids
for i in range(max_iters):
idx = find_closest_centroids(X, centroids)
centroids = compute_centroids(X, idx, k)
return idx, centroids
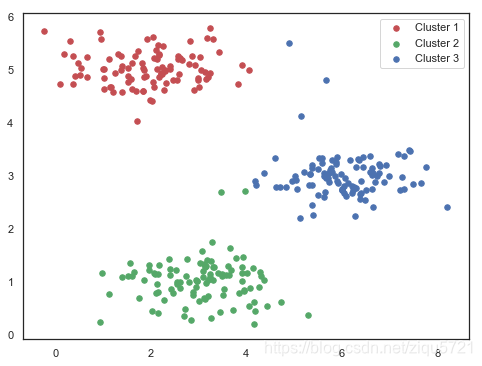
idx, centroids = run_k_means(X, initial_centroids, 10)
cluster1 = X[np.where(idx == 0)[0],:]
cluster2 = X[np.where(idx == 1)[0],:]
cluster3 = X[np.where(idx == 2)[0],:]
fig, ax = plt.subplots(figsize=(8,6))
ax.scatter(cluster1[:,0], cluster1[:,1], s=30, color='r', label='Cluster 1')
ax.scatter(cluster2[:,0], cluster2[:,1], s=30, color='g', label='Cluster 2')
ax.scatter(cluster3[:,0], cluster3[:,1], s=30, color='b', label='Cluster 3')
ax.legend()
<matplotlib.legend.Legend at 0x31f6c895f8>
3- kmeans用于图像压缩
下一个任务是将K-means应用于图像压缩。我们可以使用聚类来找到最具代表性的少数颜色,并使用聚类分配将原始的24位颜色映射到较低维的颜色空间。
from IPython.display import Image
Image(filename='data/bird_small.png')

image_data = sio.loadmat('data/bird_small.mat')
image_data
{'__header__': b'MATLAB 5.0 MAT-file, Platform: GLNXA64, Created on: Tue Jun 5 04:06:24 2012',
'__version__': '1.0',
'__globals__': [],
'A': array([[[219, 180, 103],
[230, 185, 116],
[226, 186, 110],
...,
[ 14, 15, 13],
[ 13, 15, 12],
[ 12, 14, 12]],
[[230, 193, 119],
[224, 192, 120],
[226, 192, 124],
...,
[ 16, 16, 13],
[ 14, 15, 10],
[ 11, 14, 9]],
[[228, 191, 123],
[228, 191, 121],
[220, 185, 118],
...,
[ 14, 16, 13],
[ 13, 13, 11],
[ 11, 15, 10]],
...,
[[ 15, 18, 16],
[ 18, 21, 18],
[ 18, 19, 16],
...,
[ 81, 45, 45],
[ 70, 43, 35],
[ 72, 51, 43]],
[[ 16, 17, 17],
[ 17, 18, 19],
[ 20, 19, 20],
...,
[ 80, 38, 40],
[ 68, 39, 40],
[ 59, 43, 42]],
[[ 15, 19, 19],
[ 20, 20, 18],
[ 18, 19, 17],
...,
[ 65, 43, 39],
[ 58, 37, 38],
[ 52, 39, 34]]], dtype=uint8)}
A = image_data['A']
A.shape
(128, 128, 3)
现在我们需要对数据应用一些预处理,并将其提供给K-means算法。
# normalize value ranges
A = A / 255.
# reshape the array
X = np.reshape(A, (A.shape[0] * A.shape[1], A.shape[2]))
X.shape
(16384, 3)
# randomly initialize the centroids
initial_centroids = init_centroids(X, 16)
# run the algorithm
idx, centroids = run_k_means(X, initial_centroids, 10)
# get the closest centroids one last time
idx = find_closest_centroids(X, centroids)
# map each pixel to the centroid value
X_recovered = centroids[idx.astype(int),:]
X_recovered.shape
(16384, 3)
# reshape to the original dimensions
X_recovered = np.reshape(X_recovered, (A.shape[0], A.shape[1], A.shape[2]))
X_recovered.shape
(128, 128, 3)
plt.imshow(X_recovered)
<matplotlib.image.AxesImage at 0x31f6ce49e8>
可以看到我们对图像进行了压缩,但图像的主要特征仍然存在。 这就是K-means。
我们来用scikit-learn来实现K-means。
from skimage import io
# cast to float, you need to do this otherwise the color would be weird after clustring
pic = io.imread('data/bird_small.png') / 255.
io.imshow(pic)
<matplotlib.image.AxesImage at 0x31fcde0080>

pic.shape
(128, 128, 3)
# serialize data
data = pic.reshape(128*128, 3)
data.shape
(16384, 3)
from sklearn.cluster import KMeans#导入kmeans库
model = KMeans(n_clusters=16, n_init=100, n_jobs=-1)
model.fit(data)
KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300,
n_clusters=16, n_init=100, n_jobs=-1, precompute_distances='auto',
random_state=None, tol=0.0001, verbose=0)
centroids = model.cluster_centers_
print(centroids.shape)
C = model.predict(data)
print(C.shape)
(16, 3)
(16384,)
centroids[C].shape
(16384, 3)
compressed_pic = centroids[C].reshape((128,128,3))
fig, ax = plt.subplots(1, 2)
ax[0].imshow(pic)
ax[1].imshow(compressed_pic)
<matplotlib.image.AxesImage at 0x31fd564c88>
