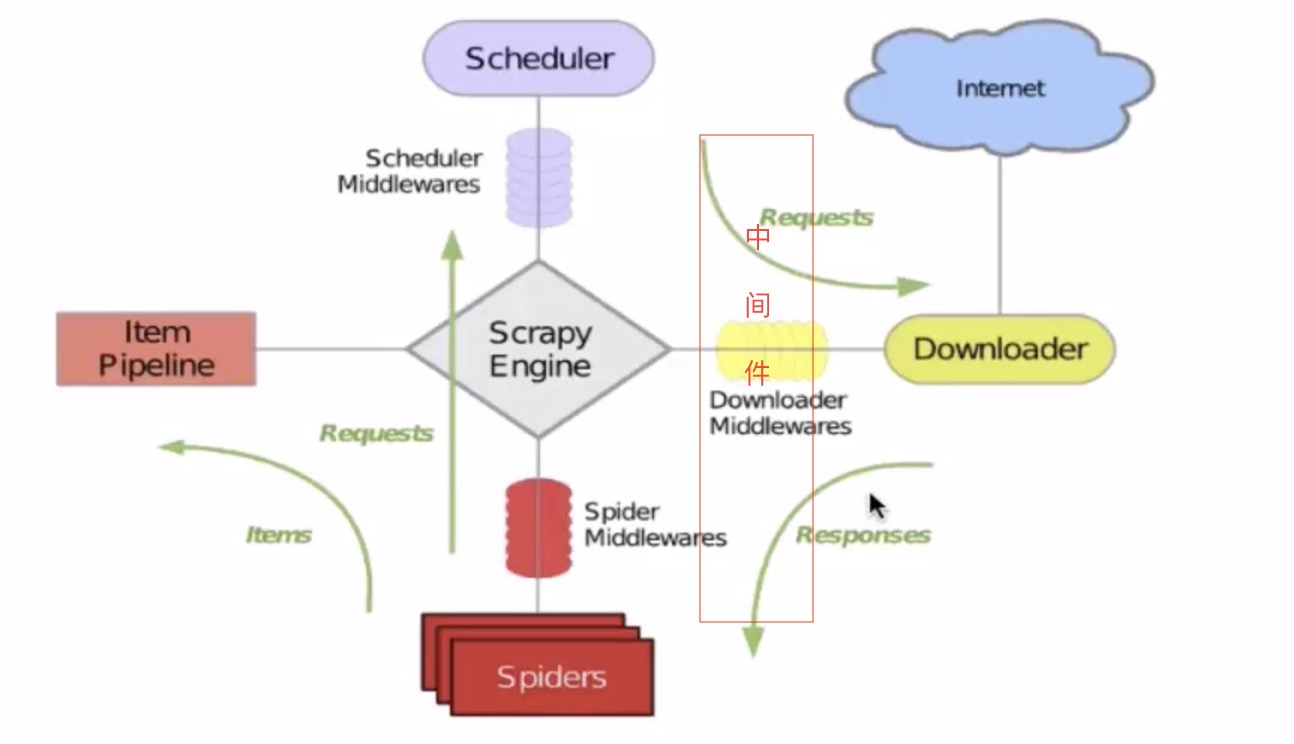
一:scrapy核心组件的介绍
1: 引擎(scrapy):负责整个系统流程的数据处理,触发事物(核心)
2:调度器(scheduler):将需要爬取页面地址,放入队列中(url会自动去重),并在引擎再次请求返回
3:下载器(downloader):用于将下载的内容,返回给蜘蛛(scrapy 建立在twisted异步模型)
4:爬虫(spider):用于数据提取(item)
5: 管道(pipelines):用于数据存储
二:代理和cookie
1:cookie操作
scrapy获取二级子页面会自动携带cookie进行请求访问。
2:scrapy发起post请求
第一种你方法:重写start_requests方法,并且将scrapy.Request方法中method属性修改成post。该方法不建议使用
# -*- coding: utf-8 -*-
import scrapy
class App01Spider(scrapy.Spider):
#爬虫文件名称 通过文件名称,定位到需要执行哪一个爬虫文件
name = 'app01'
#allowed_domains = ['www.baidu.com']# 允许的域名,只能爬去该域名下的页面数据,可注释
start_urls = ['https://fanyi.baidu.com/sug']#起始url
#重写start_requests 修改method属性为post请求
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url=url,callback=self.parse,method='post')
#解析方法,对获取的页面内容进行指定数据解析。请求一次运行一次
def parse(self, response):
print(response.text)
#爬虫文件结束后执行的方法,常常用来关闭资源文件
def closed(self):
pass
第二种方法:重写start_requests方法,使用FormRequest()方法发送post请求(建议使用)
# -*- coding: utf-8 -*-
import scrapy
#爬取百度翻译结果
class App01Spider(scrapy.Spider):
#爬虫文件名称 通过文件名称,定位到需要执行哪一个爬虫文件
name = 'app01'
#allowed_domains = ['www.baidu.com']# 允许的域名,只能爬去该域名下的页面数据,可注释
start_urls = ['https://fanyi.baidu.com/sug']#起始url
#重写start_requests 修改method属性为post请求
def start_requests(self):
data={
'kw':'man'
}
for url in self.start_urls:
yield scrapy.FormRequest(url=url,formdata=data,callback=self.parse,)
#解析方法,对获取的页面内容进行指定数据解析。请求一次运行一次
def parse(self, response):
print(response.text)
#爬虫文件结束后执行的方法,常常用来关闭资源文件
def closed(self):
pass
3:代理操作
原理:当调度器将队列中的请求提交给下载器时,会经过中间件,而中间件可以对请求进行拦截,进而修改请求.ip
步骤一:在middlewares.py文件中自定义中间类,并重写process_request()方法
class myProxy_Middleware(object): def process_request(self, request, spider): #修改ip 去面没ip地址找个ip 注意协议头 request.meta['proxy']='http://120.76.77.152:9999'
步骤二:修改settings.py文件,将编写的中间件类注册。
DOWNLOADER_MIDDLEWARES = {
'myProxy_Middleware': 543,
}
三:日志等级
error:错误
warning:警告
info:一般
debug:调试信息
setting.py 设置日志打印等级
--任意位置添加LOG_LEVEL='ERROER'
--将日志信息打印指定的文件 LOG_FILE='log.txt'
四:请求传参
--为了解决需要请求数据不在同一个页面中。通过scrapy.Request()方法中设置meta方法
--传参
yield scrapy.Request(url,callback=self.parse,meta={'item':item})
--获取
response.meta.get('item')
五:CrawlSpider
一:问题,爬取抽屉网的全部数据。
解决方法一:手动请求的发送(不方便)
解决方案二:使用CrawlSpider(建议使用),是spider的子类,具有更强大的功能(链接提取器,规则解析器,所以性能更强大)
二:创建CrawlSpider工程
1:创建工程:scrapy startproject xxxxxx
2:创建文件:scrapy genspider -t crawl file_name url
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class ChoutiSpider(CrawlSpider):
name = 'chouti'
# allowed_domains = ['www.chouti.com']
start_urls = ['https://dig.chouti.com/']
'''
1:创建链接提取器对象
--allow 提取页面url的正怎表达式
--链接提取器可以从指定页面根据正则表达式,获取提取的url
--将提取的url链接,全部发送给规则解析器
'''
link=LinkExtractor(allow=r'all/hot/recent/\d+')
'''
2:实例化一个规则解析器对象
--callback:对请求结果页面进行解析的函数回掉
--fllow: 是否将链接提取器提取到的页面,继续使用链接提取器继续提取符合规则的url
--可能会出现自动大量重复页面,但是会自动去重
'''
rules = (
Rule(link, callback='parse_item', follow=True),
)
#回调函数
def parse_item(self, response):
item = {}
print(response)
return item