此次和大家一起来学习KNN算法,将围绕以下三个方面来论述:
- 什么是KNN算法
- 算法原理
- KNN的优缺点
- 实战应用
1.认识KNN算法
K近邻算法是一种基本的分类和回归方法。在分类问题中,KNN算法假设给定的训练集的实例类别已经确定,对于新来的实例,KNN算法根据其k个最近邻的训练集实例的类别,通过多数表决等方式对新实例的类别进行预测。
2.算法原理
通用步骤
- 计算测试数据与各个训练数据之间的距离;
- 按照距离的递增关系进行排序;
- 选取距离最小的K个点;
- 确定前K个点所在类别的出现频率;
- 返回前K个点中出现频率最高的类别作为测试数据的预测分类。
一般在计算距离时,我们选用欧拉距离或者曼哈顿距离:
欧拉距离 这种测量方式就是简单的平面几何中两点之间的直线距离。
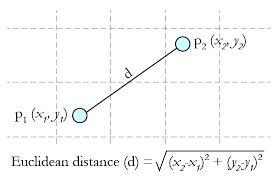
并且这种方法可以延伸至三维或更多维的情况。它的公式可以总结为:
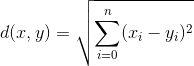
曼哈顿距离 顾名思义,城市街区的距离就不能是点和点的直线距离,而是街区的距离。如棋盘上也会使用曼哈顿距离的计算方法:
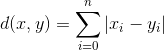
K的选取
- K太大:导致分类模糊
- K太小:受个例影响,波动较大
如何选择一个最佳的K值取决于数据。一般情况下,在分类时较大的 K 值能够减小噪声的影响,但会使类别之间的界限变得模糊。因此 K 的取值一般比较小 ( K < 20 )。
如何选取K
- 经验
- 均方根误差
3.KNN 的优缺点
优点:
- 简单,易于理解,无需建模与训练,易于实现;
- 适合对稀有事件进行分类;
- 适合与多分类问题,例如根据基因特征来判断其功能分类,kNN比SVM的表现要好。
缺点:
- 惰性算法,内存开销大,对测试样本分类时计算量大,性能较低;
- 可解释性差,无法给出决策树那样的规则。
4.实战应用
import csv
import random
#读取数据
with
open(
'Case_rate.csv',
'r')
as
file:
reader = csv.DictReader(
file)
datas=[row
for row
in reader]
for row
in reader:
print(row)
#分组 分成训练集和测试集 1/3是测试集 2/3是训练集
#大型数据中一般90%作为训练集,10%作为测试集
random.shuffle(datas)
#将整个数据集随机排序,再做切分
n=
len(datas)//
3
#x//y : 返回商的整数部分 x/y: 返回商的浮点数形式
test_set=datas[
0:n]
train_set=datas[n:]
#KNN 实际中影响最后结果的是求距离的方法,以及k的选取
#距离
#欧式距离求解
def
distance(
d1,
d2):
res=
0
for key
in (
"radius",
"texture",
"perimeter",
"area",
"smoothness",
"compactness",
"symmetry",
"fractal_dimension"):
res+=(
float(d1[key])-
float(d2[key]))**
2
return res**
0.5
K=
5
def
knn(
data):
#1.距离
res=[
{
"result": train[
'diagnosis_result'],
"distance":distance(data,train)}
for train
in train_set
]
#2.排序——升序
res=
sorted(res,
key=
lambda
item:item[
'distance'])
#3.取前K个
res2=res[
0:K]
#4.加权平均
result={
'B':
0,
'M':
0}
#总距离
sum=
0
for r
in res2:
sum+=r[
"distance"]
for r
in res2:
result[r[
'result']]+=
1-r[
'distance']/
sum
if result[
'B']>result[
'M']:
return
'B'
else:
return
'M'
#测试阶段
correct=
0
for test
in test_set:
result=test[
"diagnosis_result"]
result2=knn(test)
if result=result2:
correct+=
1
print(
"准确率:
{:.2f}
%".format(
100*correct/
len(test_set)))